ClickHouse存储结构及索引详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse存储结构及索引详解相关的知识,希望对你有一定的参考价值。
参考技术A本文基于ClickHouse 20.8.5.45版本编写,操作系统使用的是CentOS 7.5,主要介绍MergeTree表引擎的存储结构以及索引过程。
刚刚创建的表只在数据目录下生成了一个名为 test_merge_tree 文件夹(具体路径为data/default/test_merge_tree),并没有任何数据,接下来往该表里面插入一条数据,看看会生成哪些文件。
在test_merge_tree目录下使用tree命令可以看到刚刚的那条命令生成了一个名为 200002_1_1_0 的文件夹。
在介绍这些文件之前先介绍一下200002_1_1_0这个目录的命名规则
当分区发生合并时,新的分区目录名称命名规则将会在接下来介绍,这里不做详述。
在介绍这部分之前,需要先将min_compress_block_size配置改小,以方便分析mrk2和bin文件,其默认值为65535。
修改方法为在 users.xml 文件的 profiles 里面增加以下配置
修改完后重启clickhouse-server服务,然后再用以下命令查看是否修改成功
刚刚已经插入了一条数据,但是那一条数据不具有代表性,所以这次决定多插入几条数据再来分析。
上面这条命令产生了个新的分区目录 200002_2_2_0 ,此目录下的文件前面已经讲过,现在重点分析以下几个文件的存储格式
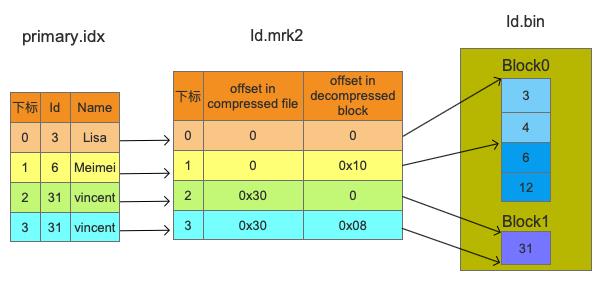
MergeTree表会按照主键字段生成primary.idx,用于加快表查询。前面创建表时使用的是(Id, Name)两个字段作为主键,所以每隔index_granularity行数据就会取(Id, Name)的值作为索引值,由于index_granularity被设置为2,所以每隔两行数据就会生成一个索引。也就是说会使用(3,\'Lisa\'), (6,\'Meimei\'), (31,\'vincent\')作为索引值。
这里我只介绍第一个索引(3,\'Lisa\')的存储格式,剩下的可以自己去梳理。Id是UInt64类型的,所以使用8字节来存储。从上图可以看出前8个字节为0x03,以小端模式来存储,接下来我们可以看到其它文件都是以小端模式来存储。Name是String类型,属于变长字段,所以会先使用1个字节来描述String的长度,由于Lisa的长度是4,所以第9个字节为0x04,再接下来就是Lisa的ASCII码。
mrk2文件格式比较固定,primary.idx文件中的每个索引在此文件中都有一个对应的Mark,Mark的格式如下图所示:
通过primary.idx中的索引寻找mrk2文件中对应的Mark非常简单,如果要寻找第n(从0开始)个index,则对应的Mark在mrk2文件中的偏移为n*24,从这个偏移处开始读取24 Bytes即可得到相应的Mark。
bin文件由若干个Block组成,由上图可知Id.bin文件中包含两个Block。每个Block主要由头部的Checksum以及若干个Granule组成,Block的格式如下图所示:
每个Block都会包含若干个Granule,具体有多少个Granule是由参数min_compress_block_size控制,每次Block中写完一个Granule的数据时,它会检查当前Block Size是否大于等于min_compress_block_size,如果满足则会把当前Block进行压缩然后写到磁盘中,不满足会继续等待下一个Granule。结合上面的INSERT语句,当插入第一个Granule(3, 4)时,数据的的size为16,由于16 < 24所以会等第二个Granule,当插入第二个Granule(6, 12)后数据的size为32,由于32 > 24所以会把(3, 4, 6, 12)压缩放到第一个Block里面。最后面的那个31由于是最后一条数据,就放到第二个Block里面。
partition.dat文件里面存放的是分区表达式的值,该分区表达式生成的值为200002,UInt32类型,转换成16进制就是0x00030d42。
minmax文件里面存放的是该分区里分区字段的最小最大值。分区字段Birthday的类型为Date,其底层由UInt16实现,存的是从1970年1月1号到现在所经过的天数。通过上面的INSERT语句我们可以知道Birthday的最小值为2000-02-03,最大值为2000-02-08。这两个时间转换成天数分别为10990和10995,再转换成16进制就是0x2aee和0x2af3。
属于同一个分区的不同目录,ClickHouse会在分区目录创建后的一段时间自动进行合并,合并之后会生成一个全新的目录,以前老的分区目录不会立马删除,而是在合并后过一段时间再删除。新的分区目录名称遵循以下规则:
所以上面的两个分区目录200002_1_1_0和200002_2_2_0在过一段时间后最终会变成一个新的分区目录200002_1_2_1。由此可见如果你频繁插入数据会产生很多分区目录,在合并的时候会占用很多资源。所以最好一次插入很多条数据,尽量降低插入的频率。
通过上面的介绍相信大家已经对ClickHouse的索引结构有所了解,接下来用一张图简要描述Id字段的索引过程。
其它列的索引过程类似,这里就不一一赘述了,有兴趣的朋友可以自己去研究。
本文通过一个简单的例子来分析ClickHouse的存储结构,整个逻辑力求简洁明了,希望通过本文能够让喜欢ClickHouse的朋友对它的索引有个清晰的认识。
ClickHouse 极简教程-图文详解原理系列ClickHouse 主键索引的存储结构与查询性能优化...
概述
这是 Alexey Milovidov(ClickHouse 的创建者)给出的关于复合主键的答案的翻译。
原文: https://groups.google.com/g/clickhouse/c/eUrsP30VtSU/m/p4-pxgdXAgAJ
问题:
- 主键可以有多少列?存储驱动器上的数据布局是什么?有任何理论/实践限制吗?
- 某些行缺少数据的列可以成为主键的一部分吗?
This is the translation of answer given by Alexey Milovidov (creator of ClickHouse) about composite primary key.
Questions:
1.How many columns primary key could have? And what is layout of data on storage drive? Is there any theoretical/practical limits?
2.Could columns with missing data at some rows be part of primary key?
