论文阅读 Video Transformer Network
Posted WXiujie123456
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读 Video Transformer Network相关的知识,希望对你有一定的参考价值。
Video Transformer Network
ICCV 2021
task
基于变压器的视频识别框架VTN
阅读记录

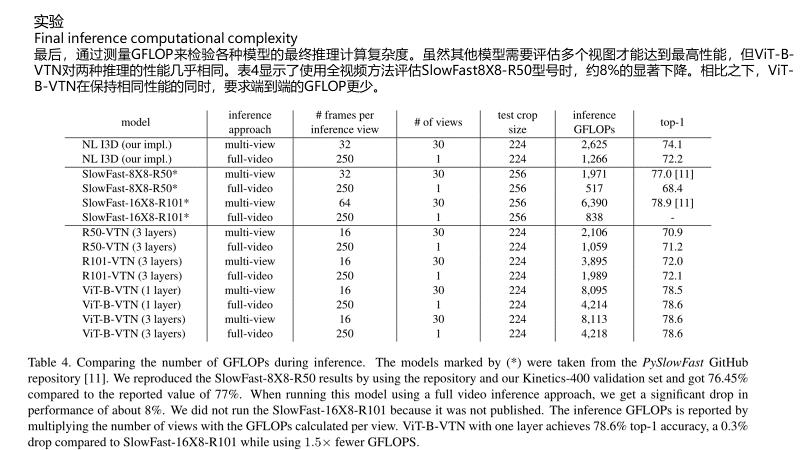
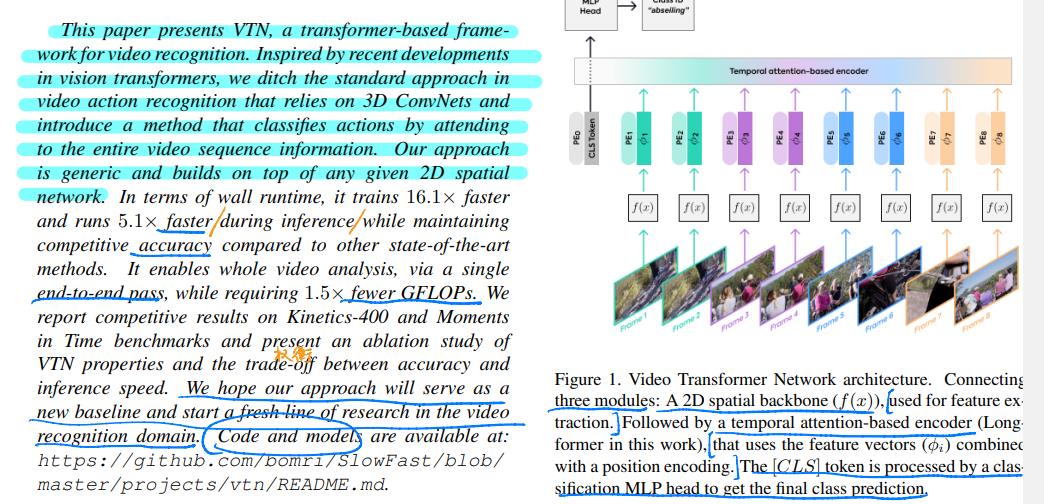
本文介绍了基于变压器的视频识别框架VTN。受视觉Transformer最新发展的启发,我们摒弃了依赖3D ConvNets的视频动作识别标准方法,引入了一种通过关注整个视频序列信息对动作进行分类的方法。我们的方法是通用的,建立在任何给定的二维空间网络之上。
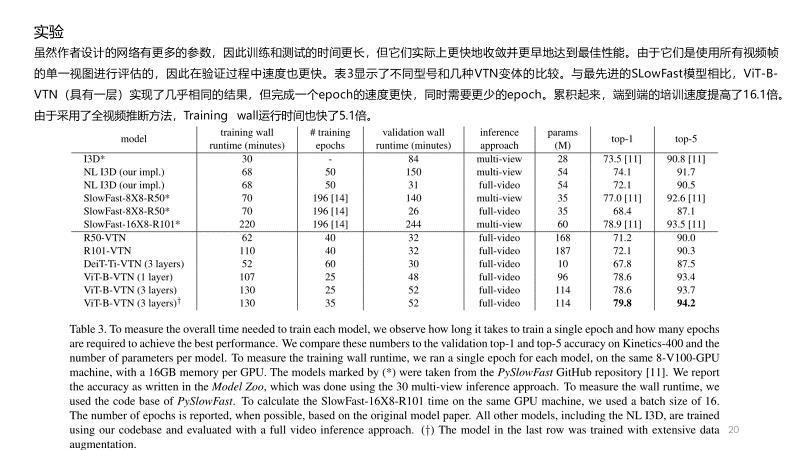
