自适应查询执行:在运行时提升Spark SQL执行性能
Posted 大数据学习与分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自适应查询执行:在运行时提升Spark SQL执行性能相关的知识,希望对你有一定的参考价值。
Spark SQL自适应执行优化引擎(Adaptive Query Execution,简称AQE)应运而生,它可以根据执行过程中的中间数据优化后续执行,从而提高整体执行效率。核心在于:通过在运行时对查询执行计划进行优化,允许Spark Planner在运行时执行可选的执行计划,这些计划将基于运行时统计数据进行优化,从而提升性能。
由shuffle和broadcast exchange把查询执行计划分为多个query stage,query stage执行完成时获取中间结果
-
query stage边界是运行时优化的最佳时机(天然的执行间歇;分区、数据大小等统计信息已经产生)
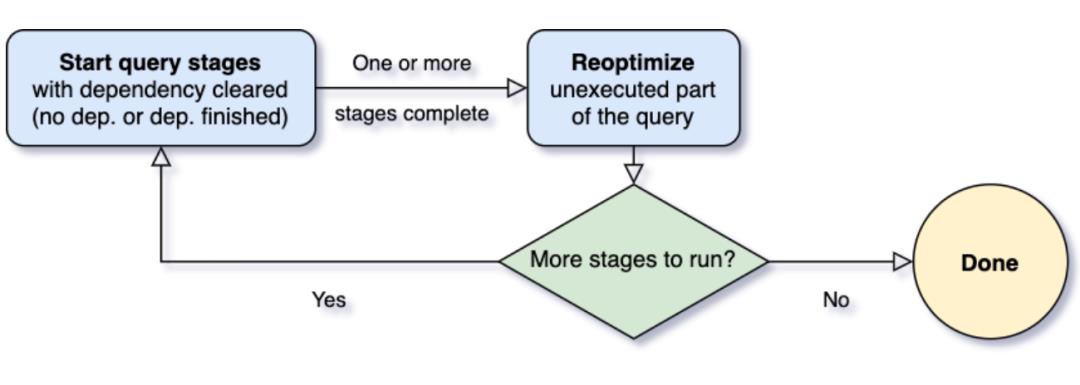
整个AQE的工作原理以及流程为:
-
运行没有依赖的stage -
在一个stage完成时再依据新的统计信息优化剩余部分 -
执行其他已经满足依赖的stage -
重复步骤(2)(3)直至所有stage执行完成
Spark从2.3版本,就开始"试验"SparkSQL自适应查询执行功能(Adaptive Query Execution),并在Spark3.0正式发布。
