ES应用场景及核心概念二
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES应用场景及核心概念二相关的知识,希望对你有一定的参考价值。
目录
ES核心操作
映射详解
描述数据结构,映射到es中存储的结构等。

创建映射,默认 science就是一个doc type 映射。字段名称 和字段类型。指定type 和 映射 数据。 给mapping添加字段 这些操作。

通过数据库来说,如果字段不存在的,添加肯定会报错,但是 es 可以动态添加的,它是将数据索引起来,供我们搜索,这就是为什么es会出现这种情况。

这个content之前创建时未创建,则会默认创建一个字段。 而采用上面的方式添加配置
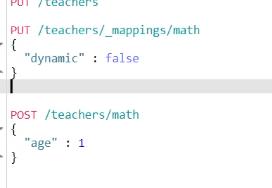
动态映射 识别出来 映射 下面 会将字符串识别成时间。

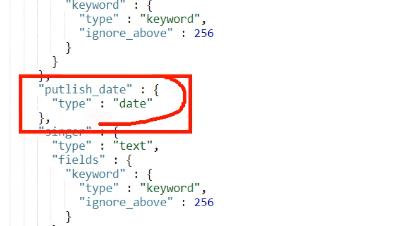
时间匹配。将长的像时间的字符串,尝试格式化成时间。
也可以不需要指定 时间匹配功能。 通过 date_detection 就可以配置

映射的元字段
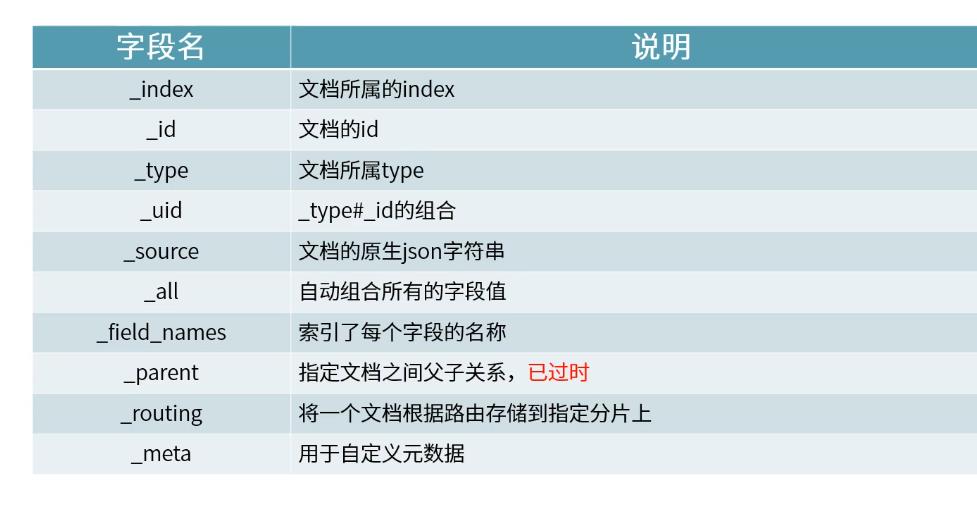 索引文档, 包括source ,存储的字段。
索引文档, 包括source ,存储的字段。
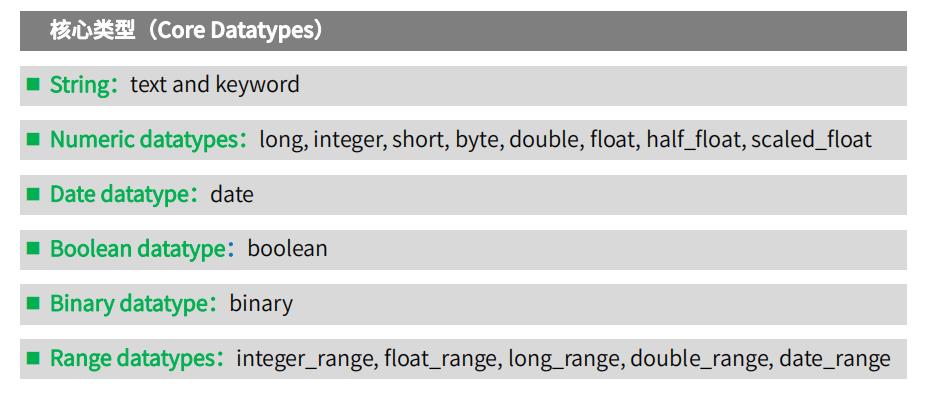
字段类型
text 和 keyword的区别, 在下面进行分词过后,进行存储,指向 id
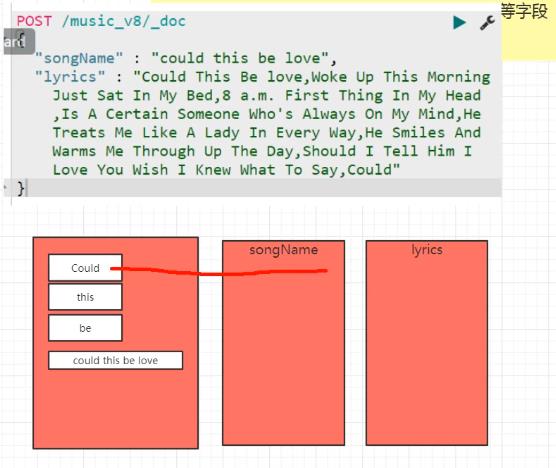


