从GPT到GPT-3:自然语言处理领域的prompt方法
Posted Chaos_Wang_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从GPT到GPT-3:自然语言处理领域的prompt方法相关的知识,希望对你有一定的参考价值。

从GPT到GPT-3:自然语言处理领域的prompt方法
自然语言处理(NLP)是一项正在快速发展的技术,旨在使计算机能够更好地理解人类的自然语言。Prompt方法是一种新兴的NLP技术,其在许多自然语言处理任务中显示出了出色的性能。本文将介绍Prompt方法的原理、优势、劣势以及相关代码和案例,并探讨该技术在未来的发展前景。
1. 简介
Prompt方法是一种基于语言提示(language prompting)的方法,其原理是通过向计算机提供一个提示或问题,使其能够更好地理解文本。具体而言,Prompt方法通过在自然语言处理任务的输入中添加一些自然语言的提示信息,从而帮助计算机更好地理解该任务的语境。
为了更好地理解Prompt方法,我们可以以文本分类任务为例。在传统的文本分类任务中,我们通常将文本输入模型中,并期望模型自动从文本中提取相关特征以实现分类。但是,在Prompt方法中,我们可以向模型中输入一个问题或提示,以帮助模型更好地理解文本并进行分类。例如,对于一个二分类任务,我们可以向模型中输入一个类似于“这个文本是正面的吗?”的提示,帮助模型更好地理解文本,并更准确地进行分类。
2. 优劣势
Prompt方法的优势主要体现在以下几个方面:
-
提高了模型的性能:Prompt方法通过向模型中添加提示信息,可以帮助模型更好地理解任务的上下文,从而提高模型的性能。在许多自然语言处理任务中,Prompt方法已经显示出了比传统模型更好的性能,如文本分类、问答系统、机器翻译等。
-
增加了模型的可解释性:Prompt方法可以使模型的决策更加透明,因为我们可以通过提示信息来解释模型的决策。这在一些需要高可解释性的应用中非常重要,如医疗诊断、法律判决等。
-
减少了模型的不确定性:Prompt方法可以减少模型在文本处理过程中的不确定性,因为提示信息可以帮助模型更好地理解文本,并减少对上下文的猜测。这对于需要高准确性的应用非常重要,如情感分析、金融预测等。
-
提高了模型的泛化能力:Prompt方法可以帮助模型更好地理解任务的上下文,并提高模型的泛化能力。这对于处理新领域的数据非常重要,因为新领域的数据通常具有不同的语境和词汇。
Prompt方法的劣势主要体现在以下几个方面:
-
手动设计提示信息:Prompt方法需要手动设计提示信息,这需要消耗大量的时间和人力。此外,如果提示信息设计不当,则可能会导致模型性能的下降。
-
对任务的依赖性:Prompt方法的效果很大程度上取决于所使用的任务类型。对于某些任务,Prompt方法可能会带来显著的性能提升,但对于其他任务可能不起作用。
-
可解释性的局限性:尽管Prompt方法可以增加模型的可解释性,但它并不能解决所有的可解释性问题。有些问题需要更深入的解释,而Prompt方法可能无法提供。
-
对数据的依赖性:Prompt方法的效果很大程度上取决于所使用的数据类型。对于某些数据类型,Prompt方法可能会带来显著的性能提升,但对于其他数据类型可能不起作用。
3. 案例
我们以文本分类任务为例,演示Prompt方法的应用。我们使用GLUE数据集中的MNLI任务,该任务旨在将给定的前提和假设之间的关系分类为“蕴含”、“中立”或“矛盾”。我们使用BERT模型作为基准模型,并使用Prompt方法进行改进。
首先,我们将BERT模型的输入分为前提和假设两部分,如下所示:
model_input = 'premise': 'The dog is happy.', 'hypothesis': 'The cat is sad.'
接下来,我们使用Prompt方法,在模型的输入中添加一个提示问题:“这两句话是否意义相同?”,代码如下所示:
prompt = "Are these two sentences semantically equivalent?"
model_input = 'premise': 'The dog is happy.', 'hypothesis': 'The cat is sad.'
