David Durant,2011/10/05
原文链接:http://www.sqlservercentral.com/articles/Stairway+Series/72441/ 该系列 本文是“Stairway系列:SQL Server索引的阶梯”的一部分 索引是数据库设计的基础,并告诉开发人员使用数据库关于设计者的意图。不幸的是,当性能问题出现时,索引往往被添加为事后考虑。这里最后是一个简单的系列文章,应该使他们快速地使任何数据库专业人员“快速” 在整个阶段,我们经常说某个查询以某种方式执行,我们引用生成的查询计划来支持我们的陈述。 Management Studio显示的估计和实际查询计划可以帮助您确定索引的收益或缺乏。因此,这个级别的目的是让您充分了解查询计划,您可以: ?当你阅读这个阶梯时,验证我们的断言。 ?确定您的索引是否有益于您的查询。 有许多关于阅读查询计划的文章,其中包括MSDN库中的一些文章。这里我们不打算扩大或取代它们。事实上,我们会在这个层面提供其中的许多链接/参考。显示图形执行计划(http://msdn.microsoft.com/zh-cn/library/ms178071.aspx)是一个很好的开始。其他有用的资源包括Grant Fritchey的书,SQL Server执行计划(以电子书形式免费提供)和Fabiano Amorim关于在查询计划输出中找到的各种运算符的Simple-Talk文章系列(http://www.simple-talk .COM /作家/法比亚诺 - 阿莫林/)。 图形查询计划 查询计划是SQL Server执行查询的一组指令。 SQL Server Management Studio将以文本,图形或XML格式显示查询计划。例如,考虑以下简单的查询:
SELECT LastName, FirstName, MiddleName, Title
FROM Person.Contact
WHERE Suffix = ‘Jr.‘
ORDER BY Title
这个查询的计划可以看成如图1所示。
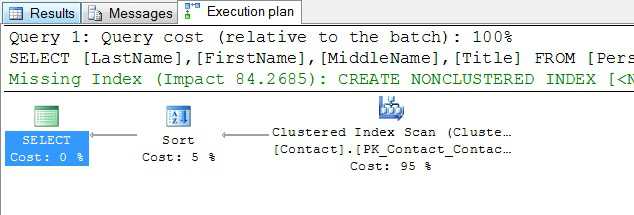
图1 - 图形格式的实际查询计划 或者,它可以被视为文本:
|--Sort(ORDER BY:([AdventureWorks].[Person].[Contact].[Title] ASC)) |--Clustered Index Scan(OBJECT:([AdventureWorks].[Person].[Contact].[PK_Contact_ContactID]), WHERE:([AdventureWorks].[Person].[Contact].[Suffix]=N‘Jr.‘))
或者作为一个XML文档,像这样开始:
查询计划的显示可以请求如下: ?要请求图形查询计划,请使用Management Studio的SQL编辑器工具栏,它具有“显示估计执行计划”和“包括实际执行计划”按钮。 “显示估计执行计划”选项立即显示所选TSQL代码的查询计划图,而不执行查询。 “包括实际执行计划”按钮是一个开关,一旦您选择了此选项,您执行的每个查询批次都将显示新查询计划图表以及结果和消息。这个选项可以在图1中看到。 ?要请求文本查询计划,请使用SET SHOWPLAN_TEXT ON语句。打开文本版本将关闭图形版本,不会执行任何查询。 ?要查看XML版本,请右键单击图形版本,然后从上下文菜单中选择“显示执行计划XML”。 对于这个级别的其余部分,我们将重点放在图形视图上,因为它通常提供对计划的最快理解。对于查询计划,一张图片通常胜过千言万语。 阅读图形查询计划 图形查询计划通常从右到左读取;最右边的图标表示数据收集流中的第一步。这通常是访问堆或索引。你不会看到这里使用的单词表;相反,您将看到聚簇索引扫描或堆扫描。这是首先看看哪些索引,如果有的话,正在使用。 图形查询计划中的每个图标代表一个操作。有关可能的图标的其他信息,请参阅http://msdn.microsoft.com/zh-cn/library/ms175913.aspx上的图形执行计划图标 连接操作的箭头表示行,从一个操作流出并进入下一个操作。 将鼠标放在图标或箭头上会导致显示其他信息。 不要把操作当作一个步骤,因为这意味着一个操作必须在下一个操作开始之前完成。这不一定是真的。例如,当WHERE子句被评估时,也就是说,当一个Filter操作被执行时,行被一次评估一个;不是一次全部。在下一行到达过滤器操作之前,行可以移动到下一个操作。另一方面,排序操作必须在第一行移动到下一个操作之前全部完成。 使用一些额外的信息 图形查询计划显示两个不属于计划本身的可能有用的信息;建议的指标和每个操作的相对成本。 在上面的示例中,建议的索引(以绿色显示并按空间要求截断)建议在联系人表的后缀列上使用非聚簇索引;包括标题,名字,中间名和姓氏的列。 这个计划的每个操作的相对成本告诉我们,排序操作是总成本的5%,而表扫描是95%的工作。因此,如果我们想提高这个查询的性能,我们应该解决表扫描,而不是排序;这就是为什么建议索引。如果我们创建推荐的索引,像这样:
CREATE NONCLUSTERED INDEX IX_Suffix ON Person.Contact
(
Suffix
)
INCLUDE ( Title, FirstName, MiddleName, LastName )
然后重新运行查询,我们的读数从569降到3; 而下面显示的新查询计划显示了原因。

新的非聚集索引(索引键为Suffix)具有“WHERE Suffix =‘Jr.”条目聚集在一起; 因此,检索数据所需IO的减少。 因此,与之前计划中的排序操作相同的排序操作现在占查询总成本的75%以上,而不是仅仅是原来成本的5%。 因此,最初的计划需要75/5 = 15倍的工作量来收集与当前计划相同的信息。 由于我们的WHERE子句只包含一个等号运算符,所以我们可以通过将Title列移入索引键来改进我们的索引,如下所示:
IF EXISTS (SELECT * FROM sys.indexes
WHERE OBJECT_ID = OBJECT_ID(N‘Person.Contact‘)
AND name = N‘IX_Suffix‘)
DROP INDEX IX_Suffix ON Person.Contact
CREATE NONCLUSTERED INDEX IX_Suffix ON Person.Contact
(
Suffix, Title
)
INCLUDE ( FirstName, MiddleName, LastName )
现在,所需的条目仍然聚集在索引内,并且在每个集群内,它们都是按照请求的顺序; 如新查询计划所示,如图2所示。
图2-重建非聚集索引后的查询计划
该计划现在显示,排序操作不再需要。 在这一点上,我们可以放弃我们非常有利的覆盖指数。 这将恢复联系人表格的方式,当我们开始时, 当我们进入我们的下一个主题时,这是我们希望的状态。
查看并行流
如果两行可以并行处理,它们将在图形显示中上下显示。 箭头的相对宽度表示在每个流中正在处理的行数。 例如,以下加入,扩展了以前的查询以包含销售信息:
SELECT C.LastName, C.FirstName, C.MiddleName, C.Title
, H.SalesOrderID, H.OrderDate
FROM Person.Contact C
JOIN Sales.SalesOrderHeader H ON H.ContactID = C.ContactID
WHERE Suffix = ‘Jr.‘
ORDER BY Title
查询计划如图3所示。
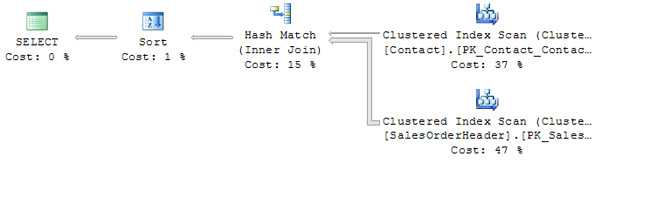
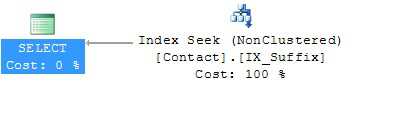
图3 - JOIN的查询计划 快速查看计划告诉我们一些事情: ?两张桌子同时被扫描。 ?大部分工作用于扫描表格。 ?出来的更多行或SalesOrderHeader表比出Contact表更多。 ?两个表格没有聚集成相同的序列; 因此将每个SalesOrderHeader行与其联系人行进行匹配将需要额外的努力。 在这种情况下,使用哈希匹配操作。 (关于哈希的更多信息。) ?排序所选行所需的工作量可以忽略不计。 即使是单独的行流也可以分解成单独的较少行的流,以利用并行处理。 例如,如果我们将上述查询中的WHERE子句更改为WHERE Suffix为NULL。 更多的行将被返回,95%的Contact行有NULL后缀。 新的查询计划反映了这一点,如图4所示。
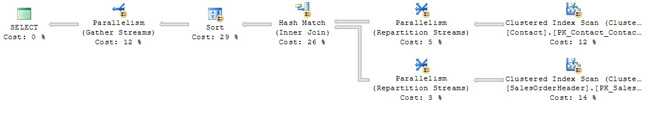
