基于python的prosper借贷平台之数据分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于python的prosper借贷平台之数据分析相关的知识,希望对你有一定的参考价值。
参考技术A 项目介绍:p2p 借贷业务具有门槛低,渠道成本低的特性,风险防控对于出借企业来说非常重要。本项目需要
从大量借贷者的数据集中分析出容易违约和不容易违约的人群画像特征,以给业务做贷前决策使
用。同时使用机器学习算法,实现自动识别风险人群(精准率为 89.86%),加快人工审查效率。
项目具体内容:
1、使用 python pandas 工具进行数据清洗、缺失值、异常值处理以及特征指标筛选。
2、使用 python matplotlib 可视化工具进行探索式数据分析,展示用户关键特征如月收入、信用卡
透支情况对于违约率的影响情况。
3、使用机器学习随机森林进行建模分析,使用学习曲线、网格搜索、交叉验证,最终得到了一个评
分为 84.9%、精准率为 89.86%、召回率为 80.70%、auc 面积为 0.9337 数据预测模型。
本次数据训练使用的模型是随机森林分类算法,通过对预处理过的数据集进行训练,使用学习曲线、网格搜索、交叉验证。最终得到了一个评分为84.9%、精准率为89.86%、召回率为80.70%、 auc面积为0.9337 数据预测模型。
数据预处理的基本流程与思路:
1、首先要明确有多少特征,哪些是连续的,哪些是类别的。
2、检查有没有缺失值,对确实的特征选择恰当方式进行弥补,使数据完整。
3、对连续的数值型特征进行标准化,使得均值为0,方差为1。
4、对类别型的特征进行one-hot编码。
5、将需要转换成类别型数据的连续型数据进行二值化。
6、为防止过拟合或者其他原因,选择是否要将数据进行正则化。
7、在对数据进行初探之后发现效果不佳,可以尝试使用多项式方法,寻找非线性的关系。
8、根据实际问题分析是否需要对特征进行相应的函数转换。
导入数据集,并查看数据基本情况。可以看到prosper原始数据量比较庞大,一个有113937个样本,80个特征列,1个标签列。
1.1、特征较多,先共删减一部分无用的特征。
1.2 查看数据缺失情况,可以看到有40个特征是存在数据缺失的,缺失率从0.000219-0.882909不等。下面处理缺失数据。
1.2.1 删除缺失值比较多的特征
下面两个特征缺失率太高,且与我们要分析的相关性不大,直接删除掉。
1.2.2 获取数据类型是分类变量的所有特征,并使用unknown进行填充
1.2.3 特殊变量使用计算公式进行填充
1.2.4 去掉意义重复列
1.2.5 删除缺失率比较少的特征的缺失数据行
处理完缺失数据后,样本量为106290,特征量为55
1.3 数据过滤
1.3.1 从2009年7月开始,Prosper调整了对客户的评估方式,此次我们只对2009-07-01后的贷款进行分析。
过滤完数据后,样本量变为82931,特征量为54
2.1单变量分析
0为未违约人数,1位违约人数,可以看到2009.07以后,违约率为22.90%
2.1.1不同地区贷款数量分布
从图中可以看到加利福尼亚州贷款数量远比其他州的数量高。由于prosper总部就位于加利福尼亚州,这与实际情况一致。其他排名靠前的分别是得克萨斯、纽约、佛罗里达、伊利诺伊,贷款数据均超过了5000条。根据2015年美国各州的GDP排名,这5个州刚好排名前五,而且顺序也是一致的。说明Prosper平台的用户主要分布在美国经济发达的地区。
2.1.2 贷款人收入情况分布
年薪在25000美金以上在美国属于技术性白领或者有一定学历的职员,50000美金已经是近金领阶层,比如:大学教授,医生等。从图中可以看出Prosper平台用户的收入水平都相对较高,有利于用户还款,利于平台和投资者的风险控制。
2.1.3贷款人职业分布
从图中可以看出,除了不愿意透露具体职业的人,大部分用户是教授、程序员、企业高管等具有一定社会地位的人,这部分人受过高等教育,信用有一定保障。另外,这与之前看到的收入情况相符。
2.1.4贷款人债务收入比分布
大部分用户的债务收入比在0.2左右,超过0.5的占很少部分。说明Prosper平台用户的还款能力还是比较乐观的
2.1.5 贷款者信用卡使用情况
