SqlServer 分区视图实现水平分表
Posted 桃花雪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SqlServer 分区视图实现水平分表相关的知识,希望对你有一定的参考价值。
我们都知道在数据库数据量较多的时候,可数据进行水平扩展,如分库,分区,分表(也叫分区)等。对于分表的一个方案,就是使用分区视图实现。
分区视图允许将大型表中的数据拆分成较小的成员表。根据其中一列中的数据值范围,在各个成员表之间对数据进行分区。每个成员表的数据范围都在为分区依据列指定的 CHECK 约束中定义。然后定义一个视图,以使用 UNION ALL 将选定的所有成员表组合成单个结果集。引用该视图的 SELECT 语句为分区依据列指定搜索条件后,查询优化器将使用 CHECK 约束定义确定哪个成员表包含相应行。
CHECK 约束 在查询方面提供更好的优化特性,看一位大侠的实验 SQL Server中使用Check约束提升性能 ,当前在其他操作方面就不太好了,以下测试。
当前测试为本地分区视图:
USE [DemoDB] GO -- 创建结构相同的表,[id] 不要设置自增(IDENTITY(1,1) ),因为插入表前就需要知道id值 -- DROP TABLE [DemoTab01],[DemoTab02],[DemoTab03] CREATE TABLE [dbo].[DemoTab01]( [id] [int] NOT NULL, [insdate] [datetime] NULL ) ON [PRIMARY] GO CREATE TABLE [dbo].[DemoTab02]( [id] [int] NOT NULL, [insdate] [datetime] NULL ) ON [PRIMARY] GO CREATE TABLE [dbo].[DemoTab03]( [id] [int] NOT NULL, [insdate] [datetime] NULL ) ON [PRIMARY] GO -- 约束每个表的范围 ALTER TABLE [dbo].[DemoTab01] WITH CHECK ADD CONSTRAINT [CK_DemoTab01_id] CHECK ([id] BETWEEN 0 AND 99999 ) GO ALTER TABLE [dbo].[DemoTab02] WITH CHECK ADD CONSTRAINT [CK_DemoTab02_id] CHECK ([id] BETWEEN 100000 AND 199999 ) GO ALTER TABLE [dbo].[DemoTab03] WITH CHECK ADD CONSTRAINT [CK_DemoTab03_id] CHECK ([id] BETWEEN 200000 AND 299999 ) GO -- 既然是按id划分,把id作为聚集索引更容易定位查找 ALTER TABLE [dbo].[DemoTab01] ADD CONSTRAINT [PK_DemoTab01_id] PRIMARY KEY CLUSTERED ([id] ASC) GO ALTER TABLE [dbo].[DemoTab02] ADD CONSTRAINT [PK_DemoTab02_id] PRIMARY KEY CLUSTERED ([id] ASC) GO ALTER TABLE [dbo].[DemoTab03] ADD CONSTRAINT [PK_DemoTab03_id] PRIMARY KEY CLUSTERED ([id] ASC) GO -- 每个字段名称列出,避免用星号,否则升级增删字段不同时会出错 -- DROP VIEW [dbo].[V_DemoTab] CREATE VIEW [dbo].[V_DemoTab] AS SELECT [id],[insdate] FROM [dbo].[DemoTab01] UNION ALL SELECT [id],[insdate] FROM [dbo].[DemoTab02] UNION ALL SELECT [id],[insdate] FROM [dbo].[DemoTab03] GO -- 121317行数据 INSERT INTO [V_DemoTab]([id],[insdate]) SELECT SalesOrderDetailID,ModifiedDate FROM AdventureWorks2012.Sales.SalesOrderDetail GO SELECT COUNT(*) FROM [dbo].[V_DemoTab] SELECT COUNT(*) FROM [dbo].[DemoTab01] SELECT COUNT(*) FROM [dbo].[DemoTab02] SELECT COUNT(*) FROM [dbo].[DemoTab03]
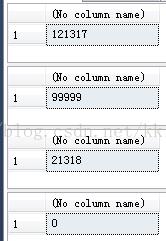
- -- 现在对视图查询
- SELECT * FROM [dbo].[V_DemoTab] WHERE id = 0 --不存在
- SELECT * FROM [dbo].[V_DemoTab] WHERE id = 3000 --只有该id有记录
- SELECT * FROM [dbo].[V_DemoTab] WHERE id = 300000 --超出check范围
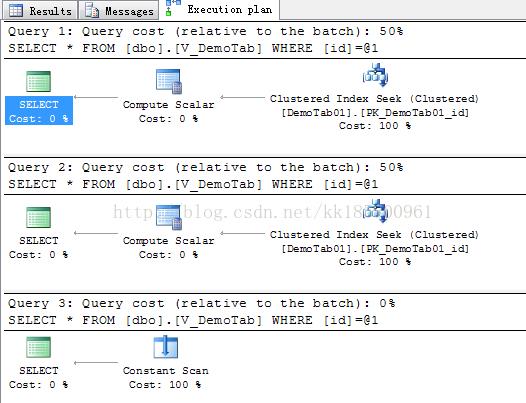
上面可以看到,只要查询在 check 约束范围内,就会进行查找。第三个查询不在范围内,并没有扫描表行数,只进行了常量扫描,这样提高了查询性能。
现在执行视图更新:
- BEGIN TRAN
- UPDATE [dbo].[V_DemoTab] SET insdate = \'2005-11-01\' WHERE id = 3000
- select CASE resource_type WHEN \'OBJECT\' THEN OBJECT_NAME(resource_associated_entity_id) ELSE \'\' END AS [object]
- ,resource_type,resource_description,request_mode,request_status,request_type
- from sys.dm_tran_locks where resource_database_id=DB_ID() and request_session_id=@@SPID
- COMMIT TRAN
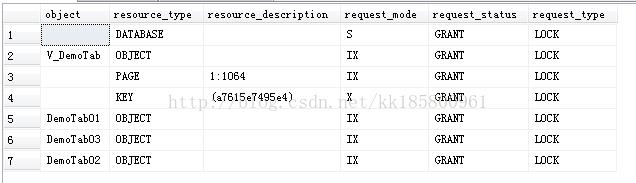
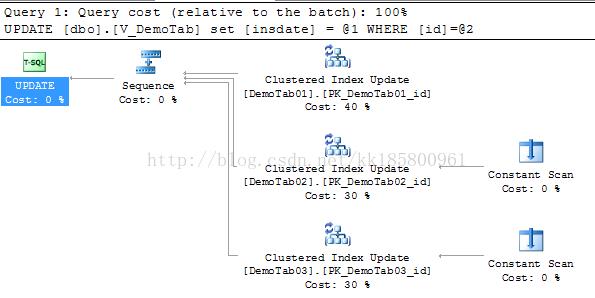
id = 3000 在表 [DemoTab01] 中,对视图的查询转化为对表的查询,但是其他表则都加上了意向排它锁(IX),这样在大量并发中势必影响到其他用户的访问。
执行计划中,不符合条件的都进行了常量扫描,实际并不读取数据,但也增加了开销。
以上是关于SqlServer 分区视图实现水平分表的主要内容,如果未能解决你的问题,请参考以下文章