深入研究Spark SQL的Catalyst优化器(原创翻译)
Posted 石山园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入研究Spark SQL的Catalyst优化器(原创翻译)相关的知识,希望对你有一定的参考价值。
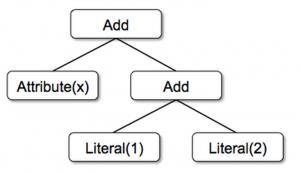
树
- Literal(值:Int):常数值
- Attribute(名称:String):输入行的属性,例如“x”
- Add(左:TreeNode,右:TreeNode):两个表达式的总和。
1 Add(Attribute(x), Add(Literal(1), Literal(2)))
规则
1 tree.transform { 2 case Add(Literal(c1), Literal(c2)) => Literal(c1+c2) 3 }
将此应用于x +(1 + 2)的树会产生新的树x + 3。这里关键是使用了Scala的标准模式匹配语法,它可用于匹配对象的类型和为提取的值(这里为c1和c2)提供名称。
1 tree.transform { 2 case Add(Literal(c1), Literal(c2)) => Literal(c1+c2) 3 case Add(left, Literal(0)) => left 4 case Add(Literal(0), right) => right 5 }
实际上,规则可能需要多次执行才能完全转换树。Catalyst将规则形成批处理,并执行每个批处理至固定点,该固定点是树应用其规则后不发生改变。虽然规则运行到固定点意味着每个规则是简单且自包含,但这些规则仍会对树上产生较大的全局效果。在上面的例子中,重复的应用规则会持续折叠较大的树,比如(x + 0)+(3 + 3)。另一个例子,第一个批处理可以分析所有属性指定类型的表达式,而第二批处理可使用这些类型来进行常量折叠。在每批处理完毕后,开发人员还可以对新树进行规范性检查(例如,查看所有属性为指定类型),这些检查一般使用递归匹配来编写。
在Spark SQL中使用Catalyst
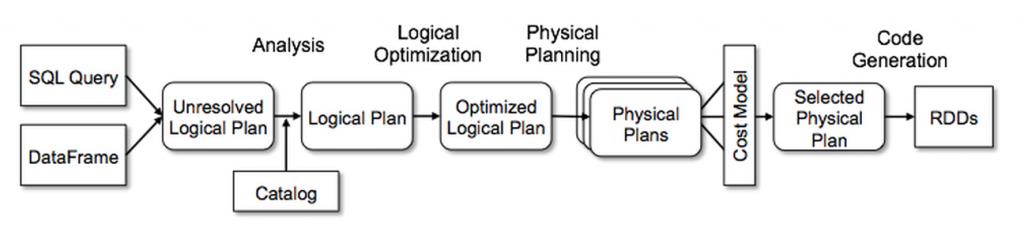
解析
逻辑计划优化
1 object DecimalAggregates extends Rule[LogicalPlan] { 2 /** Maximum number of decimal digits in a Long */ 3 val MAX_LONG_DIGITS = 18 4 def apply(plan: LogicalPlan): LogicalPlan = { 5 plan transformAllExpressions { 6 case Sum(e @ DecimalType.Expression(prec, scale)) 7 if prec + 10 <= MAX_LONG_DIGITS => 8 MakeDecimal(Sum(UnscaledValue(e)), prec + 10, scale) } 9 }
再举一个例子,一个12行代码的规则通过简单的正则表达式将LIKE表达式优化为String.startsWith或String.contains调用。在规则中使用任意Scala代码使得这些优化易于表达,而这些规则超越了子树结构的模式匹配。
物理计划
代码生成
1 def compile(node: Node): AST = node match { 2 case Literal(value) => q"$value" 3 case Attribute(name) => q"row.get($name)" 4 case Add(left, right) => q"${compile(left)} + ${compile(right)}" 5 }
以q开头的字符串是quasiquotes,虽然它们看起来像字符串,但它们在编译时由Scala编译器解析,并代表其代码的AST。 Quasiquotes用$符号表示法将变量或其他AST拼接到它们中。例如,文字(1)将成为1的Scala表达式的AST,而属性(“x”)变为row.get(“x”)。最后,类似Add(Literal(1),Attribute(“x”))的树成为像1 + row.get(“x”)这样的Scala表达式的AST。
- Spark SQL and DataFrame Programming Guide from Apache Spark
- Data Source API in Spark presentation by Yin Huai
- Introducing DataFrames in Spark for Large Scale Data Science by Reynold Xin
- Beyond SQL: Speeding up Spark with DataFrames by Michael Armbrust
以上是关于深入研究Spark SQL的Catalyst优化器(原创翻译)的主要内容,如果未能解决你的问题,请参考以下文章
第五篇:Spark SQL Catalyst源码分析之Optimizer
第四篇:Spark SQL Catalyst源码分析之TreeNode Library