BankcardUtilization代表的是信用卡使用金额和信用卡额度的比值,可以体现用户的资金需求。Prosper用户多是0.5~1之间,说明用户每个月还有信用卡要还,降低了其还款能力。
2.2 相关的关键因素对贷款违约率的影响
2.2.1借贷人收入IncomeRange对违约率的影响
从图中可以看出:
1.一般来说收入越高违约率越低
2.贷款的人员主要集中在中等收入群体
2.2.2 债务收入比DebtToIncomeRatio对违约率的影响
从上图可以看出:
1.债务收入比小于0.6时,违约数明显小于未违约数,
2.当债务收入比大于0.6时,两者的差距不是很明显甚至违约数大于未违约数,说明了债务收入比越大的人越容易违约
2.2.3 借款人BankcardUtilization对违约率的影响
1.总的来说,随着信用卡的透支比例越来越高,违约率也越来越高
2.SuperUse的违约率到了37.5%,这部分人群需要严格了监控,No Use人群也有31%的违约率,当初将信用卡透支比例为0和NA的数据都归类为No Use,显然没有这么简单,应该是大部分人群的NA值是为了隐藏自己的高透支比例而填写的
2.2.4 消费信用分CreditScoreRange对违约率的影响
从上图可以看出:
1.随着信用分数CreditScore的上升,它的违约率在下降
2.大部分贷款者的信用分为650-800,违约率在0.06-0.02
2.2.5 过去7年借款人违约次数DelinquenciesLast7Years对违约率的影响
过去七年违约次数(DelinquenciesLast7Years)能够衡量一个人在过去七年中征信情况,违约一次或以上的人在借款时违约概率更大。
从上图可以看出:
1.总体来说过去7年违约次数越多,违约率越高
2.过去7年未违约的人数相对来说比其他违约的人数高很多,具体看下面的分析
3.1 数据转化
3.1.1类变量进行哑变量化
样本量变为82931,特征量为127
3.1.2 标签变量进行二分类
已完成贷款的样本量变为26365,特征量为127
未违约率为:0.7709084012895885;违约率为0.22909159871041151
3.2 至此,数据预处理的工作就告一段落,保存预处理好的数据。
导入经过预处理的prosper借贷数据集
4.1 手工挑选特征查看一下建模效果
准确率为0.7695
4.2 使用模型自己选取特征
准确率为0.7780
4.3 使用学习曲线选取最优n_estimators
在0-200/20内学习,得到最优n_estimators=161,score = 0.8508
在151-171/20内学习,得到最优n_estimators=163,score = 0.8511
4.4 使用网格搜索调其他参数
在0-60/5内学习,得到最优max_depth=41
在0-60/5内学习,得到最优max_features=16
这里由于比较耗时,没有进一步细化选择更高的参数
4.4 最终模型效果
最终准确率 0.8490528905289052
混淆矩阵 :
[[5552 554]
[1175 4914]]
精准率 : [0.82533076 0.89868325]
召回率 : [0.90926957 0.80702907]
roc和auc面积为0.9337
4.5 查看各特征的重要性
4.6 数据预测
预测的违约率0.0427
分布式事物之综合案例分析
7.1系统介绍
P2P 金融又叫P2P信贷。其中P2P是 peer-to-peer 或 person-to-person 的简写,意思是:个人对个人。P2P金融指个人与个人间的小额借贷交易,一般需要借助电子商务专业网络平台帮助借贷双方确立借贷关系并完成相关交易手续。借款者可自行发布借款信息,包括金额、利息、还款方式和时间,实现自助式借款;投资者根据借款人发布的信息,自行决定出借金额,实现自助式借贷。目前,国家对P2P行业的监控与规范性控制越来越严格,出台了很多政策来对其专项整治。并主张采用“银行存管模式”来规避P2P平台挪用借投人资金的风险,通过银行开发的“银行存管系统”管理投资者的资金,每位P2P平台用户在银行的存管系统内都会有一个独立账号,平台来管理交易,做到资金和交易分开,让P2P平台不能接触到资金,就可以一定程度避免资金被挪用的风险。
什么是银行存管模式?
