离线数据分析流程及推荐系统架构图
Posted ahu-lichang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了离线数据分析流程及推荐系统架构图相关的知识,希望对你有一定的参考价值。
1、离线数据分析流程
一个应用广泛的数据分析系统:“web日志数据挖掘”
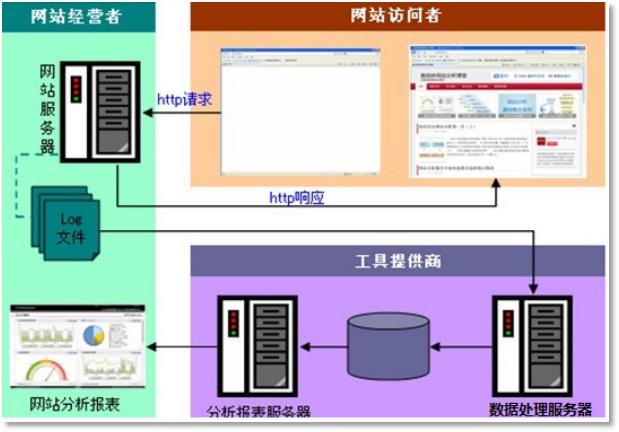
1.1 需求分析
1.1.1 案例名称
“网站或APP点击流日志数据挖掘系统”。
1.1.2 案例需求描述
“Web点击流日志”包含着网站运营很重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值,广告转化率、访客的来源信息,访客的终端信息等。
1.1.3 数据来源
本案例的数据主要由用户的点击行为记录
获取方式:在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件。
形如:
|
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0" |
1.2 数据处理流程
1.2.1 流程图解析
本案例跟典型的BI系统极其类似,整体流程如下:
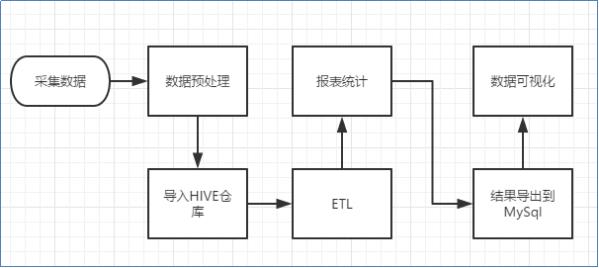
但是,由于本案例的前提是处理海量数据,因而,流程中各环节所使用的技术则跟传统BI(商业智能)完全不同,后续课程都会:
1) 数据采集:定制开发采集程序,或使用开源框架FLUME
