通过大卫·杜兰特,2011/10/05
该系列
本文是楼梯系列的一部分:SQL Server的阶梯索引
索引数据库设计的基础,告诉开发人员使用数据库设计者的意图。 不幸的是索引时往往是后加上的性能问题出现。 终于在这里是一个简单的系列文章,应该让任何数据库专业迅速“加速”
在整个楼梯,我们经常说一定执行查询以某种方式; 我们引用生成的查询计划来支持我们的声明。 管理工作室的估计和实际查询计划可以帮助您确定受益,或缺乏,你的索引。 因此,这个级别的目的是给你足够的理解的查询计划,您可以:
- 验证我们的断言,你读这个楼梯。
- 确定你的索引查询中受益。
有很多文章阅读查询计划,包括一些在MSDN图书馆。 这不是我们的意图来扩展或替换它们。 事实上,我们将提供链接/引用他们中的许多人在这个水平。 一个很好的起点是显示图形执行计划(http://msdn.microsoft.com/en-us/library/ms178071.aspx)。 其他有用的资源包括Grant Fritchey的书,SQL Server执行计划(免费电子书形式)和粒入球阿莫林系列Simple-Talk文章中的各种运营商查询计划输出(http://www.simple-talk.com/author/fabiano-amorim/)。
图形查询计划
查询计划的指令集的SQL Server之前执行一个查询。 SQL Server Management Studio将显示您的查询计划文本、图形或XML格式。 例如,考虑以下简单的查询:
选择姓,FirstName,MiddleName,标题&# 160;从Person.Contact在哪里后缀=“小”。命令标题
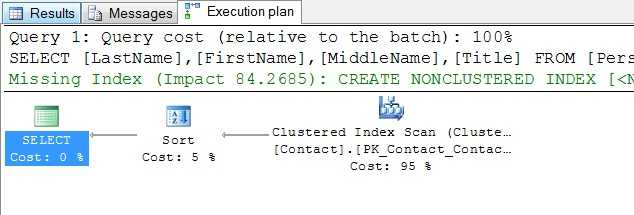
这个查询的计划可能被视为如图1所示。
或者,它可能被视为文本:
|——排序(按:[AdventureWorks]。[人]。(联系)。 [标题]ASC))
|——聚集索引
扫描(对象:([AdventureWorks],[人]。[联系]。[PK_Contact_ContactID]),
地点:([AdventureWorks],[人]。(接触)。(后缀)= N ‘Jr。‘))
或作为一个XML文档,开始是这样的:
显示查询计划的要求如下:
- 要求图形查询计划,使用管理工作室的SQL编辑器工具栏,“显示估计执行计划”和“包括实际执行计划”按钮。 “估计显示执行计划”选项显示的查询计划图选择立即TSQL代码,没有执行查询。 “包括实际执行计划”按钮是开关,一旦你选择了这个选项,每个查询批量执行将显示你在新标签页查询计划图,结果和消息。 这个选项可以看到如图1所示。
- 请求的文本查询计划,使用设置SHOWPLAN_TEXT声明。 把文本版本将关闭图形版本,不会执行任何查询。
- 查看XML版本,右击图形版本和选择从上下文菜单中“显示执行计划XML”。
在这个级别的其余部分,我们集中在图形视图,它通常提供了最快的计划的理解。 对查询计划,一幅是通常比一千字。
阅读图形查询计划
图形查询计划通常从右向左读; 正确的大部分图标(s)代表数据采集流程的第一步。 这通常是一堆或索引的访问。 你不会看到这个词表这里使用; 相反,你会看到聚集索引扫描或堆扫描。 这是第一个地方看看索引,如果有的话)。
每个图标代表一个图形查询计划操作。 附加信息的可能的图标,看到图形图标执行计划http://msdn.microsoft.com/en-us/library/ms175913.aspx
箭头连接的操作代表的行,流从一个操作。
把鼠标放在图标或箭头将导致额外的信息被显示。
不认为一个操作的步骤,这意味着一个操作之前必须完成下一个操作就可以开始了。 这并不一定是正确的。 例如,当一个WHERE子句评价,也就是说,当一个过滤器操作执行,行评估一次; 并不是所有的。 一行可以移动到下一个操作后续行到达之前过滤操作。 一个排序操作,另一方面,必须全部完成之前,第一行可以移动到下一个操作。
使用一些额外的信息
图形查询计划显示两个潜在的有用的信息,不是计划本身的一部分; 建议索引和每个操作的相对成本。
在上面的例子中,建议的索引,以绿色显示和截断的空间需求,建议非聚集索引联系表的后缀列; 包括列的标题,FirstName,MiddleName,姓。
每个操作的相对成本这个计划告诉我们,这种手术是总成本的5%,而95%的工作表扫描。 因此,如果我们想要改进这个查询的性能,我们应该解决表扫描,不是那种; 这就是为什么一个索引建议。 如果我们创建建议的索引,如下:
创建非聚集索引IX_Suffix在Person.Contact(后缀)包括(标题,FirstName,MiddleName,姓)
然后重新运行查询,我们读取从569下降到3; 和新的查询计划,如下所示,显示了为什么。