当查询开始时,自适应查询执行框架首先启动所有叶子阶段(leaf stages)—— 这些阶段不依赖于任何其他阶段。一旦其中一个或多个阶段完成物化,框架便会在物理查询计划中将它们标记为完成,并相应地更新逻辑查询计划,同时从完成的阶段检索运行时统计信息。
-
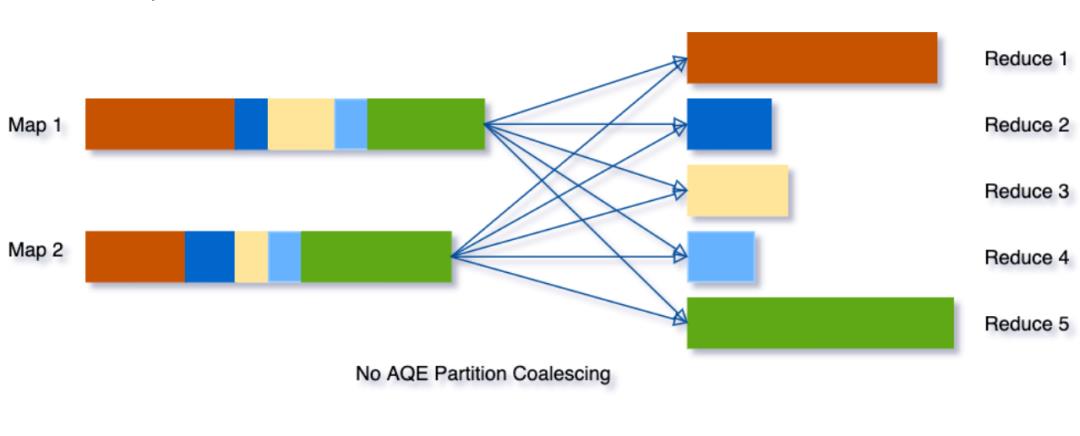
Dynamically coalescing shuffle partitions(动态合并shuffle的分区) 可以简化甚至避免调整shuffle分区的数量。用户可以在开始时设置相对较多的shuffle分区数,AQE会在运行时将相邻的小分区合并为较大的分区。 -
Dynamically switching join strategies(动态调整join策略) 在一定程度上避免由于缺少统计信息或着错误估计大小(当然也可能两种情况同时存在),而导致执行次优计划的情况。这种自适应优化可以在运行时sort merge join转换成broadcast hash join,从而进一步提升性能
-
Dynamically optimizing skew joins(动态优化数据倾斜的join) skew joins可能导致负载的极端不平衡,并严重降低性能。在AQE从shuffle文件统计信息中检测到任何倾斜后,它可以将倾斜的分区分割成更小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜处理,获得更好的整体性能。
