论文阅读Research on video adversarial attack with long living cycle
Posted c1assy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读Research on video adversarial attack with long living cycle相关的知识,希望对你有一定的参考价值。
论文链接:添加链接描述
Method

OPTIMIZATION PROBLEM DESCRIPTION
X
X
X是浮点数域中的对抗视频示例,
X
c
X_c
Xc表示encoded的视频对抗示例。设
E
=
X
ˆ
−
X
E = Xˆ−X
E=Xˆ−X表示在对抗中增加的扰动,
E
c
=
X
c
−
X
E_c = Xc − X
Ec=Xc−X表示视频压缩编码损失。
our optimization question can be presented as Eq.1:

y
t
r
u
t
h
y_truth
ytruth是样本
X
X
X的真实标签,
y
s
e
l
e
c
t
y_select
yselect是可选标签,我们发现如果我们选择a target label作为优化目标标签,优化函数可以更快地收敛。但这不是目标攻击,因为我们只是使用所选择的标签来加速优化函数的收敛。标签的选择可以是随机的。我们稍后将介绍我们的目标攻击。在我们的实验中,我们选择the label with the second-highest confidence score。
f
(
)
f()
f() 是受害者视频识别模型。
ROUNDING LOSS
对于大多数视频识别DNN模型,在训练过程中,它们将视频样本从整数域归一化到浮点数域。这样,模型可以快速收敛。因此,以往的对抗性实例生成方法也是在浮点数空间中生成对抗性实例。
在我们的实验中,我们发现如果我们想保存我们的对抗图像,归一化引起的舍入损失(rounding loss)是不能忽略的。
To avoid this, in this paper, we add our perturbation in the original integer space,
X
ˆ
=
X
+
P
∈
[
0
,
255
]
Xˆ= X +P ∈ [0, 255]
Xˆ=X+P∈[0,255]. In this way, we can easily control the scale of perturbation and retain all the perturbation.
视频压缩编码
视频压缩编码的过程可以描述如下:
X
c
=
D
C
T
(
X
)
Q
X_c=DCT(X)Q
Xc=DCT(X)Q函数DCT()表示离散余弦变换,并且将视频帧从空间域spatial domain转换到频域frequency domain。此步骤不会造成损失。
Q表示压缩步骤的量化矩阵。编码过程中的无损步骤将不会在我们的算法中显示。接下来,我们将用一个简单的例子来解释为什么量化步骤会带来损失:如果存在四个不同的像素33、34、35、36,经过量化除法后,就变成了1,1,1,1。逆量化后,这四个值将变得相同,都是32。这就造成了信息的极大损失,表现在图像中的是色彩空间的缩小和细节的缺乏。当需要对编码后的视频进行帧提取时,过程可以表示为:
X
′
=
I
D
C
T
(
X
c
Q
−
1
)
X'=IDCT(X_cQ^-1)
X′=IDCT(XcQ−1)其中IDCT表示逆DCT,在此过程中,输出数据X与X不同,存在差值Ec。
ADVERSARIAL ATTACK
根据上述条件,我们可以构造我们的非目标攻击优化损失函数:

EXPERIMENT AND ANALYSIS
我们将分析我们的实验方法和实验结果,并将它们与先前的白盒攻击对抗性示例生成方法进行比较。
度量:参考[1]的稀疏攻击论文,我们使用四个度量来评估各个方面。
编码前的傻瓜比率(F):被定义为成功误分类的未编码对抗视频的百分比
可感知性(P):扰动的平均尺度。本文采用L∞ 范数来度量视觉隐藏。
L2范数:表示添加的扰动的L2范数。虽然我们使用了最大扰动幅值,但是当最大扰动幅值相同时,L2范数可以很好地表示附加扰动的程度。当计算L2范数时,我们使用归一化处理;也就是说,无论原始扰动是添加在整数RGB空间还是添加在[0,1]之间的浮点数空间中,我们都将其缩放到0和1之间以用于计算。
攻击成功率(ASR):编码视频的最终攻击成功率,并且该度量可以表示对抗样本的最终攻击能力。
Resistance (R):它代表了抵抗视频编码损坏的能力。例如,有M个未编码的对抗性例子可以成功地攻击模型。视频编码后,只有
M
∗
(
M
∗
≤
M
)
M^*(M^* ≤ M)
M∗(M∗≤M) 个视频仍能攻击成功,且预测标签与编码前的预测标签相同,则
R
=
M
∗
/
M
R = M^*/M
R=M∗/M。
untargeted attack
the attack effect of the untargeted attack adversarial examples before video compression encoding:

the attack effects of different algorithms after video compression encoding and the robustness against video compression encoding:

可见,该方法具有较好的抗视频编码性能。其他基于迭代的方法:如PGD和sparse attack,虽然在未编码的对抗性例子上可以取得很高的攻击成功率,但在编码视频面前却不能保持良好的性能。
在非目标攻击中, 视频压缩编码后,上述方法仍能保持较高的攻击成功率。然而,这并不意味着它们有很高的抵抗力。在我们的实验中,我们发现视频编码之后的预测标签不同于视频编码之前的预测标签。例如,真值标签是1,而在视频编码之前的敌对示例的预测标签是2,但是在视频编码之后,敌对示例的预测标签可能是3或4。虽然我们可以使用这个编码的例子来攻击成功,但对抗性例子的健壮性已经被破坏了。视频编码的过程会给视频添加不可预测的噪声。
因此,视频样本的预测的标签将偏离到未知的地方。在讨论目标攻击时,将进一步论证和讨论这一现象。
此外,该方法可以使用较小的扰动来获得最高的成功率。我们认为这就是把扰动放在整数空间中的优点。当我们将扰动置于整数空间中时,归一化后的数据将更像正态样本,并与干净样本具有相同的分布。 如果扰动被放置在浮点数空间中,则每次更新的幅度对于我们来说难以控制。在造成舍入损失的同时,分布与原始样本不同并且也难以控制。在攻击幅度的控制上,难度会更大。
需要注意的是,在实验中,我们的方法在不同的视频编码方式下会改变扰动幅度,而其他方法不会改变。这是因为,在我们的对抗示例生成方法中,我们考虑了视频编码。因此,不同的视频编码方法会带来不同的攻击性能。The previous methods did not take this into consideration, only the video coding test was added in the final link, so there will be no change.
targeted attack
在编码前,两种方法的攻击效果都比较好,攻击幅度也差不多。这是非常合理的,因为有针对性的攻击的难度明显大于无针对性的攻击。为了达到更好的攻击效果,攻击扰动的幅度会比无目标攻击略大,但仍保持在相对较小的水平。我们的方法具有稍微高的攻击成功率。
经过视频压缩编码后,稀疏攻击的攻击成功率大大降低,我们的方法具有很好的抗编码效果,编码后的攻击性能几乎没有下降。

对比表2和表4可以发现,视频压缩编码后,目标攻击的性能下降更为明显。我们认为这是因为目标攻击比无目标攻击更难。为了使对抗样本最终分类到我们选择的标签中,所需的扰动会更加精细。 值得一提的是,在无目标攻击中,我们选取了原始输出中分类置信度次高的标签作为优化目标,这也在一定程度上降低了无目标攻击的难度。当所需扰动越细时,视频压缩编码对附加扰动的破坏越大。
任何细微的变化都可能影响最终的攻击效果。在无目标攻击中,由于选择了置信度次高的标签作为优化目标,使得攻击变得更加容易。抵抗视频压缩编码的能力也将变得更强。这是因为原始模型对该样本的判断非常接近所选标签,并且附加视频压缩编码的影响可以在很大程度上忽略。
Visual concealment:

For the visual effect, we will convert the perturbation in the floating-point number space to RGB space, and all perturbations less than 0 are displayed with their absolute value. And the final line is the difference between a non-coded image and a coded image, and we also converted it to RGB space for better visual. Since the added perturbation is too small, we must expand each perturbation by five times to improve its visual effect, and we gray it out to get a more obvious contrast effect. We also expand the difference image between the coded frame and non-coded frame by five times.
从图中可以清楚地看到,我们的方法生成的对抗性例子在空间的稀疏性和对抗性扰动的幅度方面都上级以前的方法。值得注意的是,视频编码前后,图像数据发生了明显的变化和差异,
this difference is the cause of the attack ability loss of the adversarial sample.。但在我们的对抗性例子中,这种现象并没有发生。这是因为我们的对抗示例在生成过程中优化了这种编码损失,最小化了编码前后的差异,并提高了对抗示例的鲁棒性。
Multimedia transmission experiment
本节将展示网络多媒体传输情况下 the life cycle problem of adversarial video examples。当一段视频在互联网上传播时,比如上传到YouTube、Tiktok等视频网站,或者通过WeChat、Facebook等社交软件分享,这些网站和软件会对视频进行压缩编码,可以降低带宽需求。

