Spark入门,概述,部署,以及学习(Spark是一种快速通用可扩展的大数据分析引擎)
Posted --->别先生<---
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark入门,概述,部署,以及学习(Spark是一种快速通用可扩展的大数据分析引擎)相关的知识,希望对你有一定的参考价值。
1:Spark的官方网址:http://spark.apache.org/
1:Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
2:Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
3:Spark是一种通用的大数据计算框架,一种通用的大数据快速处理引擎,正如传统大数据技术,hadoop的mapreduce,hive引擎,以及Storm流式实时计算引擎等等。
4:Spark包含了大数据领域常见的各种计算框架,比如Spark core用于离线计算,Spark SQL用于交互式查询,Spark Streaming用于实时流式计算,Spark MLlib用于机器学习,Spark GraphX用于图计算。
5:Spark主要用户大数据的计算,而Hadoop以后主要用于大数据的存储(比如,hdfs,hive,hbase),以及资源调度(yarn)。
6:Spark的核心,其实就是一种新型的大数据框架,而不是对Hadoop的替代,可以基于Hadoop上存储的大数据进行计算(比如:Hdfs,Hive)。Spark只是替代Hadoop的一部分,也就是Hadoop的计算框架Mapreduce,Hive查询引擎。但是Spark本身是不提供大数据的存储的。
7:对比:Spark Core(Spark SQL,Spark Streaming,Spark ML,Spark Graphx,Spark R);和Hadoop(Hive,Storm,Mahout,Griph);
2:Spark特点:
1 1:特点一:快 2 与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。 3 2:特点二:易用 4 Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。 5 3:特点三:通用 6 Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。 7 4:特点四:兼容性 8 Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
Spark的算子分为两类,一类叫做Transformation转换,一类叫做Action动作。Transformation延迟执行,当计算任务触发Action时候才会真正开始计算。
3:Spark的部署安装(上传jar,过程省略,记得安装好jdk。):
下载网址:http://www.apache.org/dyn/closer.lua/spark/ 或者 http://spark.apache.org/downloads.html
Spark的解压缩操作,如下所示:
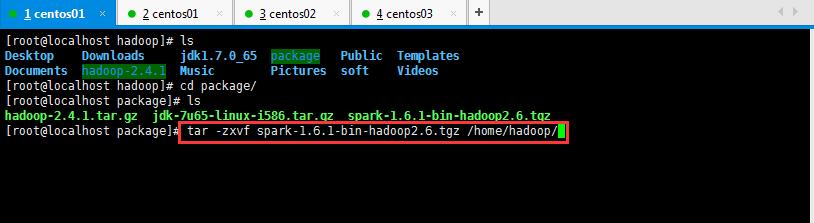
哈哈哈,犯了一个低级错误,千万记得加-C,解压安装包到指定位置。是大写的哦;
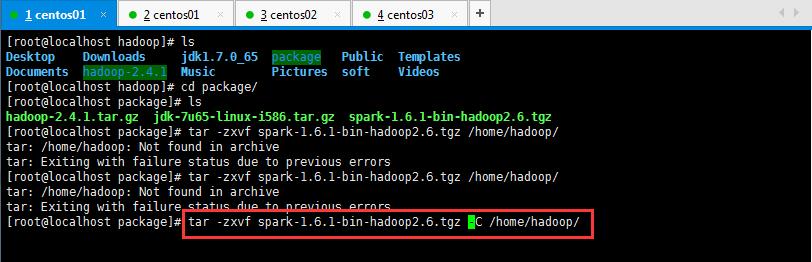
然后呢,进入到Spark安装目录,进入conf目录并重命名并修改spark-env.sh.template文件,操作如下所示:

将spark-env.sh.template 名称修改为spark-env.sh,然后在该配置文件中添加如下配置,之后保存退出:
1 [root@localhost conf]# mv spark-env.sh.template spark-env.sh
具体操作如下所示:

也可以将scala和hadoop的目录以及自定义内存大小进行定义,如下所示:
注意:可以去spark的sbin目录里面的start-master.sh使用more start-master.sh命令来查找spark-env.sh里面对应的端口号,或者找其他的.sh文件找对应的值;
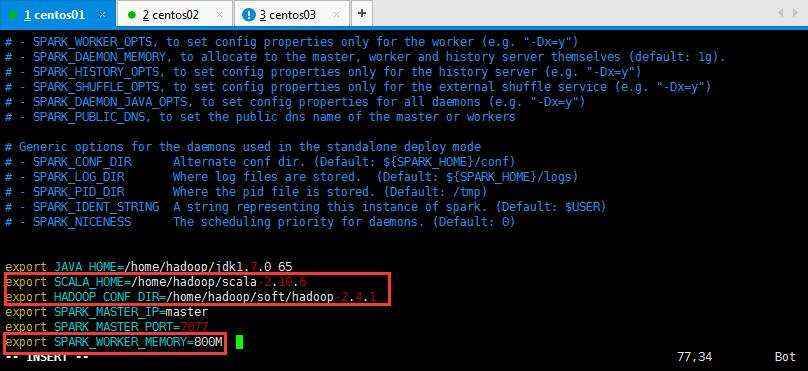
或者添加更多的配置,这样初始化不会使用默认的配置,更多配置自己可以看注释进行添加:
export JAVA_HOME=/home/hadoop/soft/jdk1.7.0_65 export SCALA_HOME=/home/hadoop/soft/scala-2.10.6 export HADOOP_HOME=/home/hadoop/soft/hadoop-2.6.4
export HADOOP_CONF_DIR=/home/hadoop/soft/hadoop-2.6.4/etc/hadoop export SPARK_MASTER_IP=slaver1 export SPARK_MASTER_PORT=7077 export SPARK_MASTER_WEBUI_PORT=8080 export SPARK_WORKER_PORT=7078 export SPARK_WORKER_WEBUI_PORT=8081 export SPARK_WORKER_CORES=1 export SPARK_WORKER_MEMORY=800M export SPARK_WORKER_INSTANCES=1
具体操作如下所示:
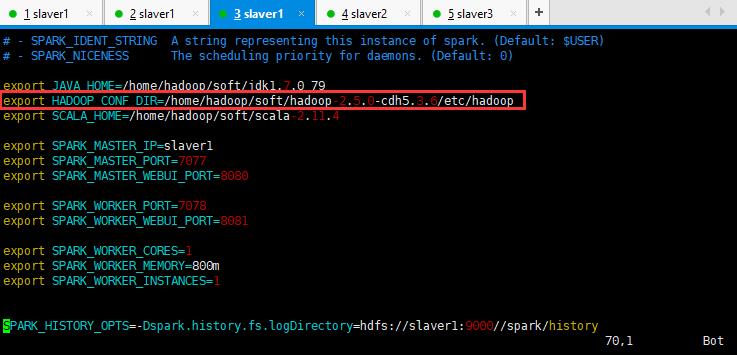
下面这个图片的hadoop_conf_dir目录出现错误,注意修改:

然后呢,重命名并修改slaves.template文件,如下所示:
1 [root@localhost conf]# mv slaves.template slaves
在该文件中添加子节点所在的位置(Worker节点),操作如下所示,然后保存退出:

如果想记录日志,可以将log4j.properties.template修改为log4j.properties,用于记录日志,查看自己的错误信息:
[root@master conf]# cp log4j.properties.template log4j.properties
将配置好的Spark拷贝到其他节点上:
1 [root@localhost hadoop]# scp -r spark-1.6.1-bin-hadoop2.6/ slaver1:/home/hadoop/ 2 [root@localhost hadoop]# scp -r spark-1.6.1-bin-hadoop2.6/ slaver2:/home/hadoop/
Spark集群配置完毕,目前是1个Master,2个Work(可以是多个Work),在master节点上启动Spark集群:

注意:启动的过程中,如果进入到spark的sbin目录直接输入start-all.sh是不行的,为什么呢,因为之前配置hadoop是配置的全局的,所以呢,这里不能直接输入start-all.sh命令来启动spark;可以输入sbin/start-all.sh启动spark;
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://master:8080/:
可以查看一下是否启动起来,如下所示:
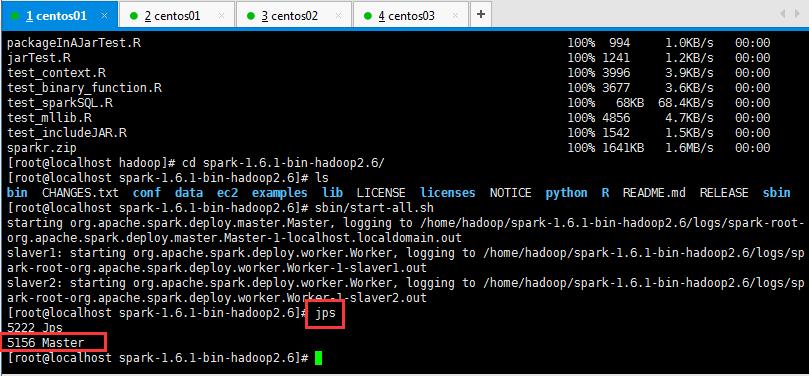