2) 数据预处理:定制开发mapreduce程序运行于hadoop集群
3) 数据仓库技术:基于hadoop之上的Hive
4) 数据导出:基于hadoop的sqoop数据导入导出工具
5) 数据可视化:定制开发web程序或使用kettle等产品(echarts)
6) 整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
1.2.2 项目技术架构图
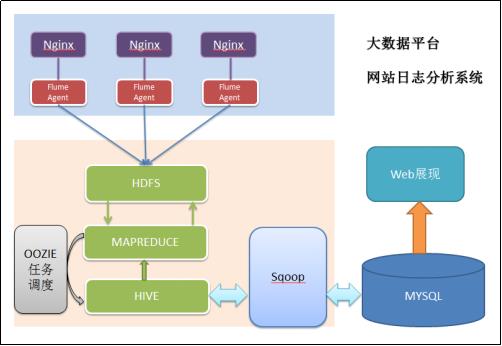
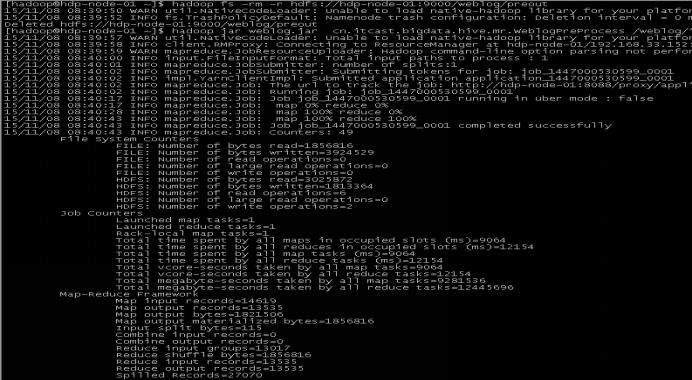
1.2.3 项目相关截图(感性认识)
a) Mapreudce程序运行
a) 在Hive中查询数据
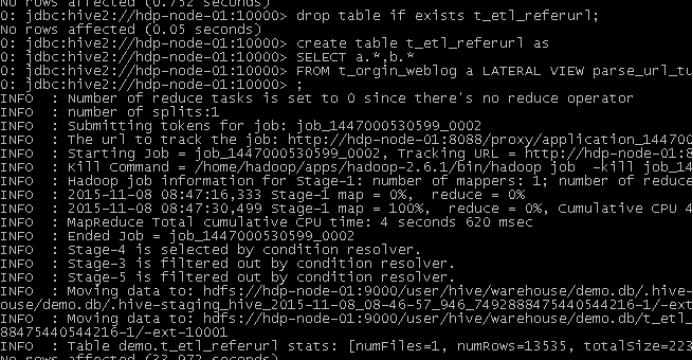
a) 将统计结果导入mysql
|
./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-03 |
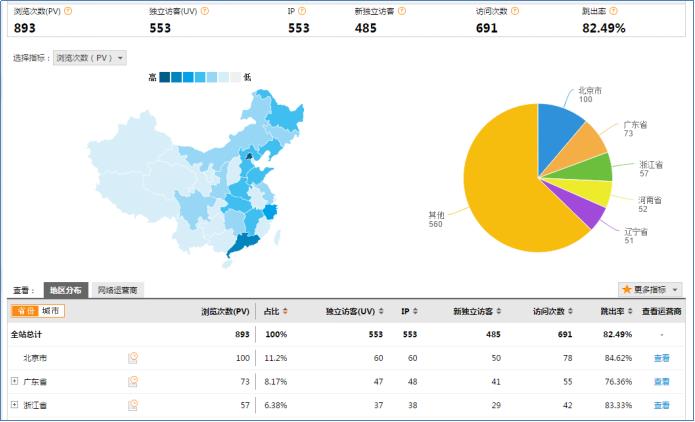
1.3 项目最终效果
经过完整的数据处理流程后,会周期性输出各类统计指标的报表,在生产实践中,最终需要将这些报表数据以可视化的形式展现出来,本案例采用web程序来实现数据可视化
效果如下所示:
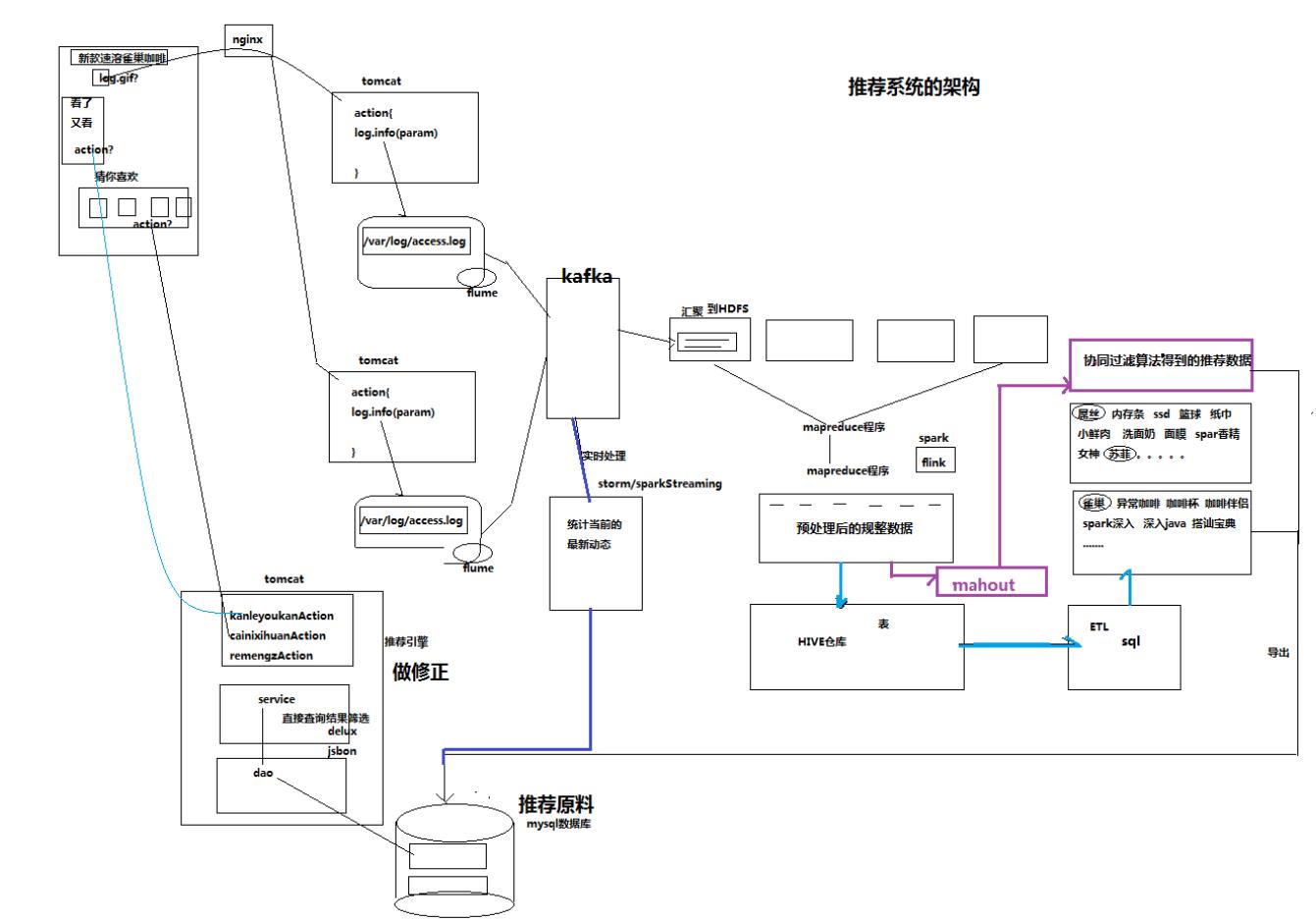
2、推荐系统架构图
以上是关于离线数据分析流程及推荐系统架构图的主要内容,如果未能解决你的问题,请参考以下文章