-
如果分区数太少,那么每个分区处理的数据可能非常大,处理这些大分区的任务可能需要将数据溢写到磁盘(例如,涉及排序或聚合的操作),从而减慢查询速度 -
如果分区数太多,那么每个分区处理的数据可能非常小,并且将有大量的网络数据获取来读取shuffle块,这也会由于低效的I/O模式而减慢查询速度。大量的task也会给Spark任务调度程序带来更多的负担
SELECT max(i)FROM tbl GROUP BY j


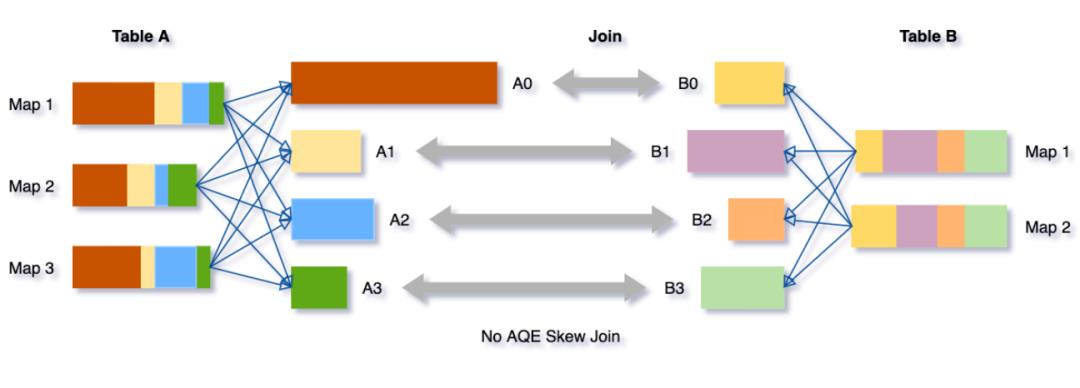

如果没有这个优化,将有四个任务运行sort merge join,其中一个任务将花费非常长的时间。在此优化之后,将有5个任务运行join,但每个任务将花费大致相同的时间,从而获得总体更好的性能。
AQE查询计划
AQE查询计划的一个主要区别是,它通常随着执行的进展而演变。引入了几个AQE特定的计划节点,以提供有关执行的更多详细信息。
此外,AQE使用了一种新的查询计划字符串格式,可以显示初始和最终的查询执行计划。
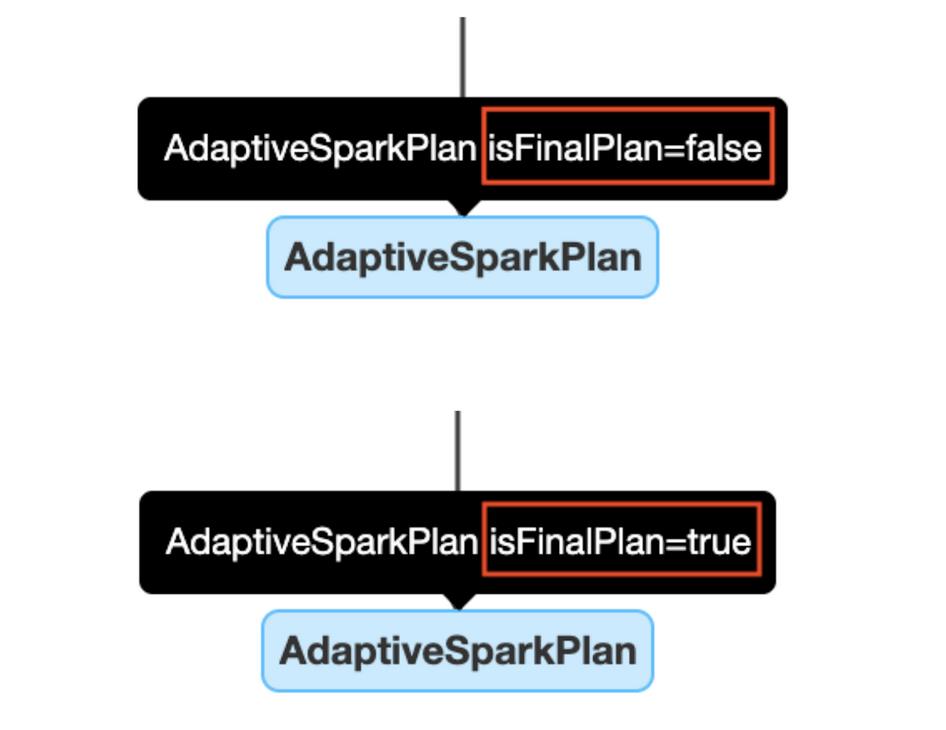
|| AdaptiveSparkPlan节点