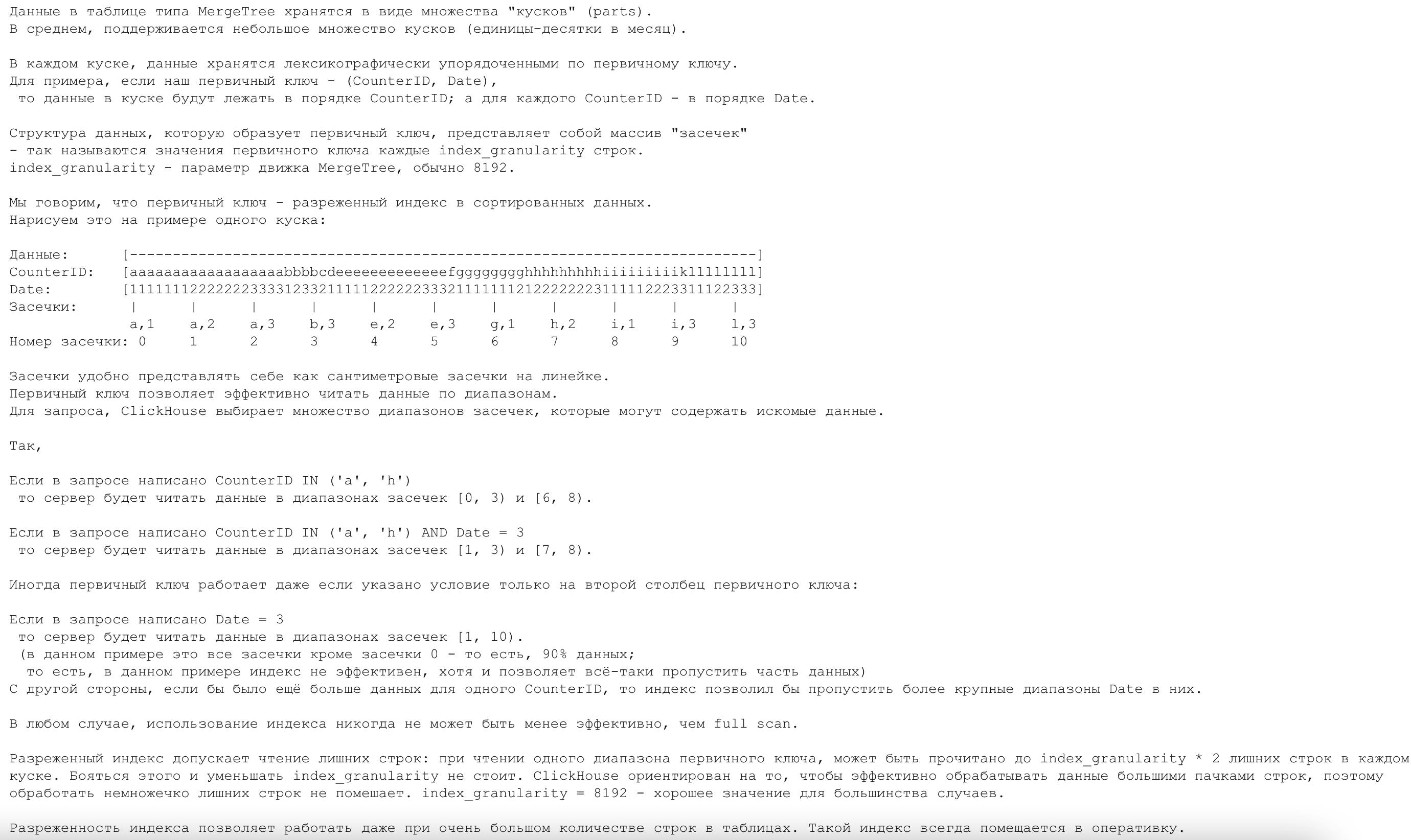
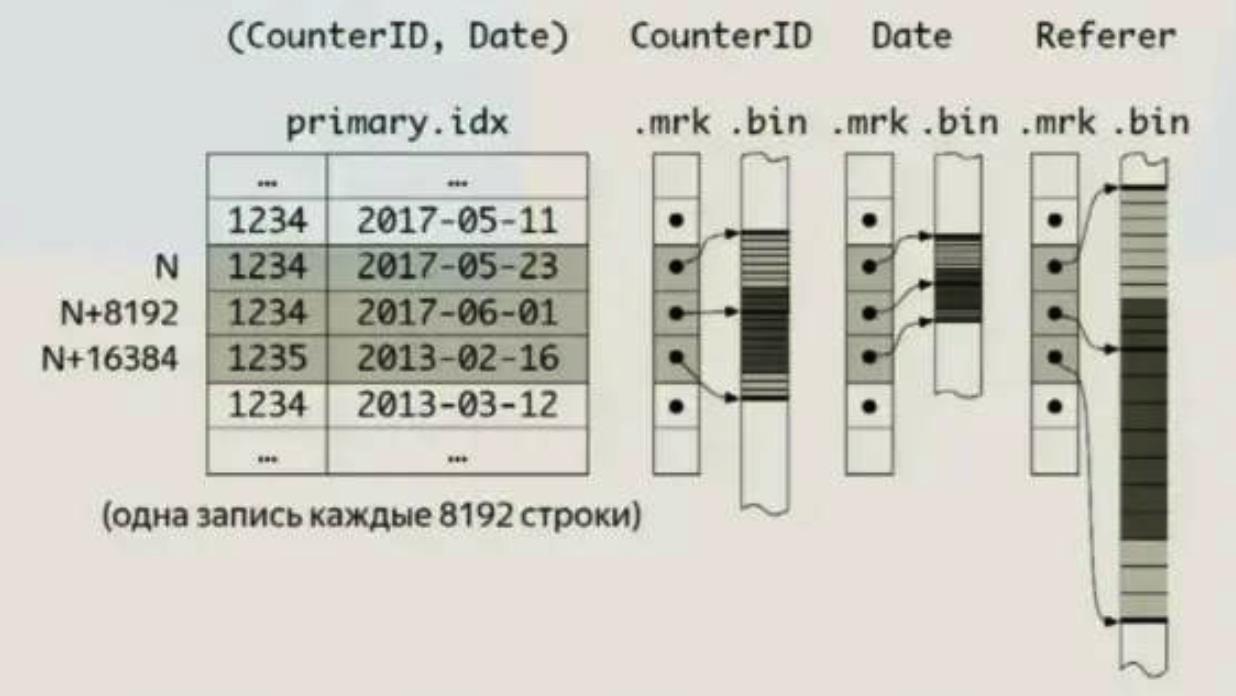
在每一个部分按主键按字典顺序存储的数据。例如,如果您的主键 - (CounterID, Date),那么行将按 CounterID 排序,而对于具有相同 CounterID 的行 - 按日期排序。
概念说明
- block:一次写入生成的一个数据块。
- primary.idx 文件:存储了稀疏索引,一个part对应一个稀疏索引。
- bin文件:真正存储数据的文件,由1到多个压缩数据组成。压缩数据是最小存储单位,由『头文件』和『压缩数据块』组成。头文件由压缩算法、压缩前的字节大小、压缩后的字节大小三部分组成;压缩数据块严格限定在压缩前 64K~1M byte 大小。(这个大小是ClickHouse认为的压缩与解压性能消耗最小的大小)。即,一个压缩数据块由N个block组成,一个bin文件又由N个压缩数据块组成。
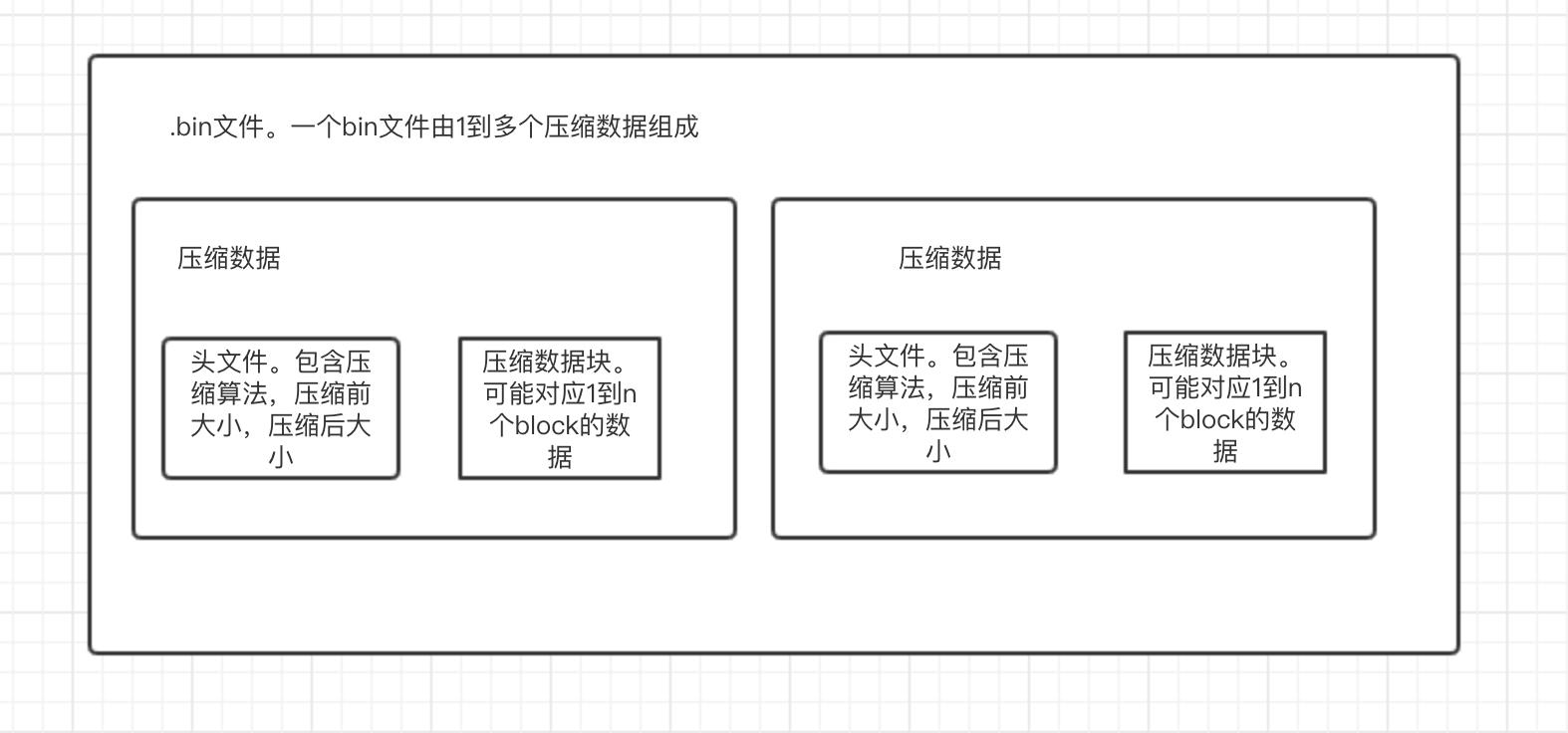
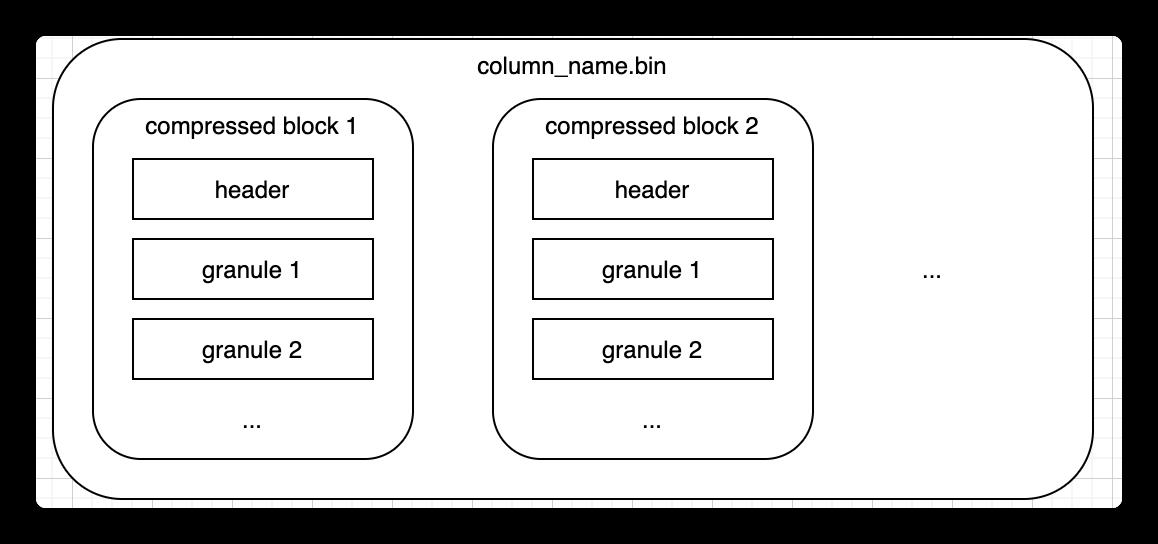
- mrk文件:存储了block在bin文件中哪个压缩数据以及这个压缩数据的数据块中的起始偏移量。
ClickHouse 主键索引【联合索引、排序键】
ClickHouse 官网的主键相关内容:
主键和索引在查询中的表现
我们以 (CounterID, Date) 以主键。排序好的索引的图示会是下面这样:

如果指定查询如下:
-
CounterID in ('a', 'h'),服务器会读取标记号在[0, 3)和[6, 8)区间中的数据。 -
CounterID IN ('a', 'h') AND Date = 3,服务器会读取标记号在[1, 3)和[7, 8)区间中的数据。 -
Date = 3,服务器会读取标记号在[1, 10]区间中的数据。
上面例子可以看出使用索引通常会比全表描述要高效。
稀疏索引会引起额外的数据读取。当读取主键单个区间范围的数据时,每个数据块中最多会多读 index_granularity * 2 行额外的数据。
稀疏索引使得您可以处理极大量的行,因为大多数情况下,这些索引常驻于内存。
ClickHouse 不要求主键唯一,所以您可以插入多条具有相同主键的行。
主键的构成,同样可以存在函数表达式。如,(CounterID,EventDate,intHash32(UserID))
上述例子中,通过使用哈希函数,把特定的用户名对应的CounterID和EVENTDATE做了聚合,顺便,这种聚合方式,可以在样本这个功能中利用到。稀疏索引适用于海量数据表,并且,稀疏索引文件本身,放到内存是没有问题的
ClickHouse 的索引优化
1.分区,原则是尽量把经常一起用到的数据放到相同区(也可以根据where条件来分区),如果一个区太大再放到多个区,
2.主键(索引,即排序)order by字段选择: 就是把where 里面肯定有的字段加到里面,where 中一定有的字段放到第一位,注意字段的区分度适中即可 区分度太大太小都不好,因为ck的索引时稀疏索引,采用的是按照固定的粒度抽样作为实际的索引值,不是mysql的二叉树,所以不建议使用区分度特别高的字段。
两种主键,第一种ORDER BY (industry, l1_name, l2_name, l3_name, job_city, job_area, row_id),第二种不包含row_id字段,即ORDER BY (industry, l1_name, l2_name, l3_name, job_city, job_area),其中row_id 是唯一的,在where条件中使用row_id来查询时,你会发现第二种会性能更好,即将row_id从主键中移除,查询效果更好。
另外,ClickHouse 的索引结构是稀疏索引 , 跟 MySQL 的二叉树数据结构完全不同。
建索引的正确方式
开始字段不应该是区分度很高的字段,如果是唯一的,那么索引效果非常差,也不能找区分度特别差的,应该找区分度中等,这就涉及到你的SETTINGS的值,如果比较大,可以找区分度稍差的列,如果比较小,找区分度稍大的列作为索引。

void MergeTreeDataPartWriterOnDisk::initPrimaryIndex()
if (metadata_snapshot->hasPrimaryKey())
index_file_stream = data_part->volume->getDisk()->writeFile(part_path + "primary.idx", DBMS_DEFAULT_BUFFER_SIZE, WriteMode::Rewrite);
index_stream = std::make_unique<HashingWriteBuffer>(*index_file_stream);
MergeTree 存储结构
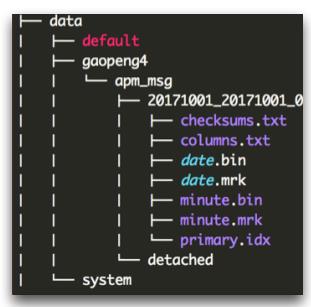
其中, Columns.txt 记录的每一列的信息。
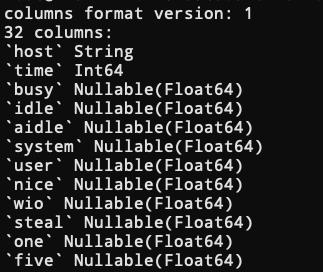
每一列都有一个bin文件和mrk文件,其中bin文件是实际的数据存储
primary.idx存储主键信息,结构与mrk一样,类似于一个稀疏索引。
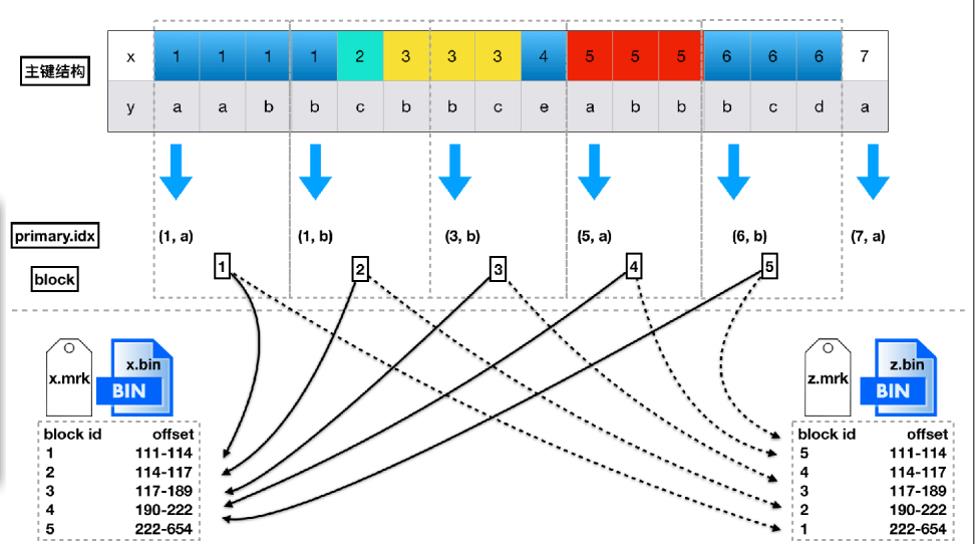