银行存管模式涉及到2套账户体系,P2P平台和银行各一套账户体系。投资人在P2P平台注册后,会同时跳转到银行再开一个电子账户,2个账户间有一一对应的关系。当投资人投资时,资金进入的是平台在银行为投资人开设的二级账户中,每一笔交易,是由银行在投资人与借款人间的交易划转,P2P平台仅能看到信息的流动。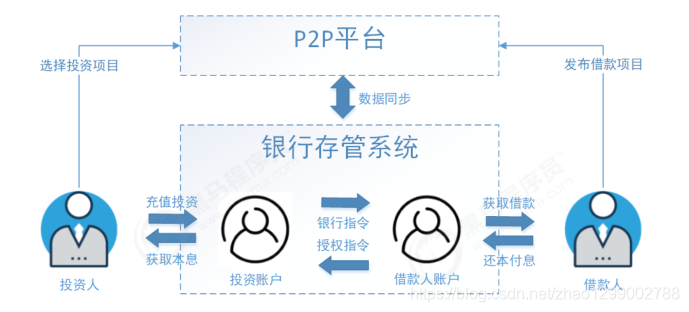
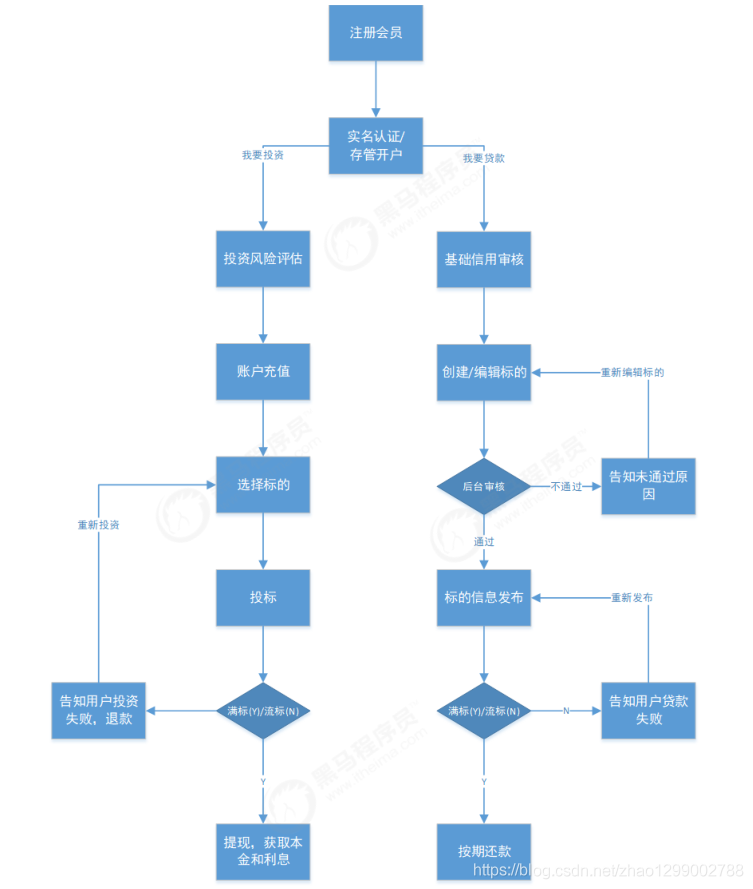
| 术语 | 描述 |
|---|---|
| 银行存管模式 | 这种模式下,涉及到2套账户系统,P2P平台和银行各一套账户体系。投资人在P2P平台注册后,会同时跳转到银行再开一个电子账户,2个账户间有一一对应的关系。当投资人投资时,资金进入的是平台在银行为投资人开设的二级账户中,每一笔交易,由银行在投资人与借款人间的交易划转,P2P平台仅能看到信息的流动。 |
| 标的 | P2P业内,习惯把借款人发布的投资项目称为“标的”。 |
| 发标 | 借款人在P2P平台中创建并发布“标的”过程。 |
| 投标 | 投资人在认可相关借款人之后进行额一种借贷行为,对自己中意的借款标的进行投资操作,一个借款标可由单个投资人或多个投资人承接。 |
| 满标 | 单笔借款标筹集齐所有借款资金即为满标,计息时间是以标满当日开始计息,投资人较多的平台多数会当天满标。 |
统一账户服务
用户的登录账户、密码、角色、权限、资源等系统级信息的管理,不包含用户业务信息。
用户中心
提供用户业务信息的管理,如会员信息、实名认证信息、绑定银行卡信息等,“用户中心”的每个用户与“统一账户服务”中的账号关联。
交易中心
提供发标、投标等业务。
还款服务
提供还款计划的生成、执行、记录与归档。
银行存管系统(模拟)
模拟银行存管系统,进行资金的存管,划转。
采用用户、账号分离设计(这样设计的好处是,当用户的业务信息发生变化时,不会影响的认证、授权等系统机制),因此需要保证用户信息与账号信息的一致性。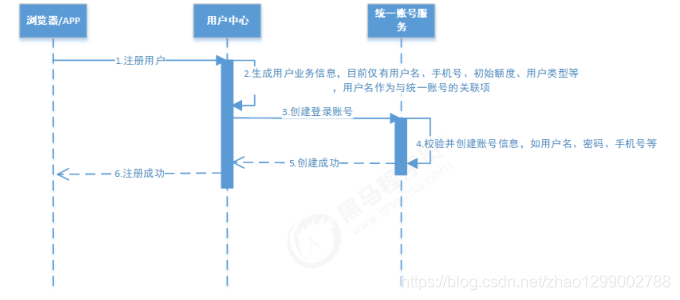
针对注册业务,如果用户与账号信息不一致,则会导致严重问题,因此该业务对一致性要求较为严格,即当用户服务和账号服务任意一方出现问题都需要回滚事务。
