翻译 ——Reading Query Plans: Stairway to SQL Server Indexes Level 9
Posted Angular_JS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译 ——Reading Query Plans: Stairway to SQL Server Indexes Level 9相关的知识,希望对你有一定的参考价值。
Reading Query Plans: Stairway to SQL Server Indexes Level 9
By David Durant, 2011/10/05
原文链接:http://www.sqlservercentral.com/articles/Stairway+Series/72441/
The Series
本文是阶梯系列的一部分:SQL Server索引的阶梯。
索引是数据库设计的基础,并告诉开发人员使用数据库大量关于设计者的意图。不幸的是,当性能问题出现时,索引常常会作为事后考虑添加。这里最后是一系列简单的文章,应该能让数据库专业人员快速地与它们同步。
在整个步骤中,我们经常声明某个查询以某种方式执行;我们引用生成的查询计划来支持我们的语句。管理库显示估计和实际查询计划,可以帮助您确定索引的好处或不足。因此,这个级别的目的是让您对查询计划有足够的了解:
当你阅读这个阶梯时,验证我们的断言。
确定索引是否有利于查询。
有许多文章阅读查询计划,包括MSDN Library中的几个。我们不打算扩展或替换它们。事实上,我们将在这个级别为他们中的许多人提供链接/引用。开始的好地方是显示图形执行计划。(http://msdn.microsoft.com/en-us/library/ms178071.aspx). 其他有用的资源包括Grant Fritchey的书,SQL执行计划(可用于电子书免费),和Fabiano Amorim的一系列简单的对话篇关于各运营商发现您的查询计划的输出(http://www.simple-talk.com/author/fabiano-amorim/).
Graphical Query Plans
查询计划是SQLServer执行查询时所遵循的一组指令。SQLServer将以文本、图形或XML格式显示对您的查询计划。例如,考虑下面的简单查询:
SELECT LastName, FirstName, MiddleName, Title 
FROM Person.Contact
WHERE Suffix = \'Jr.\'
ORDER BY Title
这个查询的计划可以如图1所示。
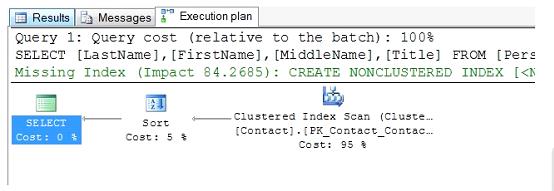
图1 -图形格式的实际查询计划
或者,可以将其视为文本:
|--Sort(ORDER BY:([AdventureWorks].[Person].[Contact].[Title] ASC))
|--Clustered Index
Scan(OBJECT:([AdventureWorks].[Person].[Contact].[PK_Contact_ContactID]),
WHERE:([AdventureWorks].[Person].[Contact].[Suffix]=N\'Jr.\'))
或者作为一个XML文档,从这样开始:

查询计划的显示可以如下所示要求:
要请求图形化查询计划,请使用管理室的SQL编辑器工具栏,该工具栏同时具有“显示估算执行计划”和“包含实际执行计划”按钮。“显示估计的执行计划”选项显示查询计划图立即为选定的TSQL代码,而不执行查询。“包含实际执行计划”按钮是一个开关,一旦您选择了这个选项,您执行的每个查询批将在一个新选项卡中显示查询计划图,以及结果和消息。这个选项可以在图1中看到。
要求文本查询计划,使用设置showplan_text声明。打开文本版本将关闭图形版本,不会执行任何查询。
要查看XML版本,在图形版本中右击,并从上下文菜单中选择“显示执行计划XML”。
对于这个级别的其余部分,我们专注于图形视图,因为它通常提供对计划的最快的理解。对于查询计划,一个图片通常比一千个词更好。
Reading Graphical Query Plans
图形查询计划通常从右向左读取;右最图标表示数据收集流中的第一步。这通常是访问堆或索引。您不会看到这里使用的字表;相反,您将看到集群索引扫描或堆扫描。这是第一个查看哪些索引(如果有的话)正在使用的地方。
图形化查询计划中的每个图标表示一个操作。在可能的图标的更多信息,参见图形执行计划在http://msdn.microsoft.com/en-us/library/ms175913.aspx图标
连接操作的箭头表示行,从一个操作流出并进入下一个操作。
将鼠标放在图标或箭头上会导致显示更多信息。