在MergeTree进行查询的时候,最关键的在于定位Block。根据主键进行查询的时候性能会比较好,但是在进行非主键的查询的时候,由于是按照列存储的关系,会进行一次全扫描。
ClickHouse primary.idx 主键的数据结构是一个标记数组 —— 它是每
index_granularity行主键的值。index_granularity— MergeTree 引擎的设置,默认为 8192。
我们说主键是排序数据的稀疏索引。
您不应该尝试减少 index_granularity。ClickHouse 旨在通过大批量的行有效地处理数据,这就是为什么在读取期间添加一些额外的列不会影响性能的原因。index_granularity = 8192 — 对于大多数情况而言,物有所值。
主键不是唯一的。您可以插入许多具有相同主键值的行。
主键还可以包含函数表达式。
示例:(CounterID, EventDate, intHash32(UserID))
上面它用于混合UserID每个 tuple的特定数据CounterID, EventDate。顺便说一句,它用于采样(https://clickhouse.yandex/reference_en.html#SAMPLE 子句)。
让我们总结一下主键的选择会影响什么:
- 最重要和最明显的:主键允许在
SELECT查询期间读取更少的数据。如上面的示例所示,为此目的在主键中包含许多列通常没有意义。
假设您有 primary key (a, b)。通过再添加一列c:(a, b, c)仅在同时符合两个条件时才有意义:
- 如果您对此列有过滤器查询;- 在您的数据中,具有相同值的数据范围
可能相当长(比 大几倍) 。换句话说,当再添加一列时,将允许跳过足够大的数据范围。index_granularity``(a, b)
2. 数据按主键排序。这样数据更可压缩。有时,通过在主键中添加一列可以更好地压缩数据。
3. 当你在合并中使用不同类型的带有附加逻辑的 MergeTree 时:CollapsingMergeTree、SummingMergeTree等,主键会影响数据的合并。出于这个原因,即使第 1 点不需要,也可能需要在主键中使用更多列。
主键的列数没有明确限制。长主键通常是无用的。在实际用例中,我看到的最大值约为 20 列(对于 SummingMergeTree),但我不推荐这种变体。
长主键会对插入性能和内存使用产生负面影响。
长主键不会对SELECT查询的性能产生负面影响。
在插入期间,所有列的缺失值将被替换为默认值并写入表。
Data in table of MergeTree type stored in set of multiple parts. On average you could expect little number of parts (units-tens per month).
In every part data stored sorted lexicographically by primary key. For example, if your primary key — (CounterID, Date), than rows would be located sorted by CounterID, and for rows with the same CounterID — sorted by Date.
Data structure of primary key looks like an array of marks — it’s values of primary key every index_granularity rows.
index_granularity — settings of MergeTree engine, default to 8192.
We say that primary key is sparse index of sorted data. Let’s visualise it with only one part. (I should have equal length between marks, but it’s a bit imperfect to draw asci-art here):


It’s convenient to represent marks as marks of ruler. Primary key allows effectively read range of data. For select ClickHouse chooses set of mark ranges that could contain target data.
This way,
if you select CounterID IN (‘a’, ‘h’)
server reads data with mark ranges [0, 3) and [6, 8).
if you select CounterID IN (‘a’, ‘h’) AND Date = 3
server reads data with mark ranges [1, 3) and [7, 8).
Sometimes primary key works even if only the second column condition presents in select:
if you select Date = 3