根据上述需求进行解决方案分析 :
1、采用可靠消息一致性方案
可靠消息一致性要求只要消息发出,事务参与者接到消息就要将事务执行成功,不存在回滚的要求,所以不适用。
2、采用最大努力通知方案
最大努力通知表示发起通知执行完本地事务后将结果通知给事务参与者,即使事务参与者执行业务处理失败发起通知方也不会回滚事务,所以不适用。
3、采用Seata实现2PC
在用户中心发起全局事务,统一账户服务为事务参与者,用户中心和统一账户服务只要有一方出现问题则全局事务回滚,符合要求。
实现方法如下 :
1、用户中心添加用户信息,开启全局事务
2、统一账号服务添加账号信息,作为事务参与者
3、其中一方执行失败Seata对SQL进行逆操作删除用户信息和账号信息,实现回滚。
4、采用Hmily实现TCC
TCC也可以实现用户中心和统一账户服务只要有一方出现问题则全局事务回滚,符合要求。
实现方法如下 :
1、用户中心
try :添加用户,状态为不可用
confirm :更新用户账户为可用
cancel :删除用户
2、统一账号服务
try :添加账号,状态不可用
confirm :更新账号状态为可用
cancel :删除账号
根据政策要求,P2P业务必须让银行存管资金,用户的资金在银行存管系统的账户中,而不在P2P平台中,因此用户要在银行存管系统开户。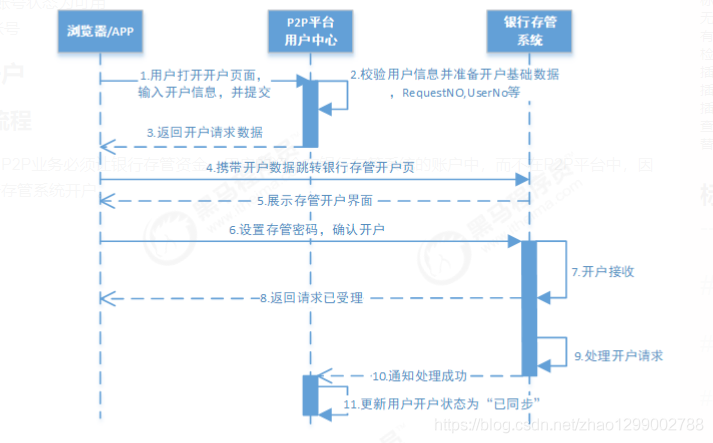
用户向用户中心提交开户资源,用户中心生成开户请求号并重定向至银行存管系统开户页面。用户设置存管密码并确认开户后,银行存管立即返回“请求已受理”。在某一个时刻,银行存管系统处理完该开户请求后,将调用回调地址通知处理结果,若通知失败,则按一定策略重试通知。同时,银行存管系统应提供开户结果查询的接口,供用户中心校对结果。
P2P平台的用户中心与银行存管系统之间属于跨系统交互,银行存管系统属于外部系统,用户中心无法干预银行存管系统,所以用户中心只能在收到银行存管系统的业务处理结果通知后积极处理,开户后的使用情况完全由用户中心开控制。
根据上述需求进行解决方案分析 :
1、采用Seata实现2PC