conclusion
探讨了视频压缩编码对视频对抗实例的影响,提出了一种方法generating video adversarial examples that can resist attack ability against video compression encoding。该算法是一种基于优化的方法,以added perturbation、class loss,
and loss caused by video compression encoding引起的loss为优化目标。在UCF101数据集上的一系列实验表明,视频对抗样本易受视频压缩编码的攻击,该方法在视觉隐蔽性、攻击成功率、抗视频编码能力等方面均优先于已有的工作。未来,我们将在两个方面进行探索。首先,利用视频压缩编码的特点来检测和防御视频对抗性实例。第二,我们可以综合各种视频压缩编码方法的特点,设计一种通用的视频对抗实例生成方法。
[1]Sparse adversarial perturbations for videos. AAAI 2019
论文阅读 X3D: Expanding Architectures for Efficient Video Recognition
X3D: Expanding Architectures for Efficient Video Recognition
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition CVPR 2020
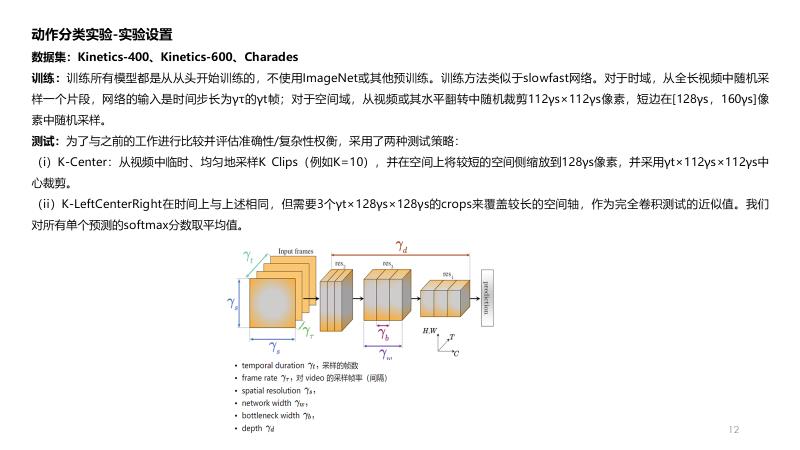
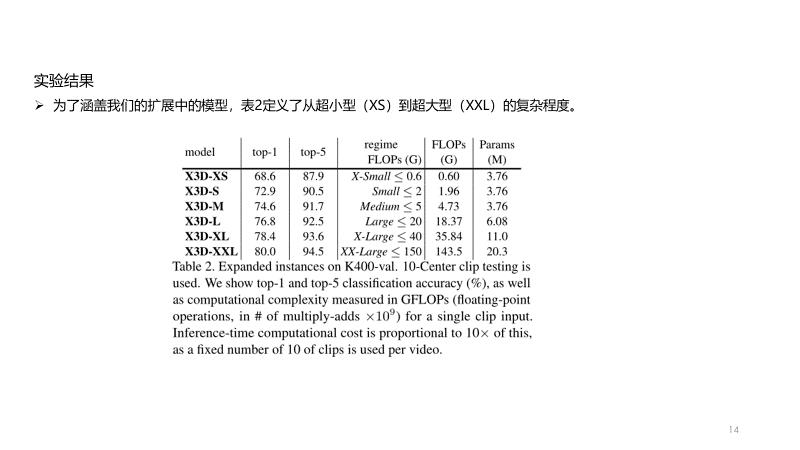
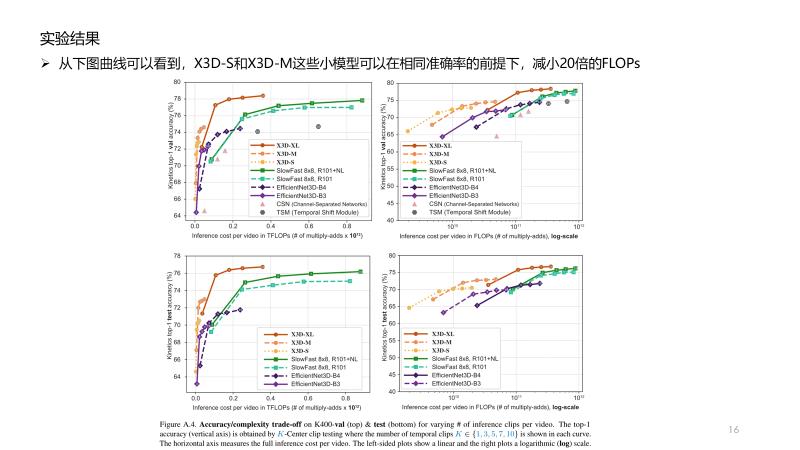
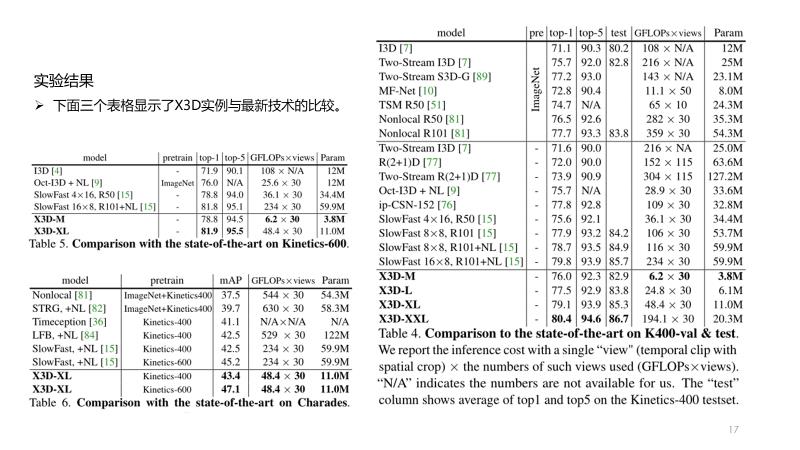
task
将二维方法拓展到三维的视频识别方法
阅读记录











