Hadoop分布式集群的搭建
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop分布式集群的搭建相关的知识,希望对你有一定的参考价值。
本文由 网易云 发布。
上一篇文章介绍了如何搭建Hadoop伪分布式集群,本篇将向大家介绍下Hadoop分布式集群的搭建。内容浅显,但能够为新手们提供 一个参考,让像我一样的小白们对Hadoop的环境能够有一定的了解。
环境:
系统环境:CentOS7.3.1611 64位
Java版本:OpenJDK 1.8.0
使用两个节点作为集群环境:一个作为Master节点,另一个作为Slave节点
集群搭建流程:
Hadoop集群的安装配置主要流程如下:
(1)选定一台机器作为Master;
(2)在Master节点上配置hadoop用户、Java环境及安装SSH server;
(3)在 Master 节点上安装 Hadoop,完成配置;
(4)其余机器作为Slave节点,同理,在 Slave 节点上配置 hadoop 用户、Java环境、安装 SSH Server;
(5)将 Master 节点上的Hadoop安装目录内容复制到其他 Slave 节点上;
(6)在 Master 节点上开启 Hadoop;
以上步骤中,配置hadoop用户、Java环境,安装SSH server,安装Hadoop的步骤在《Hadoop单机/伪分布式集群搭建(新手向)》 一文中做了比较详细的介绍,大家可以参照此文中的步骤来:http://ks.netease.com/blog?id=8333。
集群所有的节点都需要位于同一个局域网,因此在完成上述步骤的前4步骤后,先进行以下的网络配置,实现节点间的互连。
网络配置
本文使用的是VMware虚拟机安装的系统,所以只需要更改网络连接方式为桥接(Bridge)模式,便能实现节点互连。如图:

配置完成后可以在各个节点上查看节点的ip,Linux中查看节点IP地址的命令为:ifconfig,如下图所示,Master节点的ip为10.240.193.67:

网络配置完成后,便可进行hadoop分布式集群的配置了。
为了能够方便的区分Master和Slave,我们可以修改节点的主机名用以区分。在CentOS7中,我们在Master节点上执行以下命令来修改 主机名:
sudo vim /etc/hostname
将主机名修改为Master:

同理,修改Slave节点的主机名为Slave。
然后,在Master和Slave节点上都执行如下命令修改IP映射,添加所有节点的IP映射:
sudo vim /etc/hosts
本文中使用的两个节点的名称与对应IP关系如下:

修改完成后需要重启节点,使得以上配置生效。可以在各个节点上ping其他节点的主机名,若能ping通说明配置成功。
SSH无密码登陆节点
分布式集群搭建需要Master节点能够无密码SSH登陆至各个Slave节点上。因此,我们需要生成Master节点的公钥,并将Master公钥 在Slave节点中加入授权。步骤如下:
(1)首先生成Master节点的公钥,执行如下命令:
cd ~/.ssh --若无该目录,先执行ssh localhost
rm ./id_rsa* --若已生成过公钥,则删除原有的公钥
ssh-keygen -t rsa --一路回车
(2)Master节点需能无密码SSH登陆本机,在Master节点上执行命令:
cat ./id_rsa.pub >> ./authorized_keys
chmod 600 ./authorized_keys
若不执行修改权限,会出现以下问题,仍无法实现无密码SSH登陆本机。

完成后,执行ssh Master验证是否可以无密码SSH登陆本机,首次登陆需要输入yes,输入exit即可退出登陆。
上述scp命令远程将Master节点的公钥拷贝至了Slave节点的/home/hadoop目录下,执行过程中会要求输入Slave节点hadoop用户的密 码,输入完成后会显示传输的进度:

(4)在Slave节点上,将Master节点的ssh公钥加入授权,执行命令:
ssh localhost --执行该命令是为了生成~/.ssh目录,或者mkdir ~/.ssh创建
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
(5)至此,已经完成 了Master节点无密码SSH登陆到Slave节点的配置。在Master节点上输入命令:ssh Slave 进行验证,登陆成功如下 图:

配置hadoop分布式环境
配置hadoop分布式环境需要修改hadoop中的五个配置文件,分别为:slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、 yarn-site.xml。具体的配置项及作用可以参考官网的说明,这里对正常启动分布式集群所必须的配置项进行配置。
1、slaves
将作为DataNode节点的主机名写入文件。该文件默认为localhost,因此伪分布配置时,节点是NameNode的同时也是 DataNode。localhost可以删除有可以保留。本文Master仅作为NameNode节点,Slave作为DataNode节点,因此删除localhost。

2、core-site.xml

3、hdfs-site.xml
由于只有一个Slave节点,所有dfs.replication的值设为1。

4、mapred-site.xml
默认文件名为mapred-site.xml.template,重命名为mapred-site.xml后,修改配置。

5、yarn-site.xml

配置完成后,将Master上的hadoop文件夹复制到Slave节点上相同路径下(/usr/local/),并修改文件夹的owner为hadoop。
接着便可启动分布式hadoop集群了,启动集群前需要先关闭集群中每个节点的防火墙,否则会引起DataNode启动了,但Live datanode为0。
启动分布式集群
首次启动需要先在Master节点执行NameNode的格式化,命令:
hdfs namenode -format
然后启动hadoop,hadoop的启动与关闭需要在Master节点上进行。
启动hadoop,执行hadoop/sbin中的启动脚本
cd /usr/local/hadoop/sbin
./start-dfs.sh
./start-yarn.sh
./mr-jobhistory-daemon.sh start historyserver

在Slave节点中可以看到NodeManager和DataNode进程,如图。

任一进程缺少都表示启动出错。同时,我们还需要在Master节点通过命令hdfs dfsadmin -report查看DataNode是否正常启动,如果 Live datanode为0,则说明启动失败。由于我们只配置了一个DataNode,所以显示Live datanode为1,如图。
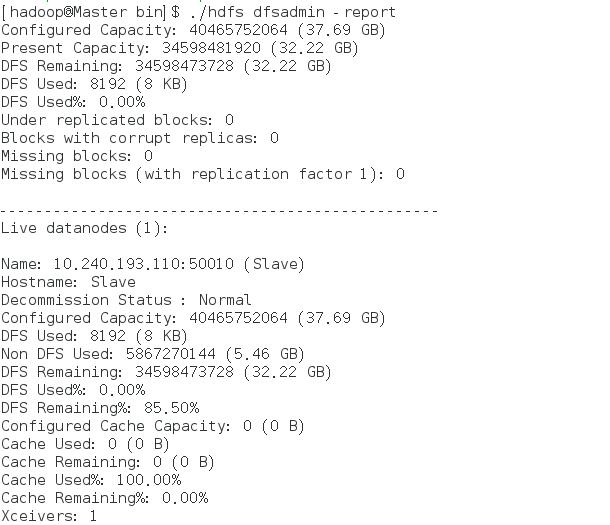
我们还可以通过web页面查看DataNode和NameNode的状态:http://master:50070。

接着我们便可以执行分布式实例了,我们启动了mr-jobhistory服务,可以通过Web页http://master:8088/cluster,点击Tracking UI 中的history查看任务运行信息。
关闭hadoop集群
在Master节点上执行脚本:
stop-yarn.sh
Stop-dfs.sh
Mr-jobhistory-daemon.sh stop historyserver
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/
以上是关于Hadoop分布式集群的搭建的主要内容,如果未能解决你的问题,请参考以下文章