Linux进程控制创建终止等待
Posted 夜 默
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux进程控制创建终止等待相关的知识,希望对你有一定的参考价值。
✨个人主页: Yohifo
🎉所属专栏: Linux学习之旅
🎊每篇一句: 图片来源
🎃操作环境: CentOS 7.6 阿里云远程服务器
- Good judgment comes from experience, and a lot of that comes from bad judgment.
- 好的判断力来自经验,其中很多来自糟糕的判断力。

文章目录
🌇前言
进程 创建后,需要对其进行合理管理,光靠 OS 是无法满足我们的需求的,此时可以运用 进程 控制相关知识,对 进程 进行手动管理,如创建 进程、终止 进制、等待 进程 等,其中等待 进程 可以有效解决僵尸 进程 问题

汽车的中控台,可以对汽车进行各种操作
🏙️正文
本文涉及的代码都是以 C语言 实现的
1、进程创建
在学习 进程控制 相关知识前,先要对回顾如何创建 进程,涉及一个重要的函数 fork
1.1、fork函数
#include <unistd.h> //所需头文件
pid_t fork(void); //fork 函数
fork 函数的作用是在当前 进程 下,创建一个 子进程,子进程 创建后,会为其分配新的内存块和内核数据结构(PCB),将 父进程 中的数据结构内容拷贝给 子进程,同时还会继承 父进程 中的环境变量表
- 进程具有独立性,即使是父子进程,也是两个完全不同的进程,拥有各自的
PCB - 假设
子进程发生改写行为,会触发写时拷贝机制
fork 函数返回类型为 pid_t,相当于 typedef int,不过是专门用于进程的,同时它拥有两个返回值:
- 如果进程创建失败,返回
-1 - 进程创建成功后
- 给子进程返回
0 - 给父进程返回子进程的
PID值
- 给子进程返回

通过代码理解 进程 创建
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h> //进程等待相关函数头文件
int main()
//创建两个子进程
pid_t id1 = fork();
if(id1 == 0)
//子进程创建成功,创建孙子进程
pid_t id2 = fork();
if(id2 == 0)
printf("我是孙子进程,PID:%d PPID:%d\\n", getpid(), getppid());
exit(1); //孙子进程运行结束后,退出
wait(0); //等待孙子进程运行结束
printf("我是子进程,PID:%d PPID:%d\\n", getpid(), getppid());
exit(1); //子进程运行结束后,退出
wait(0); //等待子进程运行结束
printf("我是父进程,PID:%d PPID:%d\\n", getpid(), getppid());
return 0; //父进程运行结束后,退出

观察结果不难发现,两个子进程已经成功创建,但最晚创建的进程,总是最先运行,这是因为 fork 创建进程后,先执行哪个进程取决于调度器
得到子进程后,此时可以在一个程序中同时执行两个进程!(父进程非阻塞的情况下)
注意:fork 可能创建进程失败
- 系统中的进程过多时
- 实际用户的进程数超过了限制
1.2、写时拷贝
在【进程地址空间】一文中,谈到了写时拷贝机制,实现原理就是通过 页表+MMU 机制,对不同的进程进行空间寻址,达到出现改写行为时,父子进程使用不同真实空间的效果
验证写时拷贝现象很简单,创建子进程后,使其对生命周期长的变量作出修改,再观察父子进程的结果即可
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h> //进程等待相关函数头文件
const char* ps = "This is an Apple"; //全局属性
int main()
pid_t id = fork();
if(id == 0)
ps = "This is a Banana"; //改写
printf("我是子进程,我认为:%s\\n", ps);
exit(0); //子进程退出
wait(0); //等待子进程退出
printf("我是父进程,我认为:%s\\n", ps);
return 0;

不难发现,子进程对指针 ps 指向内容做出改变时,父进程并不受影响,这就是写时拷贝机制
- 通过地址打印,发现父子进程中的
ps地址一致,因为此时是虚拟地址 - 在虚拟地址相同的情况下,真实地址是不同的,得益于
页表+MMU机制寻址不同的空间
写时拷贝机制本质上是一种按需申请资源的策略

