大数据入门第十三天——离线综合案例:网站点击流数据分析
Posted ---江北
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据入门第十三天——离线综合案例:网站点击流数据分析相关的知识,希望对你有一定的参考价值。
推荐书籍:《网站分析实战——如何以数据驱动决策,提升网站价值》
相关随笔:http://blog.csdn.net/u014033218/article/details/76847263
一、网站点击流数据分析项目业务背景
1.什么是点击流数据
1.web访问日志
即指用户访问网站时的所有访问、浏览、点击行为数据。比如点击了哪一个链接,在哪个网页停留时间最多,采用了哪个搜索项、总体浏览时间等。
而所有这些信息都可被保存在网站日志中。通过分析这些数据,可以获知许多对网站运营至关重要的信息。采集的数据越全面,分析就能越精准。
日志的生成渠道:
1)是网站的web服务器所记录的web访问日志;
2)是通过在页面嵌入自定义的js代码来获取用户的所有访问行为(比如鼠标悬停的位置,点击的页面组件等),
然后通过ajax请求到后台记录日志;这种方式所能采集的信息最全面;
3)通过在页面上埋点1像素的图片,将相关页面访问信息请求到后台记录日志;
日志数据内容详述:
在实际操作中,有以下几个方面的数据可以被采集:
1)访客的系统属性特征。比如所采用的操作系统、浏览器、域名和访问速度等。
2)访问特征。包括停留时间、点击的URL等。
3)来源特征。包括网络内容信息类型、内容分类和来访URL等。
产品特征。包括所访问的产品编号、产品类别、产品颜色、产品价格、产品利润、
日志示例:
GET /log.gif?t=item.010001&m=UA-J2011-1&pin=-&uid=1679790178&sid=1679790178|12&v=je=1$sc=24-bit$sr=1600x900$ul=zh-cn$cs=GBK$dt=【云南白药套装】云南白药 牙膏 180g×3 (留兰香型)【行情 报价 价格 评测】-京东$hn=item.jd.com$fl=16.0 r0$os=win$br=chrome$bv=39.0.2171.95$wb=1437269412$xb=1449548587$yb=1456186252$zb=12$cb=4$usc=direct$ucp=-$umd=none$uct=-$ct=1456186505411$lt=0$tad=-$sku=1326523$cid1=1316$cid2=1384$cid3=1405$brand=20583$pinid=-&ref=&rm=1456186505411 HTTP/1.1
2.点击流数据模型
点击流概念
点击流这个概念更注重用户浏览网站的整个流程,网站日志中记录的用户点击就像是图上的“点”,而点击流更像是将这些“点”串起来形成的“线”。也可以把“点”认为是网站的Page,而“线”则是访问网站的Session。所以点击流数据是由网站日志中整理得到的,它可以比网站日志包含更多的信息,从而使基于点击流数据统计得到的结果更加丰富和高效。
点击流模型生成
点击流数据在具体操作上是由散点状的点击日志数据梳理所得,从而,点击数据在数据建模时应该存在两张模型表(Pageviews和visits):
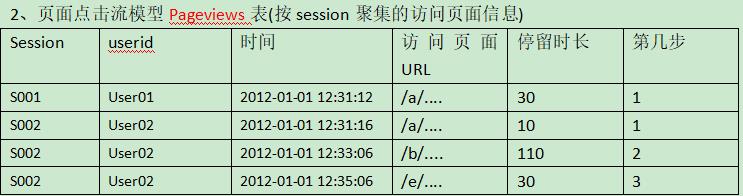
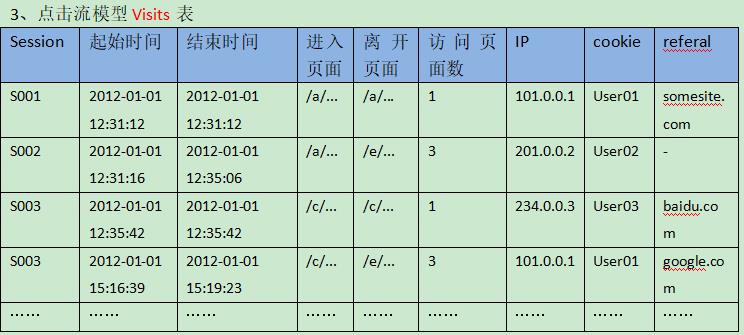
2.点击流数据分析意义
参见文首链接
3.流量分析常见指标
1)基础分析(PV,IP,UV)
2)来源分析
3)受访分析
4)访客分析
5)转化路径分析
//完整指标参考文首链接
二、整体技术流程及架构
1.处理流程
该项目是一个纯粹的数据分析项目,其整体流程基本上就是依据数据的处理流程进行,依此有以下几个大的步骤:
1) 数据采集
首先,通过页面嵌入JS代码的方式获取用户访问行为,并发送到web服务的后台记录日志
然后,将各服务器上生成的点击流日志通过实时或批量的方式汇聚到HDFS文件系统中
当然,一个综合分析系统,数据源可能不仅包含点击流数据,还有数据库中的业务数据(如用户信息、商品信息、订单信息等)及对分析有益的外部数据。
2) 数据预处理
通过mapreduce程序对采集到的点击流数据进行预处理,比如清洗,格式整理,滤除脏数据等
3) 数据入库
将预处理之后的数据导入到HIVE仓库中相应的库和表中
4) 数据分析
项目的核心内容,即根据需求开发ETL分析语句,得出各种统计结果
5) 数据展现
将分析所得数据进行可视化
2.项目结构
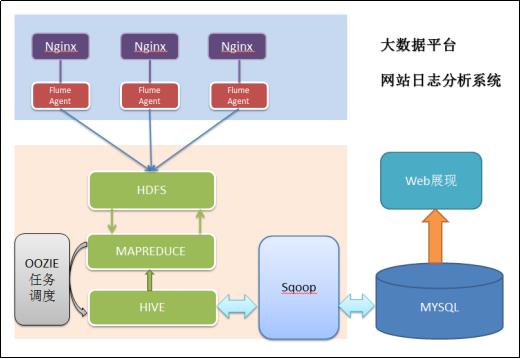
三、模块开发——数据采集
数据采集的需求广义上来说分为两大部分。
1)是在页面采集用户的访问行为,具体开发工作:
1、开发页面埋点js,采集用户访问行为
2、后台接受页面js请求记录日志
此部分工作也可以归属为“数据源”,其开发工作通常由web开发团队负责
2)是从web服务器上汇聚日志到HDFS,是数据分析系统的数据采集,此部分工作由数据分析平台建设团队负责,具体的技术实现有很多方式:
² Shell脚本
优点:轻量级,开发简单
缺点:对日志采集过程中的容错处理不便控制
² Java采集程序
优点:可对采集过程实现精细控制
缺点:开发工作量大
² Flume日志采集框架
成熟的开源日志采集系统,且本身就是hadoop生态体系中的一员,与hadoop体系中的各种框架组件具有天生的亲和力,可扩展性强
数据采集技术选型
flume
采集规则:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure spooldir source1
#agent1.sources.source1.type = spooldir
#agent1.sources.source1.spoolDir = /var/logs/nginx/
#agent1.sources.source1.fileHeader = false
# Describe/configure tail -F source1
#使用exec作为数据源source组件
agent1.sources.source1.type = exec
#使用tail -F命令实时收集新产生的日志数据
agent1.sources.source1.command = tail -F /var/logs/nginx/access_log
agent1.sources.source1.channels = channel1
#configure host for source
#配置一个拦截器插件
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
#使用拦截器插件获取agent所在服务器的主机名