需要侵入银行存管系统的数据库,由于它的外部系统,所以不适用。
2、采用Hmily实现TCC
TCC侵入性更强,所以不适用。
3、基于MQ的可靠消息一致性
如果让银行存管系统监听MQ则不合适,因为它的外部系统。如果银行存管系统将消息发给MQ用户中心监听MQ是可以的,但是由于相对银行存管系统来说用户中心属于外部系统,银行存管系统是不会让外部系统直接监听自己的MQ的,基于MQ的通信协议也不方便外部系统间的交互。所以本方案不适合。
4、最大努力通知方案
银行存管系统内部使用MQ,银行存管系统处理完业务后将处理结果发给MQ,由银行存管的通知程序专门发送通知,并且采用互联网协议通知给第三方系统(用户中心)。
下图中发起通知即银行存管系统 :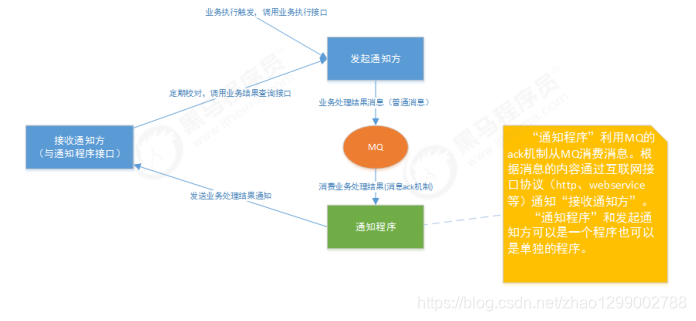
在借款人标的募集够所有的资金后,P2P运营管理员审批该标的,触发放款,并开启还款流程。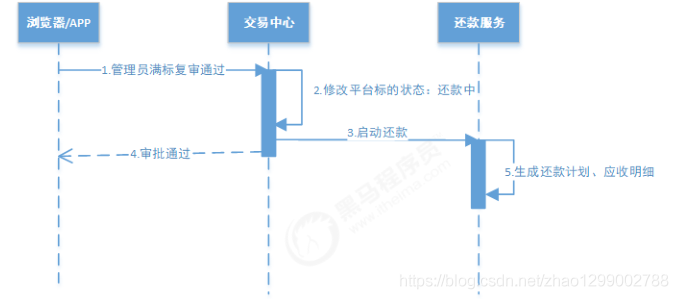
管理员对某标的满标审批通过,交易中心修改标的状态为“还款中”,同时要通知还款服务生成还款计划。
生成还款计划是一个执行时长较长的业务,不建议阻塞主业务流程,此业务对一致性要求较低。
根据上述需求进行解决方案分析 :
1、采用Seata实现2PC
Seata在事务执行过程会进行数据库资源锁定,由于事务执行时长较长会将资源锁定较长时间,所以不适用。
2、采用Hmily实现TCC
本需求对业务一致性要求较低,因为生成还款计划的时长较长,所以不要求交易中心修改标的状态为“还款中”就立即生成还款计划,所以本方案不适用。
3、基于MQ的可靠消息一致性
满标批通过后由交易中心修改标的状态为“还款中”并且向还款服务发送消息,还款服务接收到消息开始生成还款计划,基于MQ的可靠消息一致性方案适用此场景。
4、最大努力通知方案
满标审批通过后交易中心向还款服务发送通知要求生成还款计划,还款服务并且对外提供还款计划生成结果校对接口供其他服务查询,最大努力通知也适用本场景。
各种方案的优缺点 :
2PC最大的诟病是阻塞协议。RM在执行分支事务后需要等待TM的决定,此时服务会阻塞并锁定资源。由于其阻塞机制和最差时间复杂度高,因此,这种设计不能适应随着事务涉及的服务数量增加而扩展的需要,很难用于并发较高以及子事务生命周期较长(long-running