就wall运行时间而言,与其他最先进的方法相比,它在推理过程中的训练速度快16.1倍和测试速度快5.1倍,同时保持了具有竞争力的准确性。它可以通过一次端到端的传输实现整个视频分析,同时需要减少1.5倍的GFLOP。我们报告了Kinetics-400竞争结果,并对VTN特性以及准确性和推断速度之间的权衡进行了研究。我们希望我们的方法将成为视频识别领域的一个新的基线,并开始一系列新的研究。

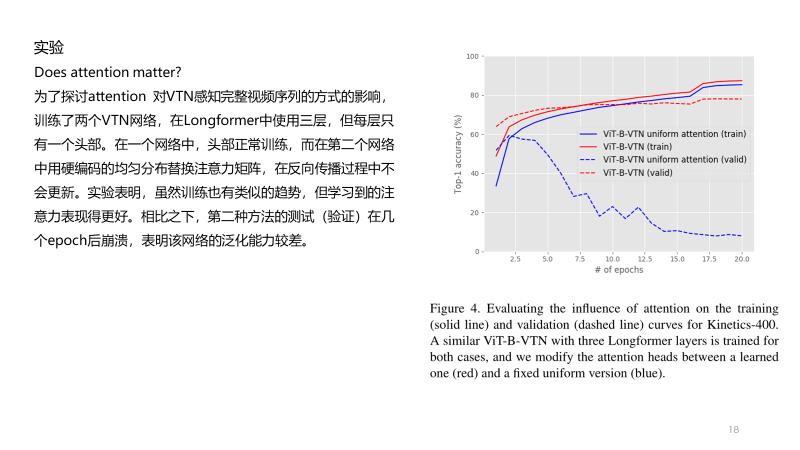
在最近的视频动作识别研究中,常用的方法是使用基于3D的网络,如双流CNN、I3D、Non-local Neural Networks (NLN) 、SLOWFAST、X3D等。在推理过程中,由于增加了时间维度,这些网络受到内存和运行时的限制,只能使用小空间尺度和低帧数的片段。
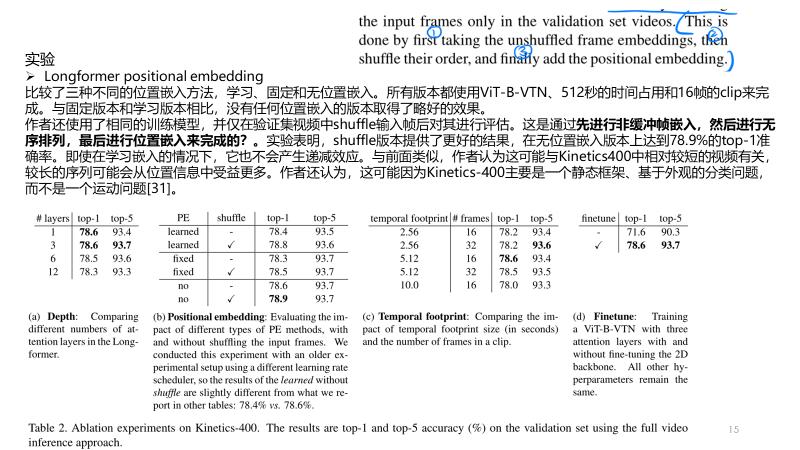
SlowFast[14]、 X3D[13]使用了multi-view inference的方法,即一种或几种带有空间裁剪的时间剪辑。这种multi-view inference的做法有些违反直觉,尤其是在处理长视频时。一种更直观的方法是在决定动作之前“查看”整个视频上下文,而不是只查看其中的一小部分。