server reads data with mark ranges [1, 10).
In our example it’s all marks except 0 — this is 90% of data. In this case index isn’t really effective, but still allows to skip part of data.
On the other hand, if we have more data for one CounterID, index allows to skip wider ranges of Date in data.
In any case, usage of index never could be less efficient than full scan.
Sparse index could read unnecessary rows: during read of one range of primary key index_granularity * 2 unnecessary rows in every part. It’s normal and you shouldn’t try to reduce index_granularity. ClickHouse designed to work effective with data by large batches of rows, that’s why a bit of additional column during read isn’t hurt the performance. index_granularity = 8192 — good value for most cases.
Sparse index allows to work with tables that have enormous number of rows. And it always fits in RAM.
Primary key isn’t unique. You can insert many rows with the same value of primary key.
Primary key can also contain functional expressions.
Example:
(CounterID, EventDate, intHash32(UserID))Above it’s used to mix up the data of particular UserID for every tuple CounterID, EventDate. By-turn it’s used in sampling (https://clickhouse.yandex/reference_en.html#SAMPLE clause).
Let’s sum up what choice of primary key affects:
- The most important and obvious: primary key allows to read less data during
SELECTqueries. As shown in examples above it’s usually doesn’t make sense to include many columns into primary key for this purpose.
Let’s say you have primary key (a, b). By adding one more column c: (a, b, c) makes sense only if it conforms with both conditions:
- if you have queries with filter for this column;
- in your data could be quite long (several time bigger than
index_granularity) ranges of data with the same values of(a, b).
In other words when adding one more column will allow to skip big enough ranges of data.
2. Data is sorted by primary key. That way data is more compressable. Sometimes it happens that by adding one more column into primary key data could be compressed better.
3. When you use different kinds of MergeTree with additional logic in merge: CollapsingMergeTree, SummingMergeTree and etc., primary key affects merge of data. For this reason it might be necessary to use more columns in primary key even when it’s not necessary for point 1.