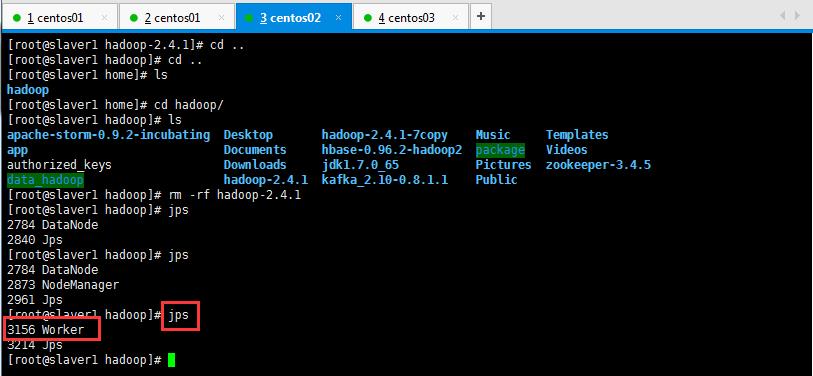
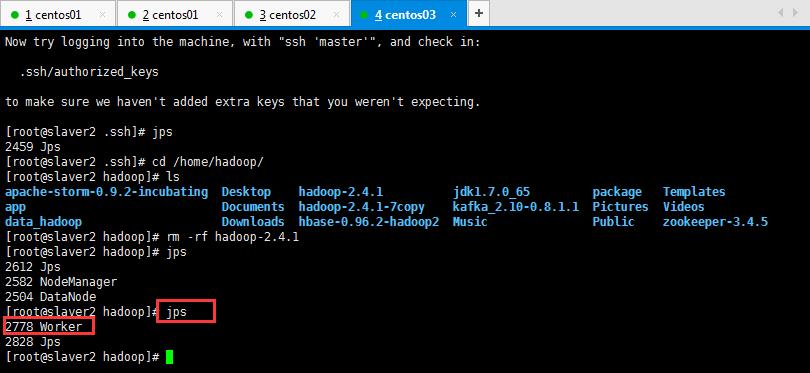
然后在页面可以查看信息,如下所示,如果浏览器一直加载不出来,可能是防火墙没关闭(service iptables stop暂时关闭,chkconfig iptables off永久关闭):

到此为止,Spark集群安装完毕。
1 但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠,配置方式比较简单,如下所示: 2 Spark集群规划:node1,node2是Master;node3,node4,node5是Worker 3 安装配置zk集群,并启动zk集群,然后呢,停止spark所有服务,修改配置文件spark-env.sh, 4 在该配置文件中删掉SPARK_MASTER_IP并添加如下配置: 5 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk1,zk2,zk3 -Dspark.deploy.zookeeper.dir=/spark" 6 1.在node1节点上修改slaves配置文件内容指定worker节点 7 2.在node1上执行sbin/start-all.sh脚本,然后在node2上执行sbin/start-master.sh启动第二个Master
4:执行Spark程序(执行第一个spark程序,如下所示):
执行如下所示,然后就报了一大推错误,由于错误过多就隐藏了,方便以后脑补:
1 [root@master bin]# ./spark-submit \\ 2 > --class org.apache.spark.examples.SparkPi \\ 3 > --master spark://master:7077 \\ 4 > --executor-memory 1G \\ 5 > --total-executor-cores 2 \\ 6 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/l 7 lib/ licenses/ logs/ 8 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar \\ 9 > 100
或者如下所示也可:
[root@master spark-1.6.1-bin-hadoop2.6]# bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512M --total-executor-cores 2 /home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar 10
错误如下所示,由于太长了就折叠起来了:


1 [root@master hadoop]# cd spark-1.6.1-bin-hadoop2.6/ 2 [root@master spark-1.6.1-bin-hadoop2.6]# ls 3 bin conf ec2 lib licenses NOTICE R RELEASE 4 CHANGES.txt data examples LICENSE logs python README.md sbin 5 [root@master spark-1.6.1-bin-hadoop2.6]# bi 6 bind biosdecode biosdevname 7 [root@master spark-1.6.1-bin-hadoop2.6]# cd bin/ 8 [root@master bin]# ls 9 beeline pyspark run-example2.cmd spark-class.cmd spark-shell spark-submit 10 beeline.cmd pyspark2.cmd run-example.cmd sparkR spark-shell2.cmd spark-submit2.cmd 11 load-spark-env.cmd pyspark.cmd spark-class sparkR2.cmd spark-shell.cmd spark-submit.cmd 12 load-spark-env.sh run-example spark-class2.cmd sparkR.cmd spark-sql 13 [root@master bin]# ./spark-submit \\ 14 > --class org.apache.spark.examples.SparkPi \\ 15 > --master spark://master:7077 \\ 16 > --executor-memory 1G \\ 17 > --total-executor-cores 2 \\ 18 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/l 19 lib/ licenses/ logs/ 20 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar \\ 21 > 100 22 Using Spark\'s default log4j profile: org/apache/spark/log4j-defaults.properties 23 18/01/02 19:44:01 INFO SparkContext: Running Spark version 1.6.1 24 18/01/02 19:44:05 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 25 18/01/02 19:44:06 INFO SecurityManager: Changing view acls to: root 26 18/01/02 19:44:06 INFO SecurityManager: Changing modify acls to: root 27 18/01/02 19:44:06 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root) 28 18/01/02 19:44:09 INFO Utils: Successfully started service \'sparkDriver\' on port 41731. 29 18/01/02 19:44:11 INFO Slf4jLogger: Slf4jLogger started 30 18/01/02 19:44:11 INFO Remoting: Starting remoting 31 18/01/02 19:44:12 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.3.129:49630] 32 18/01/02 19:44:12 INFO Utils: Successfully started service \'sparkDriverActorSystem\' on port 49630. 