不要把操作看作步骤,因为这意味着在下一个操作开始之前必须完成一个操作。这不一定是真的。例如,当对WHERE子句进行求值时,也就是说,当执行筛选器操作时,一次一行求值,而不是一次求值。在后续行到达筛选器操作之前,一行可以移动到下一操作。另一方面,排序操作必须在第一行移动到下一操作之前全部完成。
Using Some Additional Information
图形化查询计划显示了两个可能有用的信息,这些信息不是计划本身的一部分;建议的索引和每个操作的相对成本。
在上面的例子中,所提出的指标,显示绿色和空间要求截断,建议联系表的后缀列的非聚集索引;包括标题、FirstName、MiddleName列,和姓。
这个计划的每个操作的相对成本告诉我们,排序操作占总成本的5%,而表扫描是工作的95%。因此,如果我们想改进这个查询的性能,我们应该处理表扫描,而不是排序,这就是为什么建议索引的原因。如果我们创建推荐索引,像这样:
CREATE NONCLUSTERED INDEX IX_Suffix ON Person.Contact
(
Suffix
)
INCLUDE ( Title, FirstName, MiddleName, LastName )
然后重新运行查询,我们的读取量从569下降到3;新的查询计划如下所示。

新的非聚集索引,其索引键后缀,有“后缀=“Jr.”条目聚集在一起;因此,在IO需要检索数据还原。因此,排序操作与前一个计划中的排序操作相同,现在代表了查询总成本的75%以上,而不是原来的5%。因此,原始计划需要75/5倍于当前计划收集相同信息的工作量的15倍。
由于我们的WHERE子句只包含一个相等运算符,因此我们可以通过将标题列移动到索引键来改进索引:
IF  EXISTS (SELECT * FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID(N\'Person.Contact\') AND name = N\'IX_Suffix\') DROP INDEX IX_Suffix ON Person.Contact CREATE NONCLUSTERED INDEX IX_Suffix ON Person.Contact ( Suffix, Title ) INCLUDE ( FirstName, MiddleName, LastName )
现在,所需的条目仍然在索引中聚集在一起,并且在每个集群中都在请求的序列中;如新的查询计划所示,如图2所示。

图2查询计划重建非聚簇索引后
现在计划表明不再需要排序操作。在这一点上,我们可以放弃高收益的覆盖指数。这将使联系人表恢复到我们开始时的状态;当我们进入下一个话题时,这是我们希望它处于的状态。
Viewing Parallel Streams
如果可以并行处理两行行,它们将在图形显示中彼此上下显示。箭头的相对宽度指示通过每个流处理的行数。
例如,下面的连接将前面的查询扩展为包含销售信息:
SELECT C.LastName, C.FirstName, C.MiddleName, C.Title , H.SalesOrderID, H.OrderDate FROM Person.Contact C JOIN Sales.SalesOrderHeader H ON H.ContactID = C.ContactID WHERE Suffix = \'Jr.\' ORDER BY Title
查询计划如图3所示。
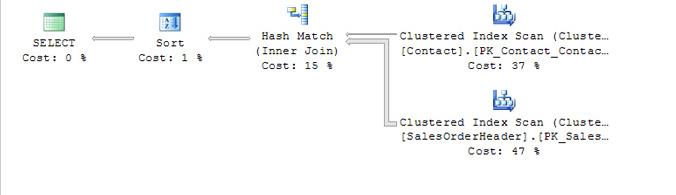
图3 -连接的查询计划
快速看一下这个计划会告诉我们一些事情:
两个表同时扫描。
大部分的工作都花在扫描桌子上。
多排出来或salesorderheader表超过了接触表。
两表不聚为同一序列;因此每个salesorderheader行行匹配的接触将需要额外的努力。在这种情况下,使用哈希匹配操作。(稍后再讨论散列)。
排序所选行所需的努力可以忽略不计。
即使是单独的行行也可以分解成单独的行,以利用并行处理。例如,如果我们将上面查询中的WHERE子句改为后缀为null的地方。
将返回更多的行,因为95%的联系人行有一个空后缀。新的查询计划反映了这一点,如图4所示。
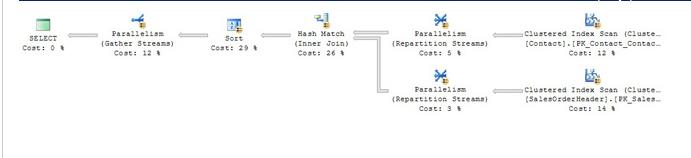
图4 -一个并行查询计划
新计划还向我们表明,接触行数的增加导致匹配和排序操作成为该查询的关键路径。如果我们需要提高它的性能,我们必须首先攻击这两种操作。同样,包含列的索引将有助于。
和大多数连接一样,我们的示例通过外键/主键关系连接两个表。其中的一个表,联系,是先由ContactID,这也正好是其主要的关键。在其他表中,saleorderheader ContactID是外键。自从ContactID是外键,用于数据访问的saleorderheader ContactID请求,如我加入的例子,可能是一种常见的业务需求。这些请求将从索引ContactID效益。