Number of columns into primary key isn’t limited explicitly. Long primary key is usually useless. In real use case the maximum that I saw was ~20 columns (for SummingMergeTree), but I don’t recommend this variant.
Long primary key will negatively affect insert performance and memory usage.
Long primary key will not negatively affect the performance of SELECT queries.
During insert, missing values of all columns will be replaced with default values and written to table.
索引结构
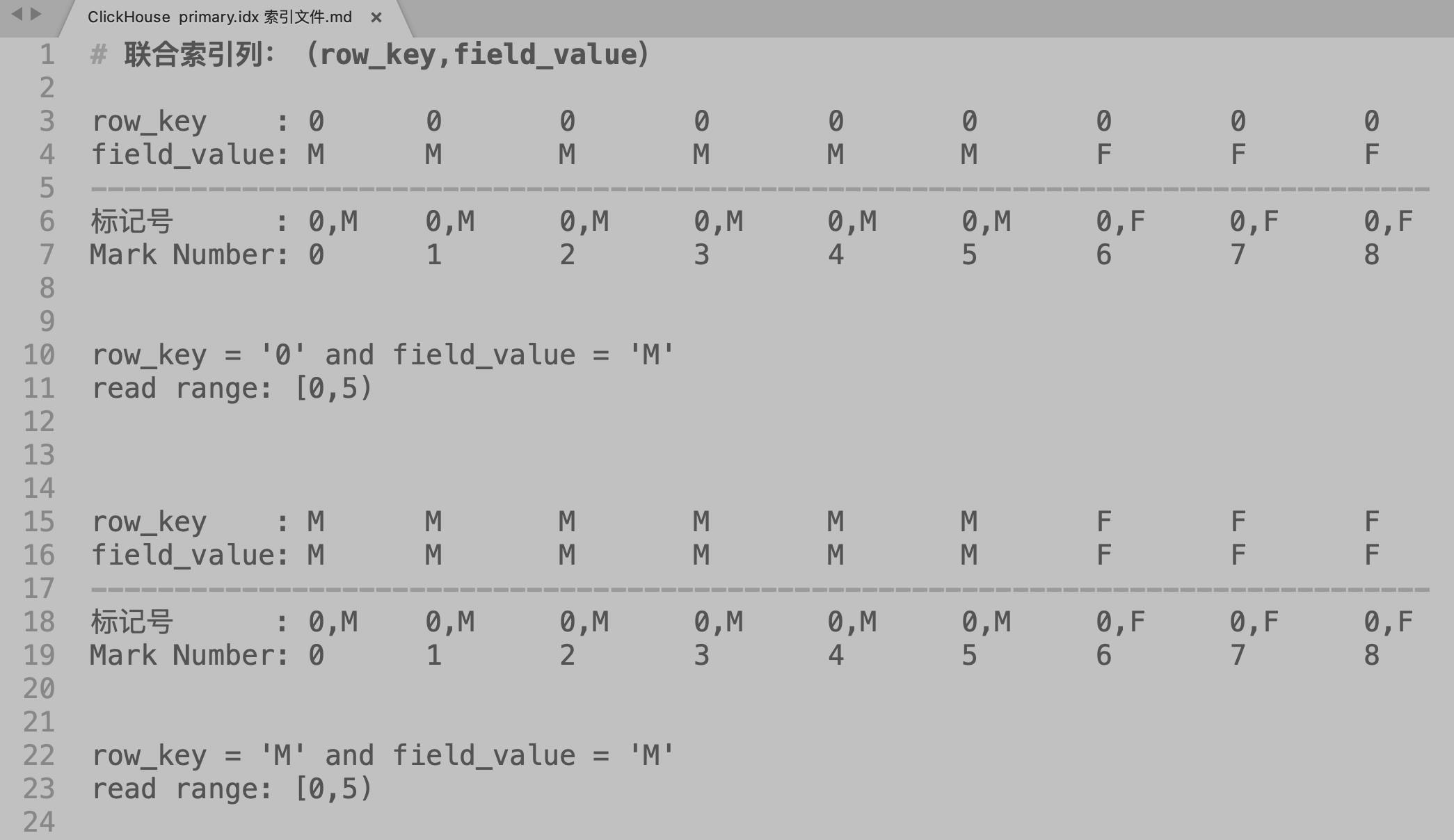
Clickhouse 索引的大致思路是:
1.选取部分列作为索引列,整个数据文件的数据按照索引列有序;
2.将排序后的数据每隔 8192 行选取出一行,记录其索引值和序号 Mark’s number;
3.对于每个列(索引列和非索引列),记录 Mark’s number 与对应行的数据的 offset。
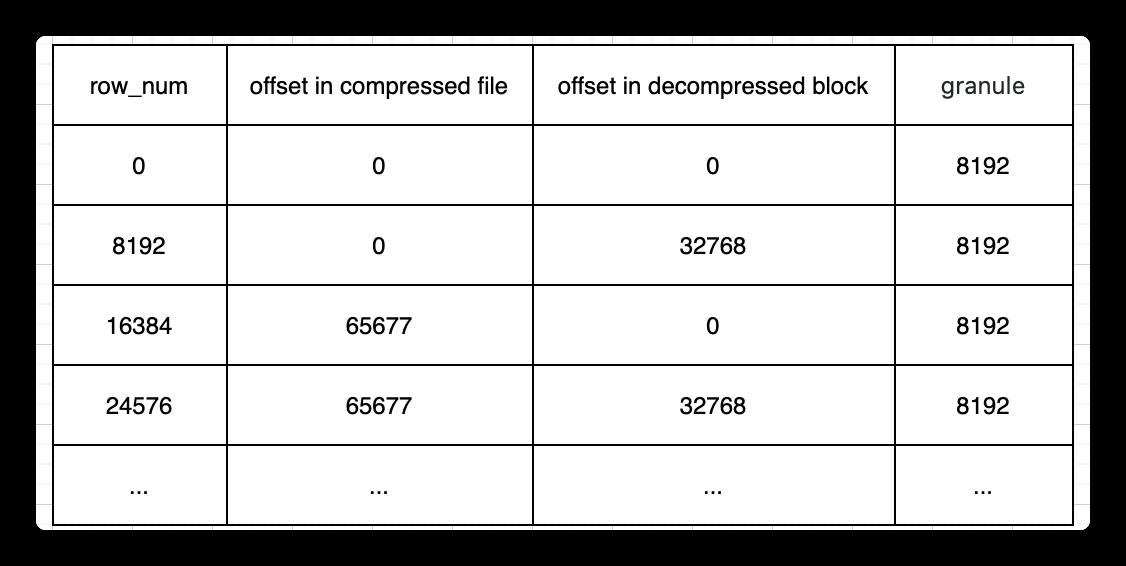
一个单独的 primary.idx 文件中存储了每个第 N 行的主键值。其中 N 称为 index_granularity(通常,N = 8192)。
同时,对于每一列,都有带有标记的 column.mrk 文件,该文件记录的是每个第 N 行在数据文件中的偏移量。每个标记是一个 pair:(文件中的偏移量到压缩块的起始位置,解压缩块中的偏移量到数据的起始位置)。
通常,压缩块根据标记对齐,并且解压缩块中的偏移量为 0。
primary.idx 的数据始终驻留在内存,同时 column.mrk 的数据被缓存。
当我们要从 MergeTree 的一个分块中读取部分内容时,我们会查看 primary.idx 数据并查找可能包含所请求数据的范围,然后查看 column.mrk 并计算偏移量从而得知从哪里开始读取些范围的数据。由于稀疏性,可能会读取额外的数据。ClickHouse 不适用于高负载的简单点查询,因为对于每一个键,整个 index_granularity 范围的行的数据都需要读取,并且对于每一列需要解压缩整个压缩块。我们使索引稀疏,是因为每一个单一的服务器需要在索引没有明显内存消耗的情况下,维护数万亿行的数据。另外,由于主键是稀疏的,导致其不是唯一的:无法在 INSERT 时检查一个键在表中是否存在。你可以在一个表中使用同一个键创建多个行。
当你向 MergeTree 中插入一堆数据时,数据按主键排序并形成一个新的分块。为了保证分块的数量相对较少,有后台线程定期选择一些分块并将它们合并成一个有序的分块,这就是 MergeTree 的名称来源。当然,合并会导致«写入放大»。所有的分块都是不可变的:它们仅会被创建和删除,不会被修改。当运行 SELECT 查询时,MergeTree 会保存一个表的快照(分块集合)。合并之后,还会保留旧的分块一段时间,以便发生故障后更容易恢复,因此如果我们发现某些合并后的分块可能已损坏,我们可以将其替换为原分块。
MergeTree 不是 LSM 树,因为它不包含»memtable«和»log«:插入的数据直接写入文件系统。这使得它仅适用于批量插入数据,而不适用于非常频繁地一行一行插入 - 大约每秒一次是没问题的,但是每秒一千次就会有问题。我们这样做是为了简单起见,因为我们已经在我们的应用中批量插入数据。
MergeTree 表只能有一个(主)索引:没有任何辅助索引。在一个逻辑表下,允许有多个物理表示,比如,可以以多个物理顺序存储数据,或者同时表示预聚合数据和原始数据。
有些 MergeTree 引擎会在后台合并期间做一些额外工作,比如 CollapsingMergeTree 和 AggregatingMergeTree。这可以视为对更新的特殊支持。请记住这些不是真正的更新,因为用户通常无法控制后台合并将会执行的时间,并且 MergeTree 中的数据几乎总是存储在多个分块中,而不是完全合并的形式。