33 18/01/02 19:44:13 INFO SparkEnv: Registering MapOutputTracker 34 18/01/02 19:44:13 INFO SparkEnv: Registering BlockManagerMaster 35 18/01/02 19:44:13 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-c154fc3f-8552-49d4-9a9a-1ce79dba74d7 36 18/01/02 19:44:13 INFO MemoryStore: MemoryStore started with capacity 517.4 MB 37 18/01/02 19:44:14 INFO SparkEnv: Registering OutputCommitCoordinator 38 18/01/02 19:44:15 INFO Utils: Successfully started service \'SparkUI\' on port 4040. 39 18/01/02 19:44:15 INFO SparkUI: Started SparkUI at http://192.168.3.129:4040 40 18/01/02 19:44:15 INFO HttpFileServer: HTTP File server directory is /tmp/spark-2b7d6514-96ad-4999-a7d0-5797b4a53652/httpd-fda58f3c-9d2e-49df-bfe7-2a72fd6dab39 41 18/01/02 19:44:15 INFO HttpServer: Starting HTTP Server 42 18/01/02 19:44:15 INFO Utils: Successfully started service \'HTTP file server\' on port 42161. 43 18/01/02 19:44:18 INFO SparkContext: Added JAR file:/home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar at http://192.168.3.129:42161/jars/spark-examples-1.6.1-hadoop2.6.0.jar with timestamp 1514951058742 44 18/01/02 19:44:19 INFO AppClient$ClientEndpoint: Connecting to master spark://master:7077... 45 18/01/02 19:44:28 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20180102194427-0000 46 18/01/02 19:44:30 INFO Utils: Successfully started service \'org.apache.spark.network.netty.NettyBlockTransferService\' on port 58259. 47 18/01/02 19:44:30 INFO NettyBlockTransferService: Server created on 58259 48 18/01/02 19:44:30 INFO BlockManagerMaster: Trying to register BlockManager 49 18/01/02 19:44:30 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.3.129:58259 with 517.4 MB RAM, BlockManagerId(driver, 192.168.3.129, 58259) 50 18/01/02 19:44:30 INFO BlockManagerMaster: Registered BlockManager 51 18/01/02 19:44:31 INFO AppClient$ClientEndpoint: Executor added: app-20180102194427-0000/0 on worker-20180103095039-192.168.3.131-39684 (192.168.3.131:39684) with 1 cores 52 18/01/02 19:44:31 INFO SparkDeploySchedulerBackend: Granted executor ID app-20180102194427-0000/0 on hostPort 192.168.3.131:39684 with 1 cores, 1024.0 MB RAM 53 18/01/02 19:44:31 INFO AppClient$ClientEndpoint: Executor added: app-20180102194427-0000/1 on worker-20180103095039-192.168.3.130-46477 (192.168.3.130:46477) with 1 cores 54 18/01/02 19:44:31 INFO SparkDeploySchedulerBackend: Granted executor ID app-20180102194427-0000/1 on hostPort 192.168.3.130:46477 with 1 cores, 1024.0 MB RAM 55 18/01/02 19:44:33 INFO SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0 56 18/01/02 19:44:37 INFO SparkContext: Starting job: reduce at SparkPi.scala:36 57 18/01/02 19:44:38 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:36) with 100 output partitions 58 18/01/02 19:44:38 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:36) 59 18/01/02 19:44:38 INFO DAGScheduler: Parents of final stage: List() 60 18/01/02 19:44:38 INFO DAGScheduler: Missing parents: List() 61 18/01/02 19:44:38 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32), which has no missing parents 62 18/01/02 19:44:41 INFO AppClient$ClientEndpoint: Executor updated: app-20180102194427-0000/0 is now RUNNING 63 18/01/02 19:44:41 INFO AppClient$ClientEndpoint: Executor updated: app-20180102194427-0000/1 is now RUNNING 64 18/01/02 19:44:44 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes 65 18/01/02 