每当您对外键列进行索引时,总是问自己,如果列中包含了列,那么应该添加哪些索引。在我们的例子中,我们只有一个查询,而不是一个支持查询的家庭。因此,我们只包括将OrderDate列。支持一个家庭的ContactID导向对saleorderheader表查询,我们将包括在索引中,列的更多saleorderheader的需要,以支持那些额外的查询。
我们的创建索引语句是:
CREATE NONCLUSTERED INDEX IX_ContactID ON Sales.SalesOrderHeader
(
ContactID
)
INCLUDE ( OrderDate )
而新计划的执行我们的salesorderheader和联系信息加入如图5。

图5 -计划在每个表上有一个支持索引的连接查询
由于输入流现在是由谓词连接柱、ContactID;测序加入部分的查询可以做到不裂流无散列;从而减少26 + 5 + 3 = 34%的工作负载下4%的工作负载是什么。
Sorting, Presorting and Hashing
许多查询操作要求在执行操作之前将数据分组。这些包括明确的,联盟(这意味着不同),按组(及其各种聚合函数),并加入。通常,SQL Server将使用三种方法中的一种来实现这种分组,第一种方法需要您的帮助:
高兴地发现数据已经被预设为分组序列。
通过执行哈希操作将数据分组。
将数据排序到分组序列中。
Presorting
指标是你的预存数据;即在经常需要对SQL Server提供的数据序列。这就是为什么非聚集索引的创建,每个包含包含性列,得益于我们之前的例子。事实上,如果将鼠标放在最近查询中的合并连接图标上,则短语将使用两个适当排序的输入流匹配行,利用它们的排序顺序。将出现。这将告诉您两个表/索引的行是使用内存和处理器时间的绝对最小值来连接的。相应排序的输入是一个精彩的短语看到当鼠标查询计划的图标,它验证了你选择的指标。
Hashing
如果输入的数据不是理想的序列,SQLServer可以使用哈希操作对数据分组。哈希是一种可以使用大量内存的技术,但通常比排序效率更高。当执行不同,联盟,加入行动,散列在单个行可以通过下一步操作无需等待所有的输入行被哈希排序优势。但是,在计算分组聚集时,必须在将所有聚合值传递给下一个操作之前读取所有输入行。
散列信息所需的内存量与所需的组数直接相关。因此需要解析散列:
SELECT Gender, COUNT(*) FROM NewYorkCityCensus GROUP BY Gender 只需要很少的内存,因为只有两个组:女性和男性,不管输入行数。另一方面: SELECT LastName, FirstName, COUNT(*) FROM NewYorkCityCensus GROUP BY LastName, FirstName
将导致大量的组,每个组都需要在内存中拥有自己的空间;可能消耗了太多的内存,哈希成为解决查询的不可取的技术。
更多的查询计划哈希,访问http://msdn.microsoft.com/en-us/library/ms189582.aspx。
Sorting
如果数据没有预设(索引),如果SQL Server认为散列不能高效完成,SQL Server将数据排序。这通常是最不可取的选择。因此,如果在计划早期出现排序图标,请检查是否可以改进索引。如果Sorticon出现在计划结束时,这可能意味着SQL Server的ORDER BY子句的请求序列排序的最终输出;这种序列与序列被用来解决查询的连接、分组、和工会。通常,在这一点上你可以做些什么来避免这种排序。
Conclusion
查询计划显示SQL Server打算使用或使用的方法来执行查询。它通过详细说明将要使用的操作、从操作到操作的行流以及所涉及的并行性。
您将此信息视为文本、图形或XML显示。
图解显示每个操作的相对工作负荷。
图形化计划可能会提供一个索引来提高查询的性能。
理解查询计划有助于评估和优化索引设计。
以上是关于翻译 ——Reading Query Plans: Stairway to SQL Server Indexes Level 9的主要内容,如果未能解决你的问题,请参考以下文章
Express JS TypeError: Cannot read properties of undefined (reading '0') SQL query error
Paper Reading: How good are query optimizers, really?
高中必修3Module 3 Period 1 Reading— What Is a Tornado?翻译!急!急!!急!!!
And my grandpa is reading a newspaper.