注意:
- 写时拷贝不止可以发生在常规栈区、堆区,还能发生在只读的数据段和数据段
- 写时拷贝后,生成的是副本,不会对原数据造成影响
2、进程终止
假设某个进程陷入了死循环状态,可以通过特定方法终止此程序,如在命令行中莫名其妙输入了一个指令,导致出现非正常情况,可以通过 ctrl + c 终止当前进程;对于自己写的程序,有多种终止方法,程序退出时,还会有一个退出码,供 父进程 接收

2.1、退出码
echo $?
main 函数中的最后一条语句 return 0 表示当前程序的退出码,0 表示程序正常退出,可以通过指令 echo $? 查看最近一次子进程运行的 退出码
退出码是给父进程看的,可以判断子进程是否成功运行
子进程运行情况:
- 运行失败或异常终止,此时出现终止信号,无退出码
- 运行成功,返回退出码,可能出现结果错误的情况

进程退出后,OS 会释放对应的 内核数据结构+代码和数据
main 函数退出,表示整个程序退出,而程序中的函数退出,仅表示该函数运行结束
2.2、退出方式
对一个正在运行中的进程,存在两种终止方式:外部终止和内部终止,外部终止时,通过 kill -9 PID 指令,强行终止正在运行中的程序,或者通过 ctrl + c 终止前台运行中的程序

内部终止是通过函数 exit() 或 _exit() 实现的
之前在程序编写时,发生错误行为时,可以通过 exit(-1) 的方式结束程序运行,代码中任意地方调用此函数,都可以提前终止程序
void exit(int status);
void _exit(int status);
这两个退出函数,从本质上来说,没有区别,都是退出进程,但在实际使用时,还是存在一些区别,推荐使用 exit()
比如在下面这段程序中,分别使用 exit() 和 _exit() 观察运行结果
int main()
printf("You can see me");
//exit(-1); //退出程序
//_exit(-1); //第二个函数
return 0;
使用 exit() 时,输出语句

使用 _exit() 时,并没有任何语句输出

原因:
exit()是对_exit()做的封装实现_exit()就只是单纯的退出程序- 而
exit()在退出之前还会做一些事,比如冲刷缓冲区,再调用_exit() - 程序中输出语句位于输出缓冲区,不冲刷的话,是不会输出内容的

3、进程等待
僵尸进程 是一个比较麻烦的问题,如果不对其做出处理,僵尸进程 就会越来越多,导致 内存泄漏 和 标识符 占用问题

3.1、等待原因
子进程运行结束后,父进程没有等待并接收其退出码和退出状态,OS 无法释放对应的 内核数据结构+代码和数据,出现 僵尸进程
为了避免这种情况的出现,父进程可以通过函数等待子进程运行结束,此时父进程属于阻塞状态
注意:
- 进程的退出状态是必要的
- 进程的执行结果是非必要的
也就是说,父进程必须对子进程负责,确保子进程不会连累 OS,而子进程执行的结果是否正确,需要我们自行判断
3.2、等待函数
系统提供的父进程等待函数有两个 wait() 和 waitpid(),后者比较常用
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int* status);
pid_t waitpid(pid_t pid, int* status, int options);
wait() 函数前面已经演示过了,这里着重介绍 waitpid() 返回值及其参数
wait() 中的返回值和参数,包含在 waitpid() 中
返回值:
- 等待成功时,返回
>0的值 - 等待失败时,返回
-1 - 等待中,返回
0
参数列表:
pid表示所等子进程的PIDstatus表示状态,为整型,其中高16位不管,低16位中,次低8位表示退出码,第7位表示code dump,低7位表示终止信号options为选项,比如可以选择父进程是否需要阻塞等待子进程退出
需要特别注意 status