19:44:45 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1904.0 B, free 1904.0 B) 66 18/01/02 19:44:46 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1216.0 B, free 3.0 KB) 67 18/01/02 19:44:46 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.3.129:58259 (size: 1216.0 B, free: 517.4 MB) 68 18/01/02 19:44:46 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006 69 18/01/02 19:44:46 INFO DAGScheduler: Submitting 100 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32) 70 18/01/02 19:44:46 INFO TaskSchedulerImpl: Adding task set 0.0 with 100 tasks 71 18/01/02 19:45:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 72 18/01/02 19:45:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 73 18/01/02 19:45:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 74 18/01/02 19:45:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 75 18/01/02 19:46:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 76 18/01/02 19:46:07 INFO AppClient$ClientEndpoint: Executor updated: app-20180102194427-0000/0 is now EXITED (Command exited with code 1) 77 18/01/02 19:46:07 INFO SparkDeploySchedulerBackend: Executor app-20180102194427-0000/0 removed: Command exited with code 1 78 18/01/02 19:46:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 79 18/01/02 19:46:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 80 18/01/02 19:46:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 81 18/01/02 19:47:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 82 18/01/02 19:47:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 83 18/01/02 19:47:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 84 18/01/02 19:47:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 85 ^C18/01/02 19:47:58 INFO SparkContext: Invoking stop() from shutdown hook 86 18/01/02 19:47:58 INFO SparkUI: Stopped Spark web UI at http://192.168.3.129:4040 87 18/01/02 19:47:58 INFO DAGScheduler: Job 0 failed: reduce at SparkPi.scala:36, took 201.147338 s 88 18/01/02 19:47:58 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:36) failed in 191.823 s 89 Exception in thread "main" 18/01/02 19:47:58 ERROR LiveListenerBus: SparkListenerBus has already stopped! Dropping event SparkListenerStageCompleted(org.apache.spark.scheduler.StageInfo@10d7390) 90 18/01/02 19:47:58 ERROR LiveListenerBus: SparkListenerBus has already stopped! Dropping event SparkListenerJobEnd(0,1514951278747,JobFailed(org.apache.spark.SparkException: Job 0 cancelled because SparkContext was shut down)) 91 18/01/02 19:47:58 INFO SparkDeploySchedulerBackend: Shutting down all executors 92 org.apache.spark.SparkException: Job 0 cancelled because SparkContext was shut down 93 at org.apache.spark.scheduler.DAGScheduler$$anonfun$cleanUpAfterSchedulerStop$1.apply(DAGScheduler.scala:806) 94 at org.apache.spark.scheduler.DAGScheduler$$anonfun$cleanUpAfterSchedulerStop$1.apply(DAGScheduler.scala:804) 95 at scala.collection.mutable.HashSet.foreach(HashSet.scala:79) 96 at org.apache.spark.scheduler.DAGScheduler.cleanUpAfterSchedulerStop(DAGScheduler.scala:804) 97 at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onStop(DAGScheduler.scala:1658) 98 at org.apache.spark.util.EventLoop.stop(EventLoop.scala:84) 99 at org.apache.spark.scheduler.DAGScheduler.stop(DAGScheduler.scala:1581) 