MergeTree is a family of storage engines that supports indexing by primary key. The primary key can be an arbitrary tuple of columns or expressions. Data in a MergeTree table is stored in “parts”. Each part stores data in the primary key order, so data is ordered lexicographically by the primary key tuple. All the table columns are stored in separate column.bin files in these parts. The files consist of compressed blocks. Each block is usually from 64 KB to 1 MB of uncompressed data, depending on the average value size. The blocks consist of column values placed contiguously one after the other. Column values are in the same order for each column (the primary key defines the order), so when you iterate by many columns, you get values for the corresponding rows.
The primary key itself is “sparse”. It does not address every single row, but only some ranges of data. A separate primary.idx file has the value of the primary key for each N-th row, where N is called index_granularity (usually, N = 8192). Also, for each column, we have column.mrk files with “marks”, which are offsets to each N-th row in the data file. Each mark is a pair: the offset in the file to the beginning of the compressed block, and the offset in the decompressed block to the beginning of data. Usually, compressed blocks are aligned by marks, and the offset in the decompressed block is zero. Data for primary.idx always resides in memory, and data for column.mrk files is cached.
以一个二维表(date, city, action)为例介绍了整个索引结构,其中(date,city)是索引列。
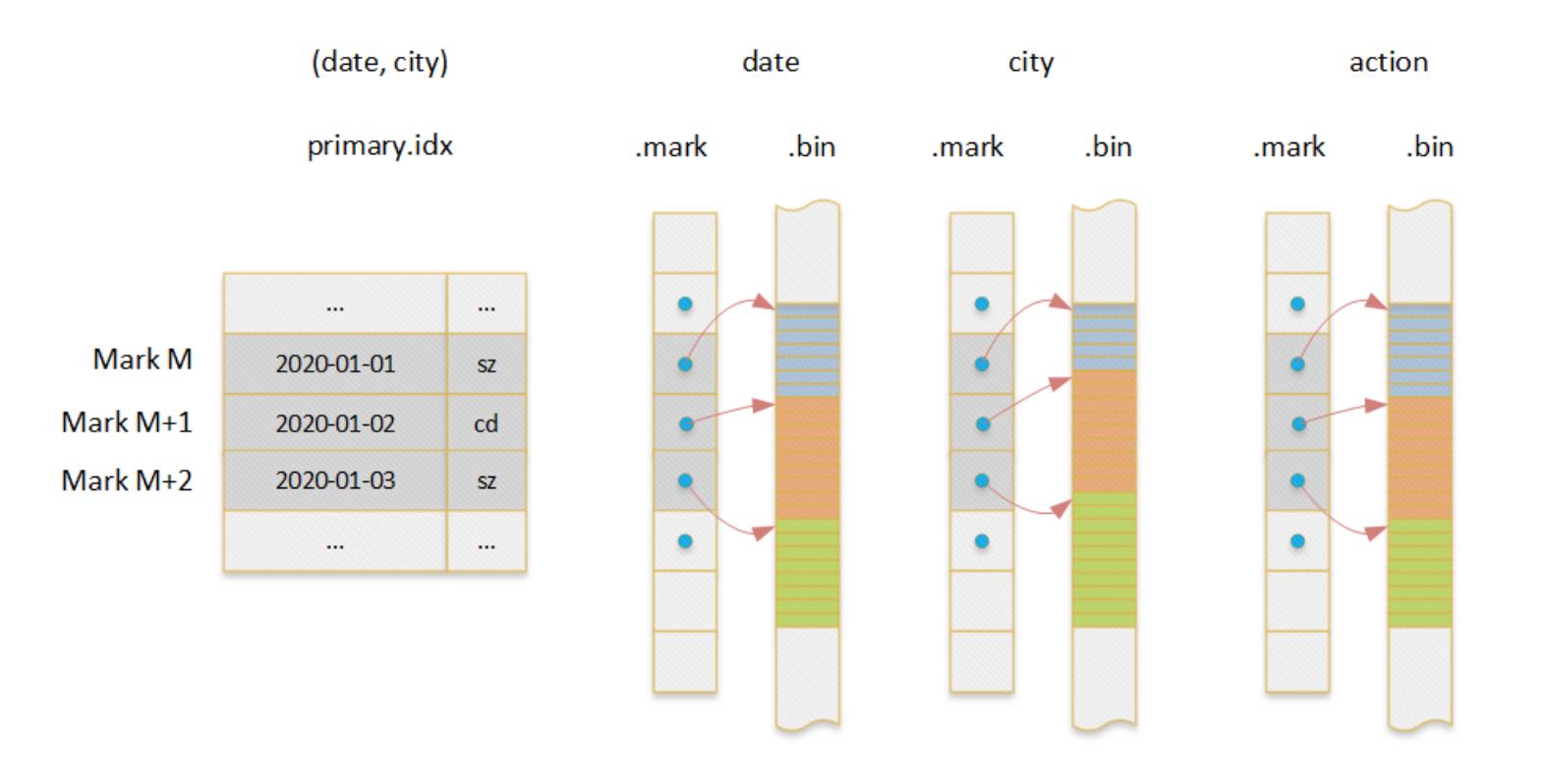
以如下查询为例看索引的使用
select count(distinct action) where date=toDate(2020-01-01) and city=’bj’二分查找 primary.idx 并找到对应的 mark’s number 集合(即数据 block 集合)
在上一步骤中的 block 中,在 date 和 city 列中查找对应的值的行号集合,并做交集,确认行号集合
将行号转换为 mark’s number 和 offset in block(注意这里的 offset 以行为单位而不是 byte)
在 action 列中,根据 mark’s number 和.mark 文件确认数据 block 在 bin 文件中的 offset,然后根据 offset in block 定位到具体的列值。
后续计算
该实例中包含了对于列的正反两个方向的查找过程。
反向:查找 date=toDate(2020-01-01) and city=’bj’数据的行号;
正向:根据行号查找 action 列的值。对于反向查找,只有在查找条件匹配最左前缀的时候,才能剪枝掉大量数据,其它时候并不高效。
ClickHouse 带索引的检索过程