图4 - 一个并行查询计划 新的计划也向我们展示了联系人行数的增加,导致匹配和排序操作成为此查询的关键路径。如果要提高绩效,就要先攻击这两个行动。再次,包含列的索引将有所帮助。 像大多数连接一样,我们的例子通过外键/主键关系连接两个表。其中的一个表Contact(联系人)按ContactID进行排序,ContactID也恰好是其主键。在另一个表中,SaleOrderHeader,ContactID是一个外键。由于ContactID是一个外键,因此ContactID访问的SaleOrderHeader数据请求(例如我们的联接示例)可能是常见的业务需求。这些请求将受益于ContactID上的索引。 无论何时索引一个外键列,总是问自己,如果有的话,列应该作为包含列添加到索引中。在我们的例子中,我们只有一个查询,而不是一系列的查询来支持。因此,我们唯一包含的列将是OrderDate。为了支持针对SaleOrderHeader表的一系列面向ContactID的查询,我们会根据需要在索引中包含更多的SaleOrderHeader列以支持这些附加查询。 我们的CREATE INDEX语句是:
CREATE NONCLUSTERED INDEX IX_ContactID ON Sales.SalesOrderHeader
(
ContactID
)
INCLUDE ( OrderDate )
而执行我们的SalesOrderHeader和Contact信息连接的新计划如图5所示。
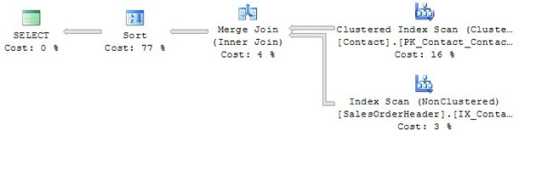
图5 - 计划在每个表上使用支持索引的JOIN查询 因为两个输入流现在都由连接谓词列ContactID进行排序;查询的JOIN部分可以在不分割流的情况下完成,也不需要散列;从而将工作负荷的26 + 5 + 3 = 34%减少到工作负荷的4%。 排序,推送和散列 许多查询操作要求在执行操作之前将数据分组。这些包括DISTINCT,UNION(意味着不同),GROUP BY(及其各种聚合函数)和JOIN。通常,SQL Server将使用以下三种方法之一来实现这个分组,第一个方法需要您的帮助: ?愉快地发现数据已经预先分类到分组序列中。 ?通过执行散列操作对数据进行分组。 ?将数据分类到分组顺序中。 预分类 索引是您预测数据的方式;即以经常需要的顺序向SQL Server提供数据。这就是为什么创建非聚簇索引(每个都包含列)都使我们以前的例子受益。实际上,如果将鼠标放在最近查询中的“合并连接”图标上,则会使用两个适当排序的输入流匹配行,并利用它们的排序顺序。会出现。这会通知您两个表/索引的行使用内存和处理器时间的绝对最小值进行连接。适当的排序输入是一个很棒的短语,当鼠标悬停在查询计划图标上时,它会验证您选择的索引。 哈希 如果传入数据的顺序不合适,SQL Server可能会使用散列操作对数据进行分组。哈希是一种可以使用大量内存的技术,但通常比分类更有效。在执行DISTINCT,UNION和JOIN操作时,散列与排序相比有一个优势,即单个行可以传递到下一个操作,而不必等待所有传入行被散列。但是,在计算分组聚合时,必须先读取所有输入行,然后才能将任何聚合值传递给下一个操作。 散列信息所需的内存量与所需组的数量直接相关。因此,需要散列来解决:
SELECT Gender, COUNT(*)
FROM NewYorkCityCensus
GROUP BY Gender
只需要很少的记忆,因为只会有两组; 女性和男性,无论输入行的数量。 另一方面:
SELECT LastName, FirstName, COUNT(*)
FROM NewYorkCityCensus
GROUP BY LastName, FirstName
会导致大量的群体,每个群体都需要自己的记忆空间;可能消耗太多内存,哈希成为解决查询的不良技术。 有关查询计划散列的更多信息,请访问http://msdn.microsoft.com/en-us/library/ms189582.aspx。 排序 如果数据没有被预分类(索引),并且如果SQL Server认为哈希不能有效地完成,SQL Server将对数据进行排序。这通常是最不可取的选择。因此,如果在计划的早期出现“排序”图标,请检查是否可以改进索引。如果Sorticon出现在计划末尾附近,这可能意味着SQL Server将最终输出按ORDER BY子句所请求的顺序排序;并且该序列与用于解析查询的JOIN,GROUP BY和UNION的序列不同。通常情况下,你可以做些什么来避免这种情况。 结论 查询计划显示SQL Server打算使用或已经使用的方法来执行查询。它通过详细描述将要使用的操作,从操作到操作的行的流程以及涉及的并行性来实现。您将此信息视为文本,图形或XML显示。 ?图形计划显示每个操作的相对工作量。 ?图形计划可能会建议一个索引,以提高查询的性能。 ?了解查询计划将帮助您评估和优化索引设计