100 at org.apache.spark.SparkContext$$anonfun$stop$9.apply$mcV$sp(SparkContext.scala:1740) 101 at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1229) 102 at org.apache.spark.SparkContext.stop(SparkContext.scala:1739) 103 at org.apache.spark.SparkContext$$anonfun$3.apply$mcV$sp(SparkContext.scala:596) 104 at org.apache.spark.util.SparkShutdownHook.run(ShutdownHookManager.scala:267) 105 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(ShutdownHookManager.scala:239) 106 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:239) 107 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:239) 108 at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1765) 109 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply$mcV$sp(ShutdownHookManager.scala:239) 110 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:239) 111 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:239) 112 at scala.util.Try$.apply(Try.scala:161) 113 at org.apache.spark.util.SparkShutdownHookManager.runAll(ShutdownHookManager.scala:239) 114 at org.apache.spark.util.SparkShutdownHookManager$$anon$2.run(ShutdownHookManager.scala:218) 115 at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:54) 116 at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:620) 117 at org.apache.spark.SparkContext.runJob(SparkContext.scala:1832) 118 at org.apache.spark.SparkContext.runJob(SparkContext.scala:1952) 119 at org.apache.spark.rdd.RDD$$anonfun$reduce$1.apply(RDD.scala:1025) 120 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150) 121 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111) 122 at org.apache.spark.rdd.RDD.withScope(RDD.scala:316) 123 at org.apache.spark.rdd.RDD.reduce(RDD.scala:1007) 124 at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:36) 125 at org.apache.spark.examples.SparkPi.main(SparkPi.scala) 126 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) 127 at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) 128 at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) 129 at java.lang.reflect.Method.invoke(Method.java:606) 130 at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731) 131 at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181) 132 at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206) 133 at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121) 134 at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) 135 ^C18/01/02 19:48:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 136 ^C^C^C^C^C 137 18/01/02 19:48:07 WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(0,Command exited with code 1)] in 1 attempts 138 org.apache.spark.rpc.RpcTimeoutException: Futures timed out after [120 seconds]. This timeout is controlled by spark.rpc.askTimeout 139 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 140 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 141 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 142 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 143 at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:76) 144 at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:101) 145 at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:77) 146 at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.removeExecutor(CoarseGrainedSchedulerBackend.scala:359) 147 at org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend.executorRemoved(SparkDeploySchedulerBackend.scala:144) 148 at org.apache.spark.deploy.client.AppClient$ClientEndpoint$$anonfun$receive$1.applyOrElse(AppClient.scala:186) 149 at org.apache.spark.rpc.netty.Inbox$$anonfun$process$1.apply$mcV$sp(Inbox.scala:116) 150 at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:204) 151 at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) 152 at org.