通过代码演示 waitpid() 的使用
int main()
//演示 waitpid()
pid_t id = fork(); //创建子进程
if(id == 0)
int time = 5;
int n = 0;
while(n < time)
printf("我是子进程,我已经运行了:%d秒 PID:%d PPID:%d\\n", n + 1, getpid(), getppid());
sleep(1);
n++;
exit(244); //子进程退出
int status = 0; //状态
pid_t ret = waitpid(id, &status, 0); //参数3 为0,为默认选项
if(ret == -1)
printf("进程等待失败!进程不存在!\\n");
else if(ret == 0)
printf("子进程还在运行中!\\n");
else
printf("进程等待成功,子进程已被回收\\n");
printf("我是父进程, PID:%d PPID:%d\\n", getpid(), getppid());
//通过 status 判断子进程运行情况
if((status & 0x7F))
printf("子进程异常退出,code dump:%d 退出信号:%d\\n", (status >> 7) & 1, (status & 0x7F));
else
printf("子进程正常退出,退出码:%d\\n", (status >> 8) & 0xFF);
return 0;
不发出终止信号,让程序自然跑完

发出终止信号,强行终止进程

waitpid() 的返回值可以帮助我们判断此时进程属于什么状态(在下一份测试代码中表现更明显),而 status 的不同部分,可以帮助我们判断子进程因何而终止,并获取 退出码(终止信号)
在进程的
PCB中,包含了int _exit_code和int _exit_signal这两个信息,可以通过对status的位操作间接获取其中的值
注意:
status的位操作需要多画图理解- 正常退出时,终止信号为0;异常终止时,退出码没有,两者是互斥的
code dump现阶段用不到,但它是伴随着终止信号出现的
如果觉得 (status >> 8) & 0xFF 和 (status & 0x7F) 这两个位运算难记,系统还提供了两个宏来简化代码
WIFEXITED(status)判断进程退出情况,当宏为真时,表示进程正常退出WEXITSTATUS(status)相当于(status >> 8) & 0xFF,直接获取退出码
3.3、等待时执行
//options 参数
WNOHANG
//比如
waitpid(id, &status, WNOHANG);
父进程并非需要一直等待子进程运行结束(阻塞等待),可以通过设置 options 参数,进程解除 夯 状态,父进程变成 等待轮询 状态,不断获取子进程状态(是否退出),如果没退出,就可以干点其他事
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h> //进程等待相关函数头文件
int main()
//演示 waitpid()
pid_t id = fork(); //创建子进程
if(id == 0)
int time = 9;
int n = 0;
while(n < time)
printf("我是子进程,我已经运行了:%d秒 PID:%d PPID:%d\\n", n + 1, getpid(), getppid());
sleep(1);
n++;
exit(244); //子进程退出
int status = 0; //状态
pid_t ret = 0;
while(1)
ret = waitpid(id, &status, WNOHANG); //参数3 设置为非阻塞状态
if(ret == -1)
printf("进程等待失败!进程不存在!\\n");
break;
else if(ret == 0)
printf("子进程还在运行中!\\n");
printf("我可以干一些其他任务\\n");
sleep(3);
else
printf("进程等待成功,子进程已被回收\\n");
//通过 status 判断子进程运行情况
if(WIFEXITED(status))
printf("子进程正常退出,退出码:%d\\n", WEXITSTATUS(status));
break;
else
printf("子进程异常退出,code dump:%d 退出信号:%d\\n", (status >> 7) & 1, (status & 0x7F));
break;
return 0;
程序正常运行,父进程通过 等待轮询 的方式,在子进程执行的同时,执行其他任务

当然也可以通过 kill -9 PID 命令使子进程异常终止

可以看到程序能分别捕捉到正常和异常的情况
注意: 如果不写进程等待函数,会引发僵尸进程问题
🌆总结
以上就是关于 Linux进程控制(创建、终止、等待) 的相关知识了,我们学习了 子进程 是如何被创建的,创建后又是如何终止的,以及 子进程 终止 父进程 需要做些什么,有了这些知识后,在对 进程 进行操作时能更加灵活和全面
如果你觉得本文写的还不错的话,期待留下一个小小的赞👍,你的支持是我分享的最大动力!
如果本文有不足或错误的地方,随时欢迎指出,我会在第一时间改正

相关文章推荐
Linux进程学习【进程地址】
Linux进程学习【环境变量】
Linux进程学习【进程状态】
Linux进程学习【基本认知】
===============
Linux工具学习之【gdb】
Linux工具学习之【git】
Linux工具学习之【gcc/g++】
Linux工具学习之【vim】