agent1.sources.source1.interceptors.i1.hostHeader = hostname
#配置sink组件为hdfs
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
#agent1.sinks.sink1.hdfs.path=hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H%M%S
#指定文件sink到hdfs上的路径
agent1.sinks.sink1.hdfs.path=
hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M_%hostname
#指定文件名前缀
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
#指定每批下沉数据的记录条数
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
#指定下沉文件按1G大小滚动
agent1.sinks.sink1.hdfs.rollSize = 1024*1024*1024
#指定下沉文件按1000000条数滚动
agent1.sinks.sink1.hdfs.rollCount = 1000000
#指定下沉文件按30分钟滚动
agent1.sinks.sink1.hdfs.rollInterval = 30
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
#使用memory类型channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
//实际进行适当调整
调整启动命令,启动即可:
在部署了flume的nginx服务器上,启动flume的agent,命令如下:
bin/flume-ng agent --conf ./conf -f ./conf/weblog.properties.2 -n agent
//正确匹配配置文件名称与agent名称等.
四、模块开发之数据预处理
过滤“不合规”数据
格式转换和规整
根据后续的统计需求,过滤分离出各种不同主题(不同栏目path)的基础数据
核心mapreduce代码:


package cn.itcast.bigdata.hive.mr.pre; import java.io.IOException; import java.util.HashSet; import java.util.Set; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import cn.itcast.bigdata.hive.mrbean.WebLogBean; import cn.itcast.bigdata.hive.mrbean.WebLogParser; /** * 处理原始日志,过滤出真实pv请求 * 转换时间格式 * 对缺失字段填充默认值 * 对记录标记valid和invalid * * @author * */ public class WeblogPreProcess { static class WeblogPreProcessMapper extends Mapper<LongWritable, Text, Text, NullWritable> { //用来存储网站url分类数据 Set<String> pages = new HashSet<String>(); Text k = new Text(); NullWritable v = NullWritable.get(); /** * 从外部加载网站url分类数据 */ @Override protected void setup(Context context) throws IOException, InterruptedException { pages.add("/about"); pages.add("/black-ip-list/"); pages.add("/cassandra-clustor/"); pages.add("/finance-rhive-repurchase/"); pages.add("/hadoop-family-roadmap/"); pages.add("/hadoop-hive-intro/"); pages.add("/hadoop-zookeeper-intro/"); pages.add("/hadoop-mahout-roadmap/"); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); WebLogBean webLogBean = WebLogParser.parser(line); // 过滤js/图片/css等静态资源 WebLogParser.filtStaticResource(webLogBean, pages); /* if (!webLogBean.isValid()) return; */ k.set(webLogBean.toString()); context.write(k, v); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(WeblogPreProcess.class); job.setMapperClass(WeblogPreProcessMapper.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // FileInputFormat.setInputPaths(job, new Path(args[0])); // FileOutputFormat.setOutputPath(job, new Path(args[1])); FileInputFormat.setInputPaths(job, new Path("c:/weblog/input")); FileOutputFormat.setOutputPath(job, new Path("c:/weblog/output")); job.setNumReduceTasks(0); job.waitForCompletion(true); } }
运行mr进行过滤处理:
hadoop jar weblog.jar cn.itcast.bigdata.hive.mr.WeblogPreProcess /weblog/input /weblog/preout
###剩余模块,待补充,暂时参考文首博文
以上是关于大数据入门第十三天——离线综合案例:网站点击流数据分析的主要内容,如果未能解决你的问题,请参考以下文章
大数据入门第一课 Hadoop基础知识与电商网站日志数据分析