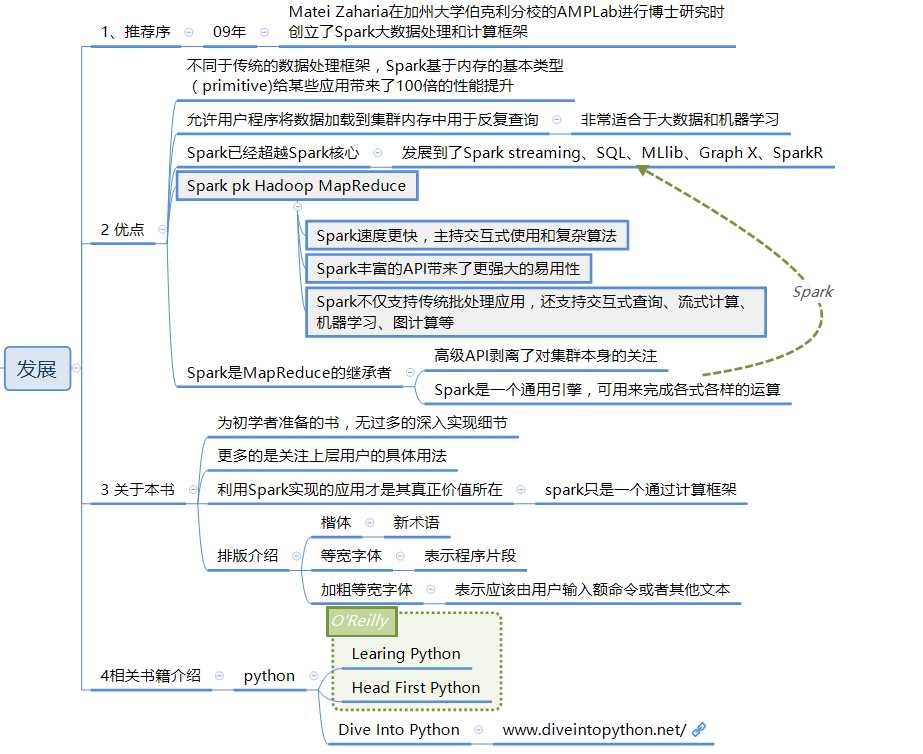
==Spark的发展介绍==
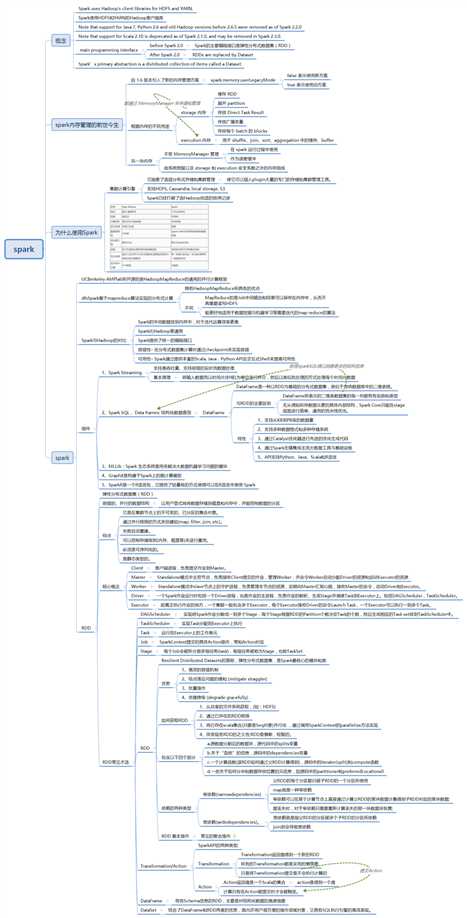
==一个大一统的软件栈==
Spark核心
计算引擎
对由很多计算任务组成的、运行在多个工作机器或者是一个计算集群上的应用调度、分发以及监控的计算引擎
速度快、通用
Spark项目包含多个密切组成的组件
优点1:软件栈中所有的程序库和高级组件都可以从下层的改进中获益
优点2:运行整个软件栈的代价变小了
优点3:能够构建出无缝整合不同处理模型的应用
Spark的各个组件

Spark Core
实现了Spark的基本功能
包含:任务调度、内存管理、错误恢复、与存储系统交互等模块
包含:对弹性分布式数据集RDD的API定义