应用了AQE的查询通常有一个或多个AdaptiveSparkPlan节点作为每个查询或子查询的root节点。在执行之前或期间,isFinalPlan标志将显示为false。查询完成后,此标志将变为true,并且AdaptiveSparkPlan节点下的计划将不再变化。
|| CustomShuffleReader节点
当CustomShuffleReader的标志为coalesced时,表示AQE已根据目标分区大小在shuffle后检测并合并了小分区。此节点的详细信息显示合并后的无序分区数和分区大小。
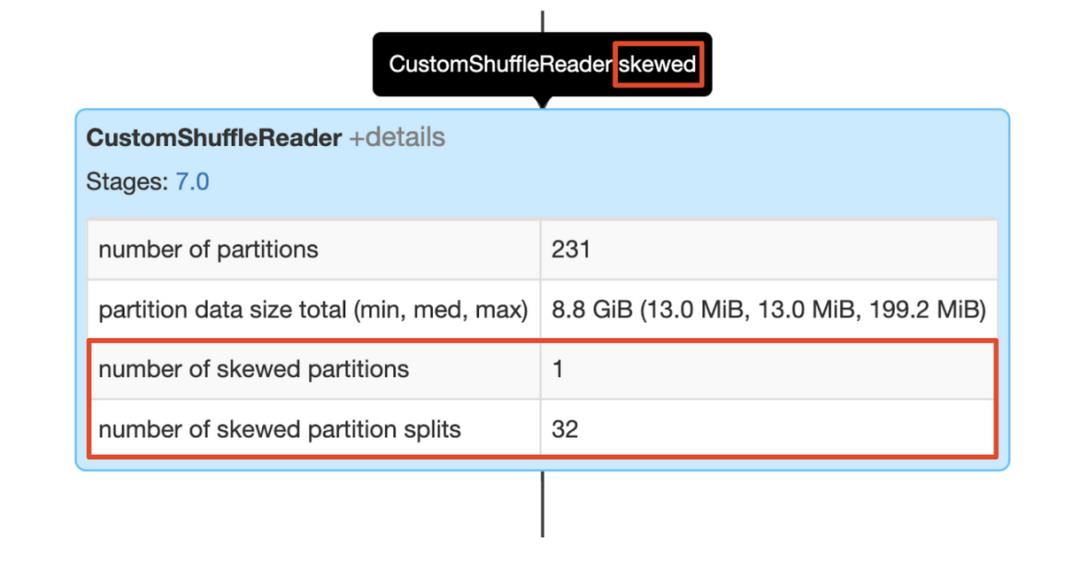
 当CustomShuffleReader的标志为"skewed"时,这意味着AQE在排序合并连接操作之前检测到一个或多个分区中的数据倾斜。此节点的详细信息显示了倾斜分区的数量以及从倾斜分区拆分的新分区的总数。
当CustomShuffleReader的标志为"skewed"时,这意味着AQE在排序合并连接操作之前检测到一个或多个分区中的数据倾斜。此节点的详细信息显示了倾斜分区的数量以及从倾斜分区拆分的新分区的总数。
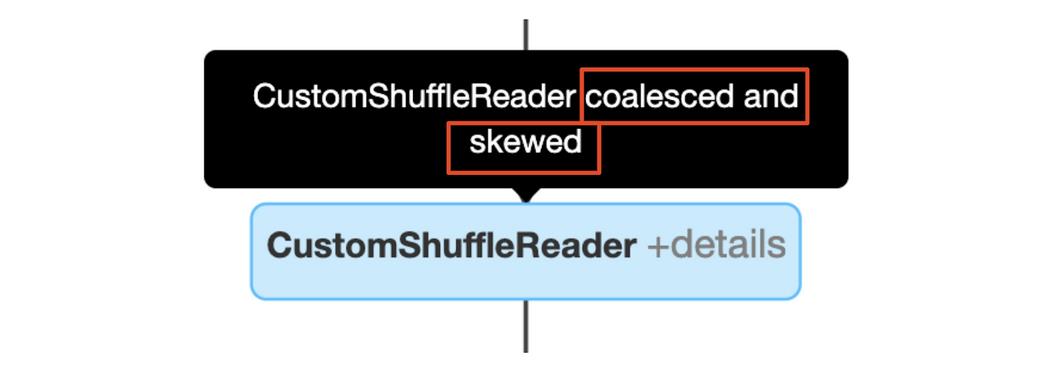
coalesced和skewed也可以同时发生:
|| 检测join策略改变