图2:从观看类别的视频中均匀提取的16帧。在视频的多个部分中,实际动作模糊或不可见;在许多view中,这可能会导致错误的动作预测。专注于视频中最相关的片段的潜力是一种强大的能力。然而,在使用短片段训练的方法中,完整视频推理产生的性能较差。此外,由于硬件、内存和运行时方面的原因,它在实践中也受到限制。
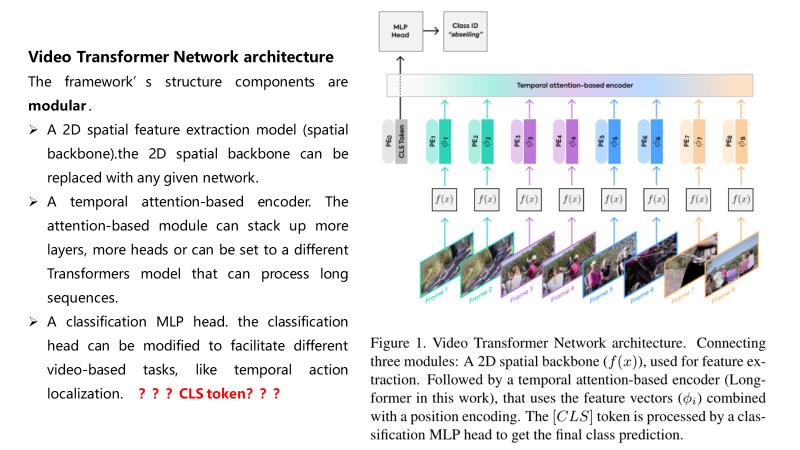
关于CLS token的问题
ViT引入了class token机制,其目的:因为transformer输入为一系列的patch embedding,输出也是同样长的序列patch feature,但是最后要总结为一个类别的判断,简单方法可以用avg pool,把所有的patch feature都考虑算出image feature。但是作者没有用这种方式,而是引入一个类似flag的class token,其输出特征加上一个线性分类器就可以实现分类。其中训练的时候,class token的embedding被随机初始化并与pos embedding相加,因此从图可以看到输入transformer的时候【0】处补上一个新embedding,最终输入长度N+1.