以
where partition = '2019-10-23' and ID >= 10 and ID < 100这个 query 描述大体检索流程(其中,ID是索引字段 ):
每个索引都有对应的min/max的partition值,存储在内存中。
1.当contition带上partition时就可以从这些block列表中找到需要检索的索引,找到对应的数据存储文件夹,命中对应的索引(primary.idx)。
2.根据ID字段,把条件转化为[10,100)的条件区间,再把条件区间与这个partition对应的稀疏索引做交集判断。如果没有交集则不进行具体数据的检索;如果有交集,则把稀疏索引等分8份,再把条件区间与稀疏索引分片做交集判断,直到不能再拆分或者没有交集,则最后剩下的所有条件区间就是我们要检索的block值。
3.通过步骤2我们得到了我们要检索的block值。通过上面我们知道存在多个block压缩在同一个压缩数据块的情况并且一个bin文件里面又存在N个压缩数据的情况,所以不能直接通过block的值直接到bin文件中搜寻数据。我们通过映射block值到mrk中,通过mrk知道这个block对应到的压缩数据以及在压缩数据块里面的字节偏移量,就得到了我们最后需要读取的数据地址。
4.把bin文件中的数据读取到内存中,找到对应的压缩数据,直接从对应的起始偏移量开始读取数据。
ClickHouse 索引查询原理(索引过程)
通过上面的介绍相信大家已经对ClickHouse的索引结构有所了解,接下来用一张图简要描述Id字段的索引过程。
ClickHouse 在分片上执行查询语句过程如下:
- 根据查询语句中的分区范围,先进行分区级别的数据过滤。
2.在满足分区条件的目录中,通过 primary.idx 文件,结合索引键的取值范围,查询出索引编号的范围。
3.通过查询列的 [Column].mrk 文件,找到其 [Column].bin 文件中的偏移量对应关系,最终将数据加载到内存进行分析和计算。
索引文件和标记文件实际是一对多的关系(主键只有一个,但列有很多),将索引文件和标记文件剥离后,索引文件大小比较小,可以常驻内存。查询到数据范围后,可以直接计算出数据对应在标记文件中的位置,做最小化查询。
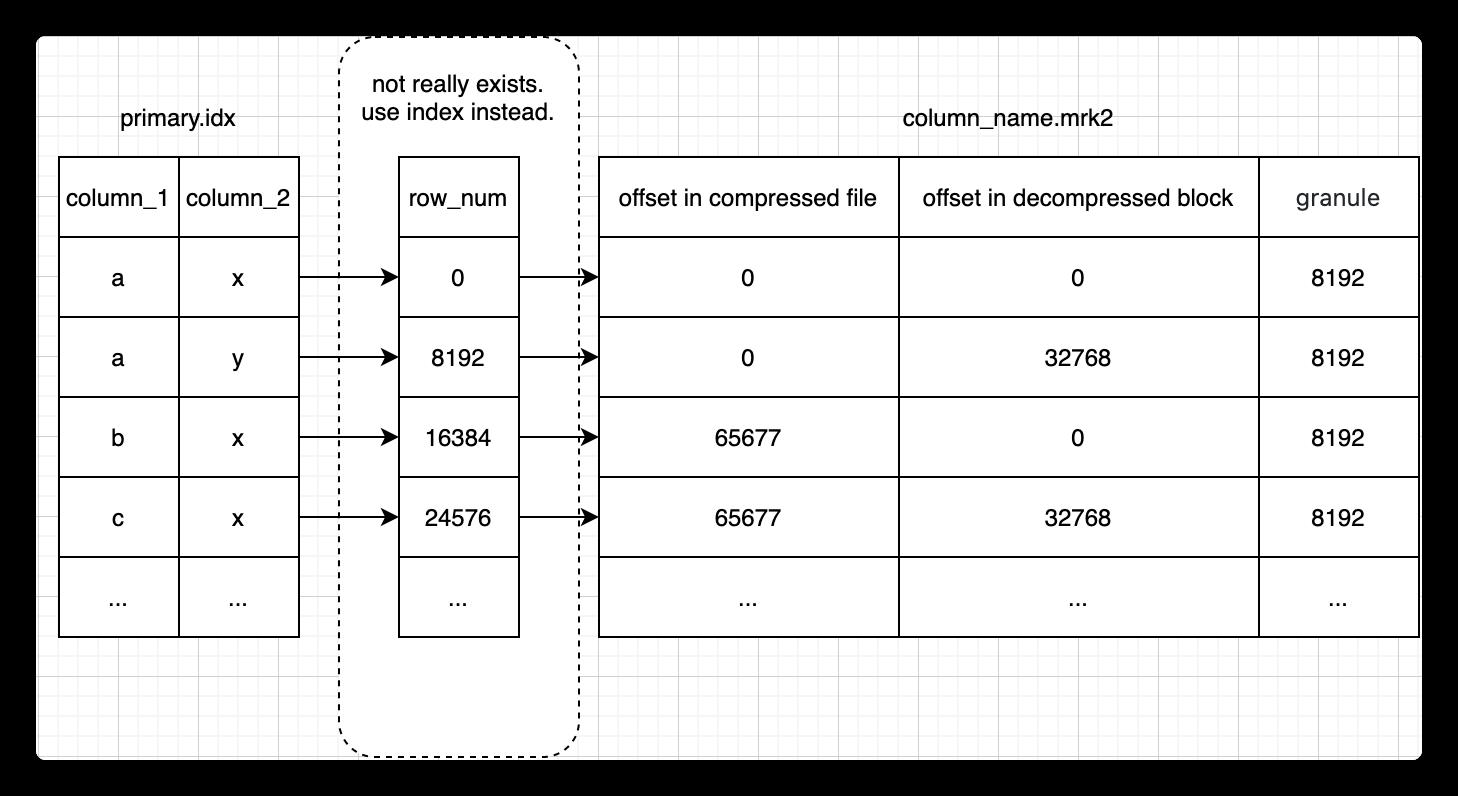
这里的行号其实只是用于关联起索引和标记两个表,而这两个表的数据在行方向其实是一一顺序对应的,因此行号其实是实际上是不需要存在文件中的,这也是Clickhouse追求极致性能,数据尽量精简的一个体现。
通过 od 查看真实的 primary.idx 索引文件内容
可以通过od查看一下真实的数据索引文件中和数据标记文件中的数据:
数据索引文件,存储的是一个个主健的值,这里主键只有一列:
root@clickhouse-0:20210110_0_123_3_341# od -l -j 0 -N 80 --width=8 primary.idx
0000000 5670735277560
0000010 24176312979802680
0000020 48658950580167724
0000030 72938406171441414
0000040 96513037981382350
0000050 120656338641242134
0000060 145024009883201898
0000070 169438340458750532
0000100 193384698694174670
0000110 217869890390743588数据标记文件,可以看作三列,分别是数据压缩块位置,数据块内偏移和granule大小
root@clickhouse-0:20210110_0_123_3_341# od -l -j 0 -N 240 --width=24 ./value9.mrk2
0000000 0 0 8192
0000030 0 32768 8192
0000060 65677 0 8192
0000110 65677 32768 8192
0000140 129357 0 8192
0000170 129357 32768 8192
0000220 193106 0 8192
0000250 193106 32768 8192
0000300 258449 0 8192