上面的复合类型,也可以设置设置权重,以及设置大小的。



包括上面的 分析, 转换 复制 动态映射等 等参数,都可以给我们设置的,包括enable ,等参数设置等等。
对于mapping中映射关系 ,可以定义属性,不断嵌套 属性的结构类型。短语查询,

index 执行反向索引
聚合和普通的搜索,在官网中可以看到的,
包括里面专门定义的查询语言

包括里面所有的特性 等都在es官方网站中可以看到。
分词器
Analyzers | Elasticsearch Guide [6.5] | Elastic
包括下面的

标准 简单分词器等
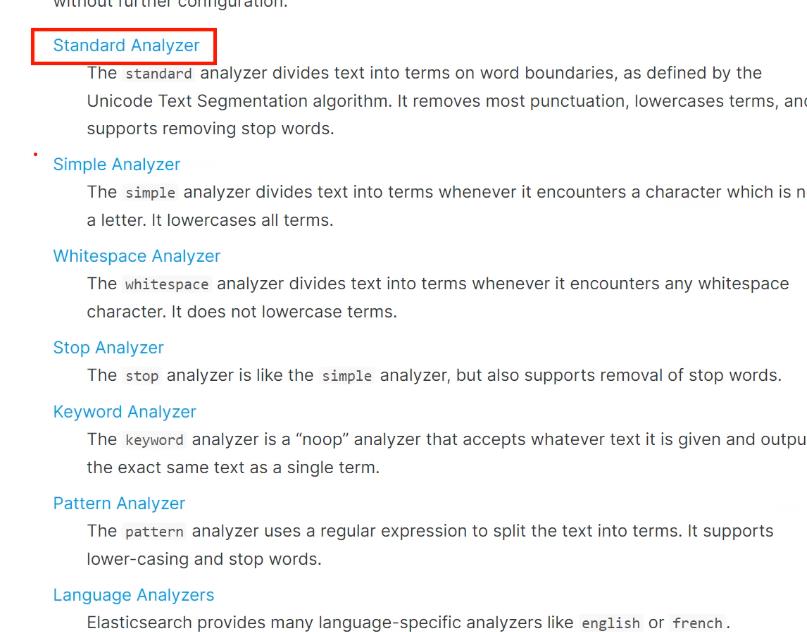 简单分词器 会数据进行分词
简单分词器 会数据进行分词

这里面有Keyword Analyzer 包括 Language Analyzers 语言分词器

- character filter :字符过滤器,对文本进行字符过滤处理,如处理文本中的html标 签字符。处理完后再交给tokenizer进行分词。一个analyzer中可包含0个或多个字符过 滤器,多个按配置顺序依次进行处理。
-
tokenizer : 分词器,对文本进行分词。一个 analyzer 必需且只可包含一个 tokenizer 。
-
token filter : 词项过滤器,对 tokenizer 分出的词进行过滤处理。如转小写、停用词处理、同义词处理。一个analyzer 可包含 0 个或多个词项过滤器,按配置顺序进行过滤。
多重字段


doc_values、fielddata、index
doc_values:大作多等数需字要段正进向行索了引反。向索引,因此可以用于搜索,但排序、聚合、scripts操作等需要正向索引。
fielddata:大多数字段可利用doc_values来进行排序、聚合、scripts等操作,但doc_values
不支持text字段,text字段利用fielddata机制来替代。
store

以上是关于ES应用场景及核心概念二的主要内容,如果未能解决你的问题,请参考以下文章