transactions)的分布式服务中。
如果拿TCC事务的处理流程与2PC两阶段提交做比较,2PC通常都是在跨库的DB层面,而TCC则在应用层面的处理,需要通过业务逻辑来实现。这种分布式事务的实现方式的优势在于,可以让应用自己定义数据操作的粒度,使得降低锁冲突,提高吞吐量成为可能。
而不足之处则在于对应用的侵入性非常强,业务逻辑的每个分支都需要实现try、confirm、cancel三个操作。此外,其实现难度也比较大,需要按照网络状态、系统故障等不同的失败原因实现不同的回滚策略。典型的使用场景 :满,登录送优惠卷等。
可靠消息最终一致性事务适合执行周期长且实时性要求不高的场景。引入消息机制后,同步的事务操作变为基于消息执行的异步操作,避免来分布式事务中的同步阻塞操作的影响,并实现来两个服务的解耦。典型的使用场景 :注册送积分,登录送优惠卷等。
最大努力通知是分布式事务中要求最低的一种,适用于一些最终一致性时间敏感度低的业务;允许发起通知方处理业务失败,在接收通知发收到通知后积极进行失败处理,无论发起通知方如何处理结果都不会影响到接收通知方的后续处理;发起通知方需提供查询执行情况接口,用于接收通知方校对结果。典型的使用场景 :银行通知、支付结果通知等。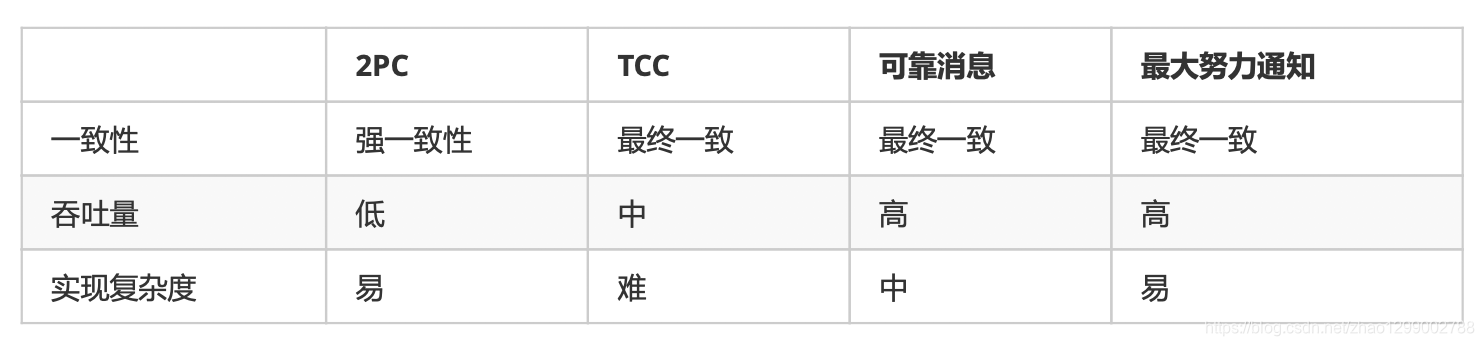
总结 :
在条件允许的情况下,我们尽可能选择本地事务单数据源,因为它减少来网络交互带来的性能损耗,且避免来数据若一致性带来的种种问题。若某系统频繁不合理的使用分布式事务,应首先从整体设计角度观察服务的拆分是否合理,是否高内聚低耦合?是否粒度太小?分布式事务一直是业界难题,因为网络的不确定性,而且我们习惯于拿分布式事务与单机事务ACID做对比。
无论是数据库曾的XA、还是应用层TCC、可靠消息、最大努力通知等方案,都没有完美解决分布式事务问题,他们不过是各自在性能、一致性、可用性等方面做取舍,寻求某些场景偏好下的权衡。
以上是关于基于python的prosper借贷平台之数据分析的主要内容,如果未能解决你的问题,请参考以下文章