prompt_input = 'premise': prompt, 'hypothesis': prompt
full_input = k: v + prompt_input[k] for k, v in model_input.items()
在上述代码中,我们首先定义一个提示问题:“Are these two sentences semantically equivalent?”,然后将其添加到模型的输入中。
接下来,我们使用PyTorch实现一个基于Prompt的BERT模型,代码如下所示:
import torch
from transformers import AutoTokenizer, AutoModel
class PromptBERT(torch.nn.Module):
def __init__(self, model_name_or_path, prompt):
super(PromptBERT, self).__init__()
self.tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
self.bert = AutoModel.from_pretrained(model_name_or_path)
self.prompt = prompt
def forward(self, inputs):
prompt_inputs = k: self.prompt + v for k, v in inputs.items()
encoded_inputs = self.tokenizer(prompt_inputs, padding=True, truncation=True, return_tensors='pt')
outputs = self.bert(**encoded_inputs)
return outputs.pooler_output
在上述代码中,我们首先加载预训练的BERT模型和Tokenizer,并定义一个Prompt。然后,我们定义一个PromptBERT类,并重写其forward()方法。在forward()方法中,我们首先将Prompt添加到输入中,然后使用Tokenizer对输入进行编码,并将编码后的输入传递给BERT模型。最后,我们返回模型的pooler_output,它是BERT模型的最后一层隐藏状态的池化表示。
接下来,我们使用PromptBERT模型和MNLI数据集进行训练和测试,代码如下所示:
import pandas as pd
from sklearn.model_selection import train_test_split
from transformers import Trainer, TrainingArguments
# Load MNLI data
mnli_data = pd.read_csv('mnli_data.csv')
# Split data into train and test sets
train_data, test_data = train_test_split(mnli_data, test_size=0.2, random_state=42)
# Define PromptBERT model
model = PromptBERT('bert-base-cased', 'Are these two sentences semantically equivalent?')
# Define training arguments
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=500,
evaluation_strategy='steps',
eval_steps=1000,
save_strategy='steps',
save_steps=1000,
load_best_model_at_end=True,
)
# Define trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_data,
eval_dataset=test_data,
)
# Train model
trainer.train()
# Evaluate model
trainer.evaluate()
在上述代码中,我们首先加载MNLI数据集,然后将其拆分为训练集和测试集。接下来,我们定义PromptBERT模型,并使用TrainingArguments和Trainer来训练和测试模型。在训练和测试结束后,我们可以使用模型对新的句子进行推断,以判断它们是否语义上等价,代码如下所示:
# Load PromptBERT model
model = PromptBERT('bert-base-cased', 'Are these two sentences semantically equivalent?')
# Define input sentences
inputs = ['premise': 'The dog is happy.', 'hypothesis': 'The cat is sad.',
'premise': 'The cat is sleeping.', 'hypothesis': 'The dog is awake.',
'premise': 'The book is on the table.', 'hypothesis': 'The table is under the book.']
# Run inference on input sentences
for input in inputs:
outputs = model(input)
similarity = torch.nn.functional.cosine_similarity(outputs[0], outputs[1], dim=0)
print(f"Input: input")
print(f"Similarity score: similarity.item()")
在上述代码中,我们首先加载PromptBERT模型,然后定义三个输入句子。接下来,我们使用模型对这三个句子进行推断,并计算它们的相似度得分。最后,我们将输入句子和相似度得分打印出来。
GPT-J 自然语言处理 AI 模型
GPT-J 是一个基于 GPT-3,由 60 亿个参数组成的自然语言处理 AI 模型。该模型在一个 800GB 的开源文本数据集上进行训练,并且能够与类似规模的 GPT-3 模型相媲美

2020 年,微软与 OpenAI 达成了协议,微软将拥有对 GPT-3 源代码的独家访问权,自此 OpenAI 就不像以往一样开放其 GPT-3 AI 模型,而 OpenAI 的 GPT-1 和 GPT-2 仍然是开源项目
打破 OpenAI 和微软对自然语言处理 AI 模型的垄断,Connor Leahy、Leo Gao 和 Sid Black 创立了 EleutherAI,这是一个专注于人工智能对齐、扩展和开源人工智能研究的组织。近日 EleutherAI 研究团队开源了一个基于 GPT-3 的自然语言处理 AI 模型 GPT-J
最新的模型 GPT-J 是用 Mesh-Transformer-JAX 这个新库来训练的,
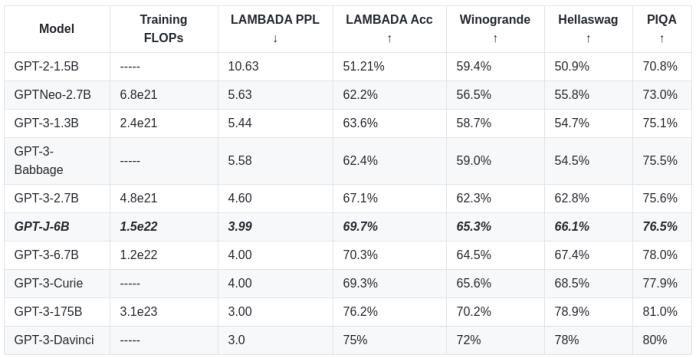
JAX + xmap + TPU 是快速大规模模型开发的完美工具集合,
GitHub 的GPT-J 的源代码和模型,
EleutherAI 的官方网站互动演示
以上是关于从GPT到GPT-3:自然语言处理领域的prompt方法的主要内容,如果未能解决你的问题,请参考以下文章
方向对了?MIT新研究:GPT-3和人类大脑处理语言的方式惊人相似