新非聚集索引的索引键后缀,“小后缀= ‘。 ”条目聚集在一起; 因此,减少体内需要检索数据。 因此,排序操作,同样操作,这是在前面的计划,现在代表查询的总成本的75%以上,而不是仅仅5%的成本。 因此所需的原计划75/5 = 15倍的工作量作为当前的计划收集相同的信息。
因为我们的WHERE子句只包含一个相等操作符,我们可以改善我们的指数更通过移动标题列索引键,如下所示:
该计划现在显示操作不再需要。 在这一点上,我们可以把高度有益的覆盖指数。 这个恢复联系表的是当我们开始; 这是我们想要的状态,当我们进入下一个话题。
查看平行流
如果两个流的行可以并行处理,他们会出现彼此上方和下方的图形化显示。 箭头指示的相对宽度有多少行被处理通过每个流。
例如,加入后,前面的查询扩展到包括销售信息:
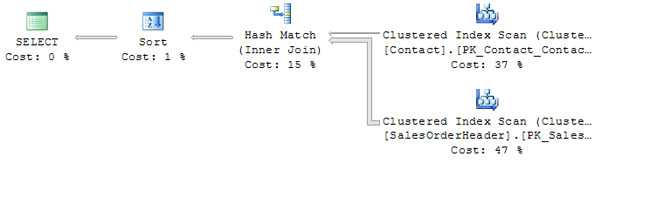
快速浏览一下这个计划告诉我们几件事:
- 两个表扫描在同一时间。
- 大部分工作是在扫描表。
- 更多的行或SalesOrderHeader比的表联系表。
- 这两个表不是聚集到相同的序列; 因此匹配每个SalesOrderHeader行了联系行需要额外的努力。 在这种情况下,哈希匹配操作使用。 (稍后将详细介绍散列)。
- 所需的努力所选行可以忽略不计。
甚至个人行流可以被分解成单独的流少行每个利用并行处理。 例如,如果我们改变上面的查询的WHERE子句到后缀是NULL。
将返回多行,随着越来越多的95%联系行有一个零后缀。 新查询计划反映了这一点,显示在图4
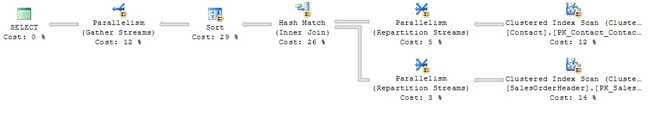
新计划也向我们表明,数量的增加联系行导致匹配和排序操作成为这个查询的关键路径。 如果我们需要改善其性能,我们必须首先攻击这两个操作。 再一次,与包括索引列会有所帮助。
像大多数连接,通过外键/我们的示例连接两个表主键的关系。 其中的一个表,联系,测序ContactID,这也恰好是它的主键。 在另一个表,SaleOrderHeader,ContactID是一个外键。 自ContactID是一个外键,请求SaleOrderHeader数据访问ContactID,比如我们加入的例子,可能是一个常见的业务需求。 这些请求将受益于一个索引ContactID。
每当你索引一个外键列,总是问自己什么,如果有的话,应该添加列,包括列的索引。 在我们的例子中,我们只有一个查询,而不是一个家庭支持的查询。 因此,我们将只包括列向数据库。 支撑一个家庭ContactID面向查询SaleOrderHeader表,我们将包括更多SaleOrderHeader索引中的列,根据需要支持那些额外的查询。
排序、预分类和散列
许多查询操作要求数据被分组之前可以执行的操作。 包括不同,联盟(这意味着不同的),组织(和它的各种聚合函数),并加入。 通常,SQL Server将使用三种方法来实现这一分组,第一个需要你的协助:
- 高兴地发现已经被预分类成分组的数据序列。
- 通过执行一组数据哈希操作。
- 数据分组的顺序进行排序。
预分类
预分类数据的索引你的方式; 也就是说,提供所需数据的SQL Server频繁序列。 这就是为什么非聚集索引的创建,每个包含包括列,我们之前的例子中受益。 事实上,如果你把你的鼠标合并连接图标在最近的查询,这个短语匹配行从两个适当排序输入流,利用他们的排序顺序。 就会出现。 这告诉你,这两个表的行/索引了使用的绝对最小内存和处理器时间。适当的排序输入是一个美妙的短语看到图标,当鼠标移到查询计划验证你所选择的索引。
哈希
如果传入的数据是不可取的序列,SQL服务器可能使用一个散列操作对数据进行分组。 哈希是一种技术,可以使用大量内存,但往往比排序更有效率。 当执行不同的联盟,连接操作,哈希的优势排序,个别行可以传递到下一个操作,而不必等待所有传入的行散列。 然而,当计算分组聚集所有输入行之前必须阅读任何聚合值可以传递到下一个操作。
排序
如果数据没有预分类(索引),如果SQL Server认为散列不能有效地完成,SQL Server将数据排序。 这通常是最理想的选择。 因此,如果一个排序图标出现在计划的早期,看看你可以改善你的索引。 如果排序计划的图标出现接近尾声,这可能意味着SQL Server排序最终的输出到请求序列ORDER by子句; 序列,这个序列不同于用于解决查询的连接、组,和工会。 通常,你可以避免这一点。
结论
查询计划显示了SQL Server的方法打算使用,或者使用,执行一个查询。 它是通过详细的操作将被使用,手术操作的行,和所涉及的并行性。
- 你把这个信息作为文本、图形或XML显示。
- 图形显示每个操作的相对工作量计划。
- 图形化的计划可能会建议索引可以提高查询的性能。
- 理解查询计划将帮助您评估和优化索引设计。