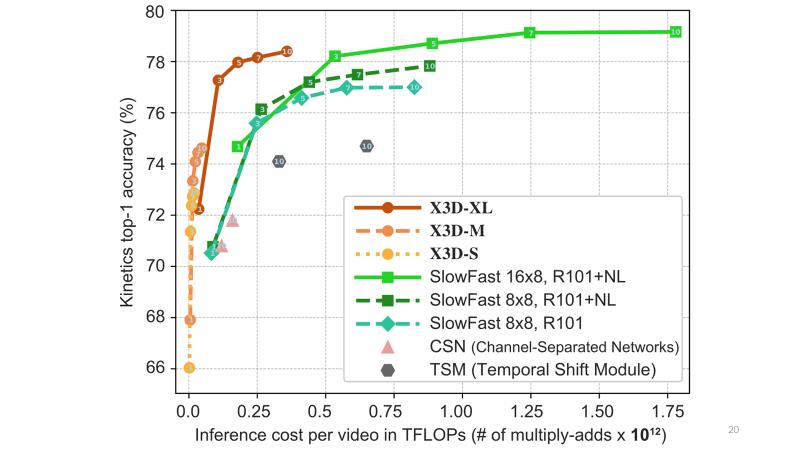


说明
以上内容均为作者本人平时阅读并且汇报使用,内容整理全凭个人理解,如有侵权,请联系我;内容如有错误,欢迎留言交流。转载请注明出处,并附有原文链接,谢谢!
此外,我还喜欢用ipad对论文写写画画(个人英文阅读的水平有限),做一些断句、重点勾画等,有兴趣大家可以按需下载:链接

更多论文分享,请参考: 深度学习相关阅读论文汇总(持续更新)
以上是关于论文阅读Research on video adversarial attack with long living cycle的主要内容,如果未能解决你的问题,请参考以下文章
Research on Micro-Expression Spotting Method Based on Optical Flow Features
论文阅读 Video Transformer Network
论文阅读 Video Transformer Network
论文阅读 X3D: Expanding Architectures for Efficient Video Recognition
论文阅读 X3D: Expanding Architectures for Efficient Video Recognition
论文阅读 X3D: Expanding Architectures for Efficient Video Recognition