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215) 153 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 154 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 155 at java.lang.Thread.run(Thread.java:745) 156 Caused by: java.util.concurrent.TimeoutException: Futures timed out after [120 seconds] 157 at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219) 158 at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:223) 159 at scala.concurrent.Await$$anonfun$result$1.apply(package.scala:107) 160 at scala.concurrent.BlockContext$DefaultBlockContext$.blockOn(BlockContext.scala:53) 161 at scala.concurrent.Await$.result(package.scala:107) 162 at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75) 163 ... 12 more 164 ^C^C^C^C^C^C^C^C^C 165 166 167 ^C^C^C^C^C^C^C^C^C^C^C18/01/02 19:48:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 168 ^C^C^C^C^C^C^C^C^C^C18/01/02 19:48:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 169 18/01/02 19:48:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 170 18/01/02 19:49:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 171 18/01/02 19:49:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 172 18/01/02 19:49:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 173 18/01/02 19:49:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 174 18/01/02 19:49:58 WARN NettyRpcEndpointRef: Error sending message [message = StopExecutors] in 1 attempts 175 org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout 176 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 177 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 178 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 179 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 180 at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) 181 at scala.util.Try$.apply(Try.scala:161) 182 at scala.util.Failure.recover(Try.scala:185) 183 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 184 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 185 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 186 at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) 187 at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) 188 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 189 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 190 at scala.concurrent.Promise$class.complete(Promise.scala:55) 191 at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) 192 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 193 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 194 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 195 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) 196 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) 197 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 198 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 199 at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) 200 at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) 201 at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) 202 at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) 203 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 204 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 205 at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) 206 at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) 207 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) 208 at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) 209 at java.util.concurrent.FutureTask.run(FutureTask.java:262) 210 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) 211 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) 212 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 213 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 214 at java.lang.Thread.run(Thread.java:745) 215 Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds 216 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) 217 ... 7 more 218 18/01/02 19:50:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 219 18/01/02 19:50:10 WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(0,Command exited with code 1)] in 2 attempts 220 org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout 221 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 222 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 223 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 224 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 225 at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) 226 at scala.util.Try$.apply(Try.scala:161) 227 at scala.util.Failure.recover(Try.scala:185) 228 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 229 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 230 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 231 at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) 232 at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) 233 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 234 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 235 at scala.concurrent.Promise$class.complete(Promise.scala:55) 236 at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) 237 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 238 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 239 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 240 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) 241 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) 242 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 243 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 244 at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) 245 at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) 246 at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) 247 at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) 248 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 249 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 250 at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) 251 at scala.concurrent.impl.Promise$DefaultPromise.t以上是关于Spark入门,概述,部署,以及学习(Spark是一种快速通用可扩展的大数据分析引擎)的主要内容,如果未能解决你的问题,请参考以下文章