0000330 258449 32768 8192此外,在上面所举的例子中,granule都是固定为8192大小的,于是每8192行会有一行索引数据以及一行标记数据。但是从数据所占空间来看,8192行数据可能占很大空间,也可能占很小空间。如果占了很大空间,则会导致庞大的数据却只有一行索引一行标记,每次查询要做大量扫描解压的工作,拖慢整体性能,用户必须很小心地配置index_granularity。于是在新版本的Clickhouse中,会默认开启自适应granularity,新增配置项index_granularity_bytes来使得一个granule的数据大小不仅取决于行数,也取决于数据大小,因此在标记文件中会有新的一列来表示每个granule的行数。每index_granularity行
源码分析
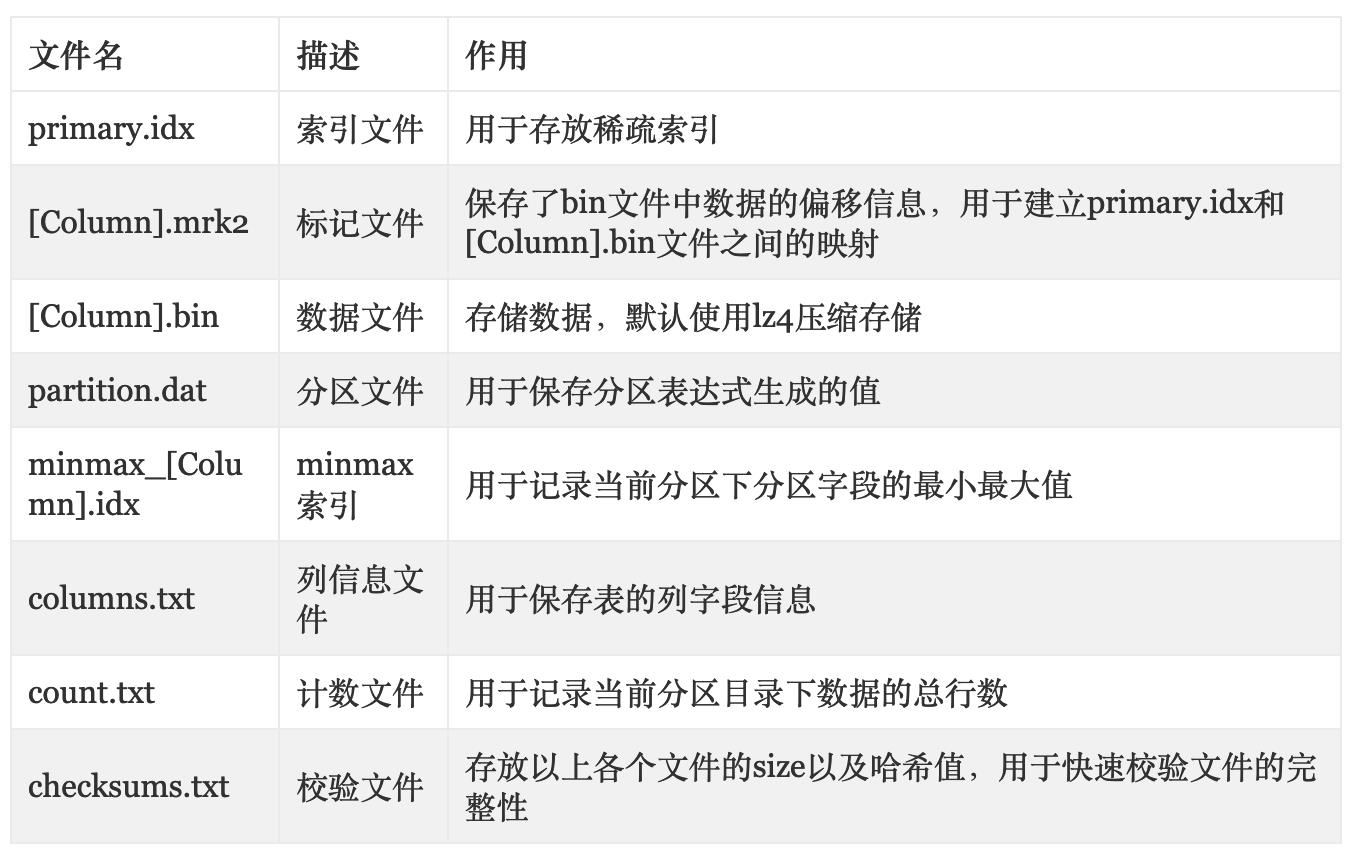
Columns
含义:表示内存中的列,使用IColumn接口,这个接口提供用于实现各种关系操作符的辅助方法,但是几乎所有的操作都是不可变的,不会改变原始列,但是可以创建一个新的修改列。
不同的IColumn实现福别不同的内存布局。内存布局退出时一个连续的数组,但是也有特殊的,比如String,Array等就是使用两个向量来组成的。
Field
Field是一个enum
enum Which
Null = 0,
UInt64 = 1,
Int64 = 2,
Float64 = 3,
UInt128 = 4,
Int128 = 5,
/// Non-POD types.
String = 16,
Array = 17,
Tuple = 18,
Decimal32 = 19,
Decimal64 = 20,
Decimal128 = 21,
AggregateFunctionState = 22,
;IDataType
负责序列化与反序列化,读写二进制或者文本形式的列或者单个值构成的块。IDataType直接与表中的数据类型相对应
IDataType与IColumn之间的关联并不大,不同类型的IDatatType可以使用相同的IColumn来表示。
IDataType仅仅存储源数据
Block
Block是表示内存中表的子集(Chunk)的子集,由IColumn,IDataType,列名三元组构成。
在查询执行期间,数据是按照Block进行处理的,
Block Streams
Block Streams用于处理数据,Block Streams从某个地方读取数据,并进行数据转换,或者将数据写入到某个地方。
IBlockInputStream具有read方法,而IBlockOutputStream具有write方法。
IO
使用ReadBuffer和WriteBuffer两个抽象类,来替代iostream。这两个类实现用于处理文件、文件描述符、socket,也可以用于进行压缩
Table
Table 由 IStorage 接口表示,这个接口实现对应不同的表引擎,实现也不一样。比如StorageMergeTree,StorageMemory.
IStorage最主要的方法就是 write 、read 、 alter 、 rename 、 drop 等方法。
Clickhouse 小结:
- MergeTree引擎众多,最常用并且默认的引擎是Merge Tree引擎,其分布式引擎在测试上面能提高更为复杂SQL的查询速度,但是其分布式表是依赖于ZK的伪分布式,需要专门维护本地表做分布式表
- MergeTree Family 作为主要引擎系列,其中包含适合明细数据的场景和适合聚合数据的场景;
- Clickhouse 的索引有点类似 MySQL 的联合索引,当查询前缀元组能命中的时候效率最高,可是一旦不能命中,几乎会扫描整个表,效率波动巨大;所以建表需要业务专家,这一点跟 kylin 类似。
参考资料
https://blog.csdn.net/h2604396739/article/details/86172756
https://www.jianshu.com/p/c69b1b73b93b
https://www.cnblogs.com/fourous/p/14725404.html
https://www.jianshu.com/p/c69b1b73b93b
https://www.jianshu.com/p/98dc2fa4ef5f
https://www.cnblogs.com/wayne2018/p/15733640.html
https://zhuanlan.zhihu.com/p/359924260
https://www.jianshu.com/p/6d547cbdc7ac
以上是关于ClickHouse存储结构及索引详解的主要内容,如果未能解决你的问题,请参考以下文章
ClickHouse 极简教程-图文详解原理系列ClickHouse 主键索引的存储结构与查询性能优化...
ClickHouse 极简教程-图文详解原理系列ClickHouse 主键索引的存储结构与查询性能优化...