Linux——进程控制(创建终止等待程序替换)
Linux——进程控制
写时拷贝
进程的创建:
pit_t fork(void)
写时拷贝机制:
代码共享、数据独有
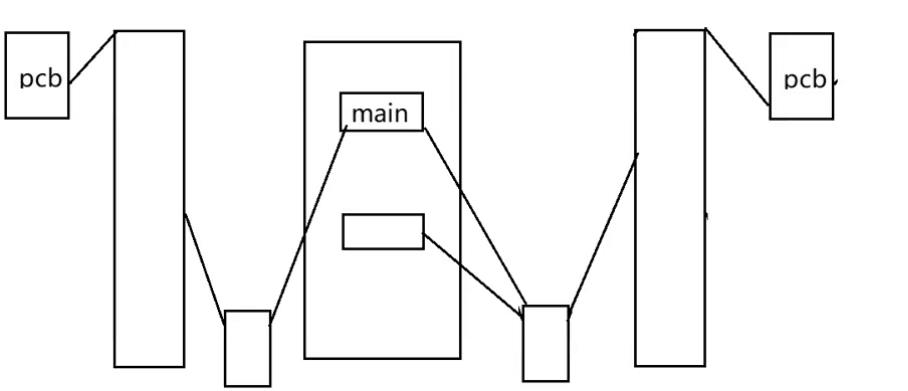
子进程创建后,给子进程重新开辟,把父进程的那些数据拷贝过来,这样才能保持独立,各有各的空间,但是如果子进程中根本就不访问这些数据,则空间开辟以及数据拷贝白费了,浪费了时间,浪费了内存。
为了独立,又为了提高效率,避免资源浪费,因此采用了写时拷贝技术:
思想:子进程创建流程:刚创建出来的时候,让子进程与父进程一样,映射一块物理内存,但是如果某块内存中的数据即将发生概念(任意一方要修改),则给子进程针对这一块重新开辟空间,拷贝数据过去。
进程终止
man手册:-1:命令,-2:系统调用接口,-3:库函数接口
进程终止:如何退出一个进程
1.在main函数中return (return只有在main函数中才是退出程序的运行)
2.库函数:void exit(int retval),可以在任意位置调用退出程序的运行
3.系统调用接口:void_exit(int status);可以在任意位置调用,退出程序的运行
库函数与系统调用接口的关系:库函数封装了系统调用
问题:exit与_exit的区别?
每次打印都要操作设备,如果有大量的小数据要打印或写入文件意味着每次写入都有操作,导致效率很低。
因此引入 :“缓冲区”——作为中间的数据缓冲,可以将多次小数据积累成一个大数据一次性操作完成。标准的输出设备有一个特性:换行刷新缓冲区
因此库函数exit与系统调用_exit的区别在于:退出程序前是否会刷新缓冲区
exit与return在退出程序前都会刷新缓冲区,将还没有写入文件的数据写入到文件中,而_exit调用直接退出,不会刷新缓冲区,而是直接释放资源(有可能存在缓冲区中的数据丢失)
return后边的数字和exit的参数status的作用:设置进程的退出码
退出码只保留低八位(进程退出码尽量保持在0-255之间)
进程等待
进程等待:等待子进程等待,获取子进程退出码,释放子进程资源,避免子进程成为僵尸进程。
僵尸进程:子进程先于父进程退出,为了保存退出码,没有完全释放资源。
虽然不关心子进程的退出码,但是依然需要进行进程等待,因为要避免这个子进程成为僵尸进程。
那么如何进行进程等待?
int wait ( int * status);
功能:阻塞等待 任意一个 子进程的退出。
就意味着当前有子进程且都没有退出就会阻塞进程一直等待
阻塞等待:为了完成一个功能发起了一个调用,功能不能完成则一直等待
参数:int *status ——一个int整形空间地址,用于存放退出码
返回值:成功则返回处理的后的子进程的pid,失败则返回 -1(比如没有子进程);
int waitpid (pid_t pid, int *status,int option);
功能:等待指定的子进程,以及可以进行非阻塞等待;
参数:pid_t pid 用于指定等待的子进程pid,如果为-1则表示等待任意一个子进程。
int *status 整形空间地址用于获取退出码
option:设置阻塞标志0 - 表示阻塞等待
返回值:大于零表示处理的退出子进程pid,等于0表示当前没有子进程退出(非阻塞,小于零表示出错了);
非阻塞等待:当完成了一个功能,我们发起了一个调用,如果功能不能立即完成则接口立即报错返回。
进程等待操作(wait操作):

waitpid操作:

非阻塞的用法 :需要循环操作进行,不循环的话有可能这个操作根本就没有进行,如下:

但是如果在上述所说的1s之内就退出了子进程就退出了,那这1s秒钟没处理的时候就是僵尸进程。
./main之后:

问题:在进程等待之前,已经退出的子进程怎么办?
wait/waitpid并不是只处理刚退出的子进程,而是只要存在子进程退出,有已经成为僵尸进程的就直接处理返回。
退出码的获取
status在低16位里的高8位是退出码的位置,低7位的位置就是异常信号值,core dump标志;

进程的退出场景:
正常退出 —— return / exit / _exit退出
异常退出 —— 没有运行到正常退出位置中途崩溃了
core dump:核心转储,表示程序异常退出前将自己运行信息保存起来,便于调试
只有程序正常退出,那么进程的退出码获取才有意义;
因此在获取退出码之前,首先应该判断以下程序是否正常退出;
**程序崩溃的本质:**程序运行中发生的异常,都是内核检测到的,当程序异常时候,则系统检测后给进程会发送一个异常信号,表示一个异常事件。
获取异常退出信号值(异常信号=0就表示正常,否则不正常):status &0×7f (与低7位相与操作)
(status >>8)& 0×ff —— 获取退出码
示例:

获取到了退出码:99

程序替换
程序替换:替换一个正在调度管理的程序
通常很少替换当前调度程序,而是创建子进程之后,替换子进程所运行的程序。
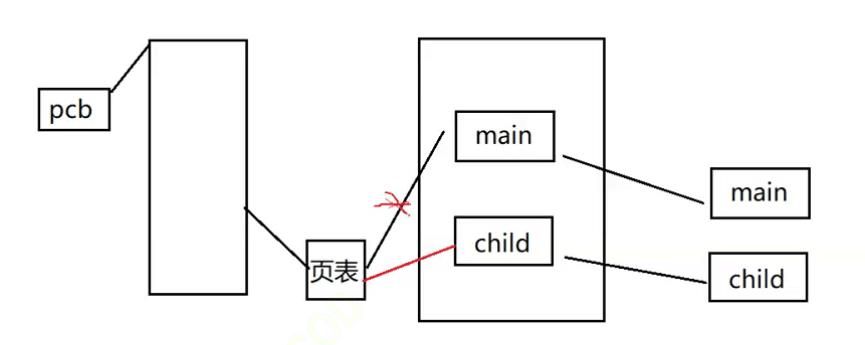
fork之后子进程与父进程干的事情相同,可以分摊压力,还有一种就是让子进程干其他事情,干活逻辑都是在if(fork == 0)这个判断中去完成,会导致代码庞大,不灵活。
因此创建子进程之后,根据不同工作任务,将子进程替换成不同程序,则代码模块可以灵活很多。
例如网络服务器:主程序逻辑一致 - 有请求来了,创建进程,根据不同的处理程序即可。
程序替换操作接口:
extern char **environ ; 这是一个全局变量的声明,这个全局变量保存了所有的环境变量。
int execve (char *pathname , char *argv[] , char *env[])
pathname:要替换的新程序的路径名
argv:传递给新的程序的运行参数
env:传递给新的程序的环境变量
返回值:失败返回 -1 ,成功返回0;

shell中会涉及程序运行环境的配置,我们的程序主要是传递数据,环境变量具有进程传递特性,可以通过环境变量给进程传递一些数据。
程序替换函数如果替换成功的话,则这个函数调用之后的代码就不会被执行,因为程序已经被替换成新的程序,而新的程序运行完毕之后,进程就退出了(不会返回回来运行原先的程序)。

替换进程之后,进程ID不变,PCB也不变。
这是一些execve函数的变形,根据具体需要进行查询即可。

以上是关于Linux进程控制创建终止等待的主要内容,如果未能解决你的问题,请参考以下文章
Linux进程控制进程创建 | 进程终止 | 进程等待 | 进程替换