mysql分库分区分表
Posted 大雾哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql分库分区分表相关的知识,希望对你有一定的参考价值。
分表:
分表分为水平分表和垂直分表。
水平分表原理:

分表策略通常是用户ID取模,如果不是整数,可以首先将其进行hash获取到整。
水平分表遇到的问题:
1. 跨表直接连接查询无法进行
2. 我们需要统计数据的时候
3. 如果数据持续增长,达到现有分表的瓶颈,需要增加分表,此时会出现数据重新排列的情况
解决方案建议:
1. 第1,2点可以通过增加汇总的冗余表,虽然数据量很大,但是可以用于后台统计或者查询时效性比较底的情况,而且我们可以提前算好某个时间点或者时间段的数据
2. 第3点解决建议:
1. 可以开始的时候,就分析大概的数据增长率,来大概确定未来某段时间内的数据总量,从而提前计算出未来某段时间内需要用到的分表的个数
2. 考虑表分区,在逻辑上面还是一个表名,实际物理存储在不同的物理地址上
3. 分库
垂直拆分原则:
1. 把大字段独立存储到一张表中
2. 把不常用的字段单独拿出来存储到一张表
3. 把经常在一起使用的字段可以拿出来单独存储到一张表
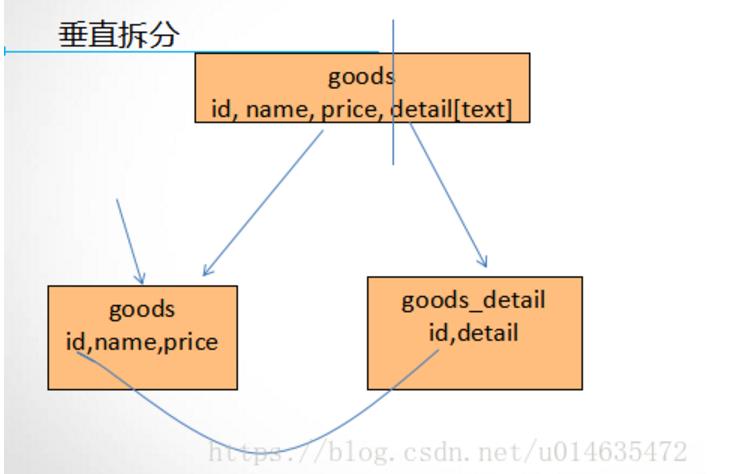
垂直拆分标准:
1.表的体积大于2G并且行数大于1千万
2.表中包含有text,blob,varchar(1000)以上
3.数据有时效性的,可以单独拿出来归档处理
/*表的体积计算*/
CREATE TABLE `test1` (
id bigint(20) not null auto_increment,
detail varchar(2000),
createtime datetime,
validity int default \'0\',
primary key (id)
);
1000万 bigint 8字节 varchar 2000 字节 datetime 8字节 validity 4字节
(8+2000+8+4) * 10000000 = 20200000000 字节 == 18G
分表后体积:
CREATE TABLE `test1` (
id int not null auto_increment,
createtime timestamp,
validity tinyint default 0,
primary key (id)
);
(4+4+1) * 10000000 = 0.08G
分库策略与分表策略的实现很相似,最简单的都是可以通过取模的方式进行路由。
分库也可以按照业务分库,比如订单表和库存表在两个库,要注意处理好跨库事务。
分表和分库 同时实现。
分库分表的策略相对于前边两种复杂一些,一种常见的路由策略如下:
1、中间变量 = user_id%(库数量*每个库的表数量);
2、库序号 = 取整(中间变量/每个库的表数量);
3、表序号 = 中间变量%每个库的表数量;
例如:数据库有256 个,每一个库中有1024个数据表,用户的user_id=262145,按照上述的路由策略,可得:
1、中间变量 = 262145%(256*1024)= 1;
2、库序号 = 取整(1/1024)= 0;
3、表序号 = 1%1024 = 1;
这样的话,对于user_id=262145,将被路由到第0个数据库的第1个表中。
表分区:
就是将一个数据量比较大的表,用某种方法把数据从物理上分成若干个小表来存储(类似水平分表),从逻辑来看还是一个大表。分表最大分1024,一般分100左右比较适合。
使用场景:
对于这种数据库比较多,但是并发不是很多的情况下,可以采用表分区。
对于数据量比较大的,但是并发也比较高的情况下,可以采用分表和分区相结合。
/*range分区*/
create table test_range(
id int not null default 0
)engine=myisam default charset=utf8
partition by range(id)(
partition p1 values less than (3),
partition p2 values less than (5),
partition p3 values less than maxvalue
);
/*hash分区*/
create table test_hash(
id int not null default 0
)engine=innodb default charset=utf8
partition by hash(id) partitions 10;
/*线性hash分区*/
create table test_linear(
id int not null default 0
)engine=innodb default charset=utf8
partition by linear hash(id) partitions 10;
/* list分区*/
create table test_list(
id int not null
) engine=innodb default charset=utf8
partition by list(id)(
partition p0 values in (3,5),
partition p1 values in (2,6,7,9)
);
/* key 分区 */
CREATE TABLE test_key (
col1 INT NOT NULL
)
PARTITION BY linear KEY (col1)
PARTITIONS 10;
普通的hash分区 增加风区后,需要重新计算
线性hash分区(了解) 增加分区后,还是在原来的分区
线性hash 相对于 hash分区 没有那么均匀
Key分区用的比较少,也是hash分区
以上是关于mysql分库分区分表的主要内容,如果未能解决你的问题,请参考以下文章