通过比较AQE优化前后查询计划join节点的变化,可以识别join策略的变化。在dbr7.3中,AQE查询计划字符串将包括初始计划(应用任何AQE优化之前的计划)和当前或最终计划。这样可以更好地了解应用于查询的优化AQE。
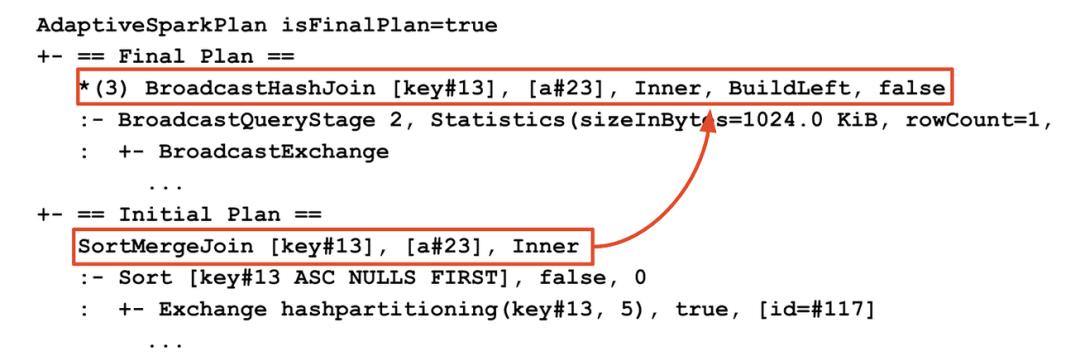
Spark UI将只显示当前计划。为了查看使用Spark UI的效果,用户可以比较查询执行之前和执行完成后的计划图:
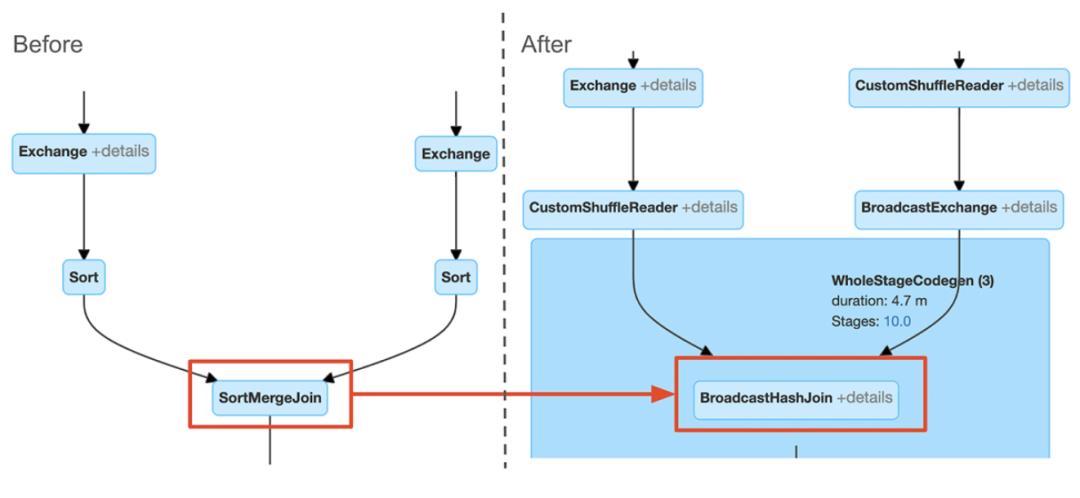
|| 检测倾斜join
倾斜连接优化的效果可以通过连接节点名来识别。
在Spark UI中:
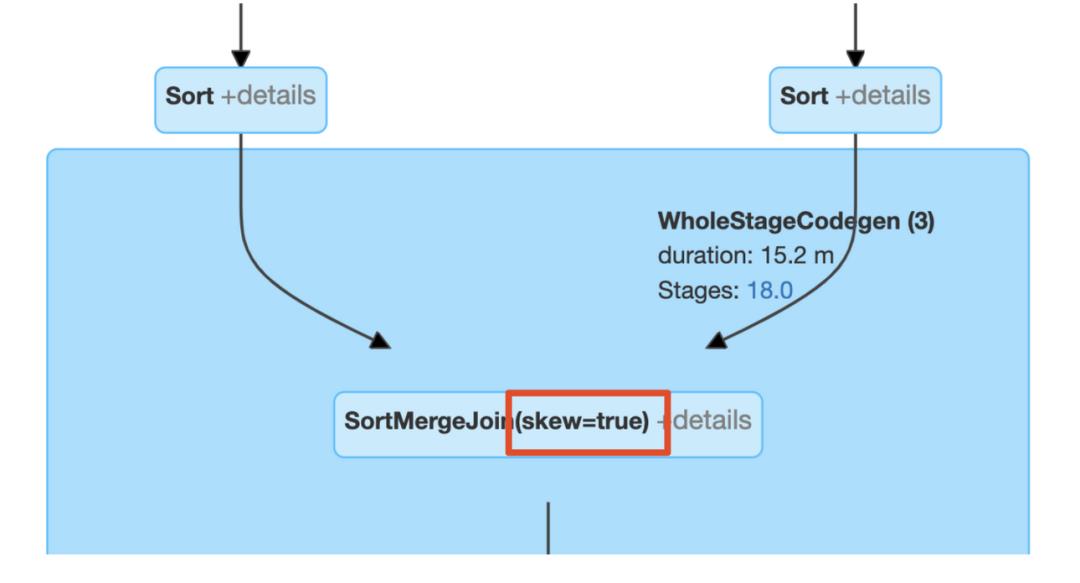
在查询计划字符串中:

AQE的TPC-DS表现
-
不是一个流查询 -
至少包含一个exchange(通常在有join、聚合或窗口操作时)或是一个子查询
1.https://databricks.com/blog/2020/05/29/adaptive-query-execution-speeding-up-spark-sql-at-runtime.html
https://www.cnblogs.com/zz-ksw/p/11254294.html
https://issues.apache.org/jira/browse/SPARK-23128
以上是关于自适应查询执行:在运行时提升Spark SQL执行性能的主要内容,如果未能解决你的问题,请参考以下文章