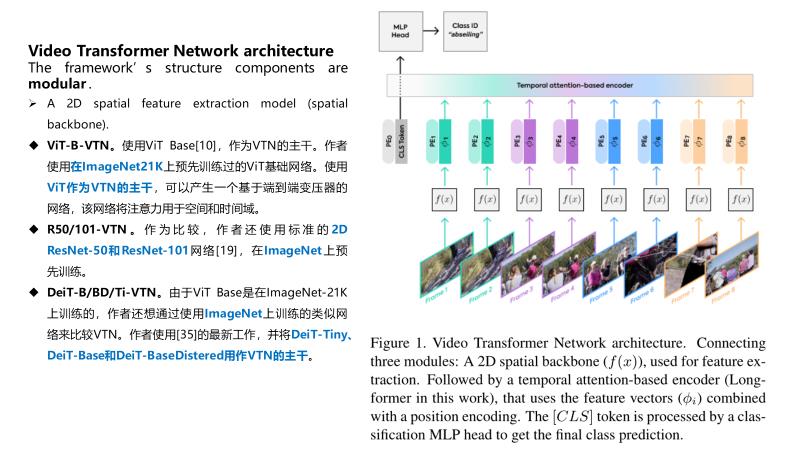
作为学习的特征提取模块运行。
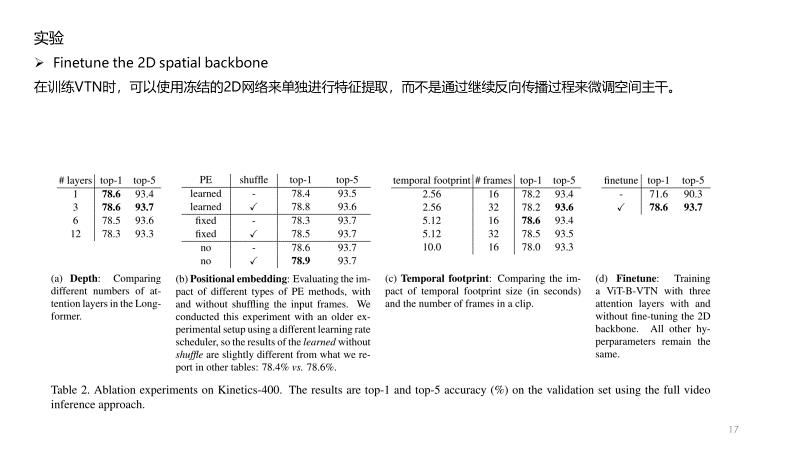
它可以是在2D图像上工作的任何网络,无论是深度图像还是浅层图像、预训练图像还是非预训练图像、卷积图像或基于变压器的图像。它的权重可以固定(预先训练)或在学习过程中训练。

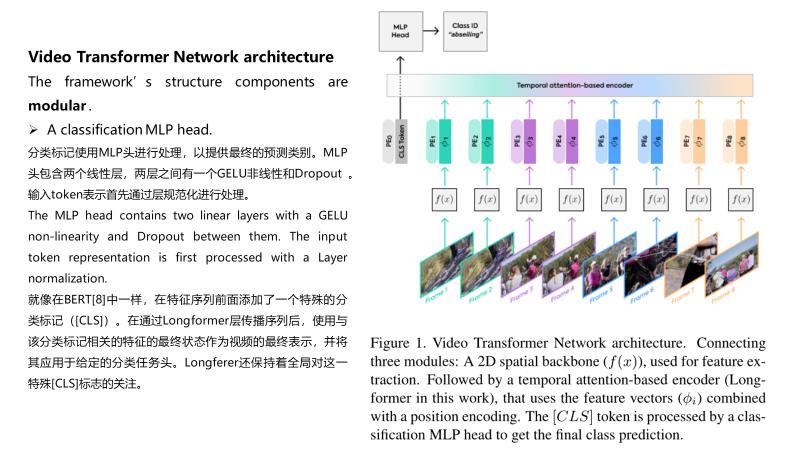



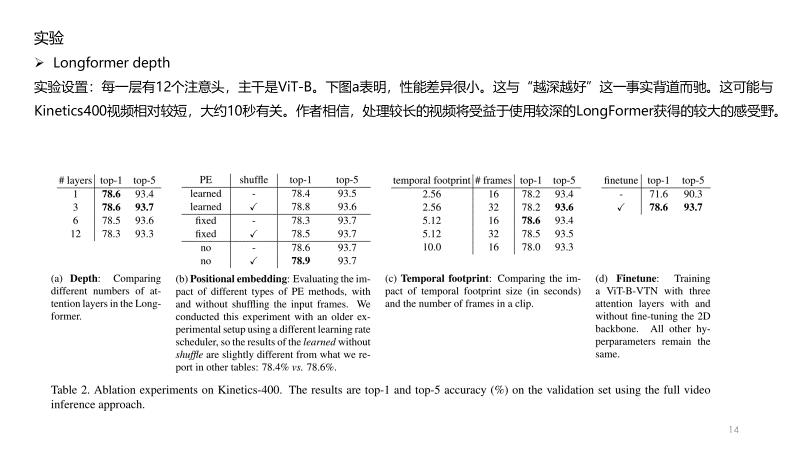




说明
以上内容均为作者本人平时阅读并且汇报使用,内容整理全凭个人理解,如有侵权,请联系我;内容如有错误,欢迎留言交流。转载请注明出处,并附有原文链接,谢谢!
此外,我还喜欢用ipad对论文写写画画(个人英文阅读的水平有限),做一些断句、重点勾画等,有兴趣大家可以按需下载:链接
更多论文分享,请参考: 深度学习相关阅读论文汇总(持续更新)
以上是关于论文阅读 Video Transformer Network的主要内容,如果未能解决你的问题,请参考以下文章