RDD表示
分布在多个计算机节点上可以并行操作的元素集合
是Spark的主要编程对象
SparkCore提供了创建和操作这些集合的多个API
SparkSQL
用来操作结构化数据的程序包
通过它我们可以使用
SQL or Apache Hive版本的SQL方言(HQL)查询数据
支持多种数据源
比如:Hive表、Parquet、JSON等
为Spark提供了一个SQL接口
实在Spark1.0中被引用的
Spark Streaming
Spark提供的对实时数据进行流式计算的组件
提供了用来操作数据流的API
与SparkCore中的RDD API高度对应
底层设计来看:它支持与Spark Core同级别的容错性、吞吐量以及可伸缩性
MLlib
机器学习ML功能的程序库
提供了很多种机器学习算法
分类
回归
聚类
协同过滤等
GraphX
用来操作图的程序库
可以进行并行的图计算
扩展了Spark的RDD API
用来创建一个顶点和边都包含任意属性的有向图
集群管理器
支持在各种集群管理器(cluster manager)上运行
包括:Hadoop YARN、Apache Mesos、以及Spark自带的独立调器
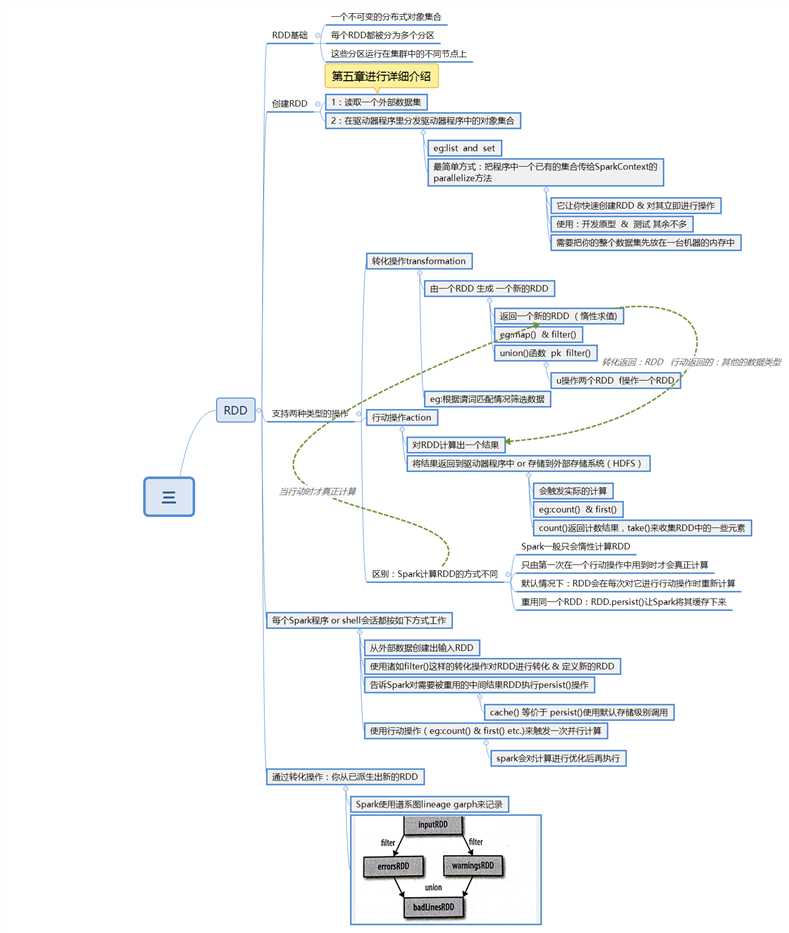
行动操作

RDD
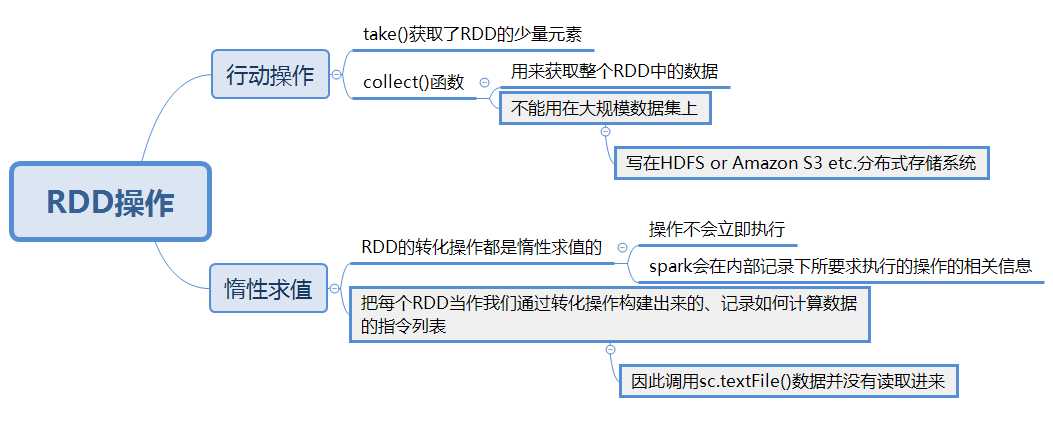
Spark传递函数

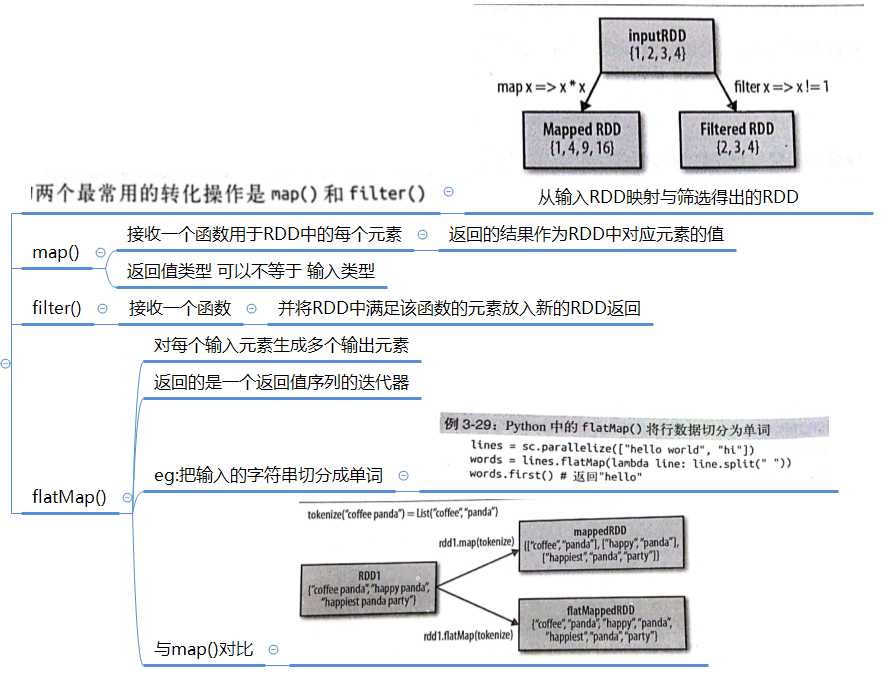
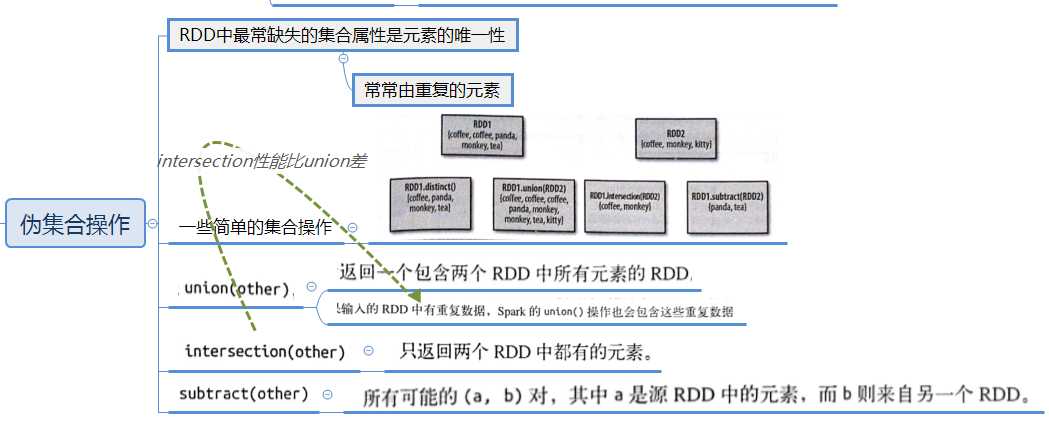
常见的转化操作