Ubuntu 16.04下Redis Cluster集群搭建(官方原始方案)
Posted Jim
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Ubuntu 16.04下Redis Cluster集群搭建(官方原始方案)相关的知识,希望对你有一定的参考价值。
前提:先安装好Redis,参考:http://www.cnblogs.com/EasonJim/p/7599941.html
说明:Redis Cluster集群模式可以做到动态增加节点和下线节点,使用起来非常的方便。
下面教程主要是通过官方提供的文档进行搭建测试:
https://redis.io/topics/cluster-tutorial
http://www.redis.cn/topics/cluster-tutorial.html
http://ifeve.com/redis-cluster-tutorial/
http://ifeve.com/redis-cluster-spec/(翻译自官方高级使用教程)
上面中文教程都可以在官方提供的文档中找到。
原理应该如下图所示:
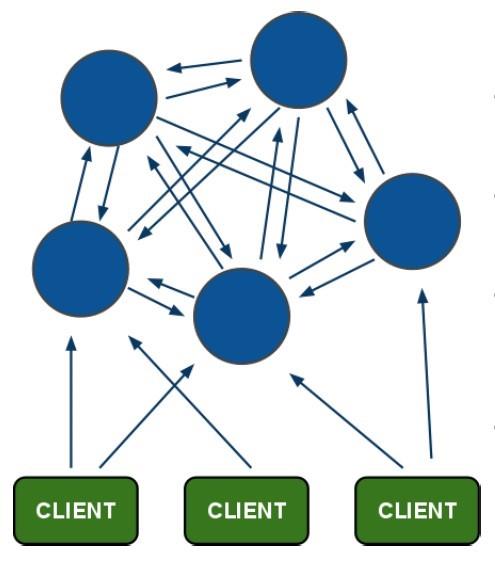
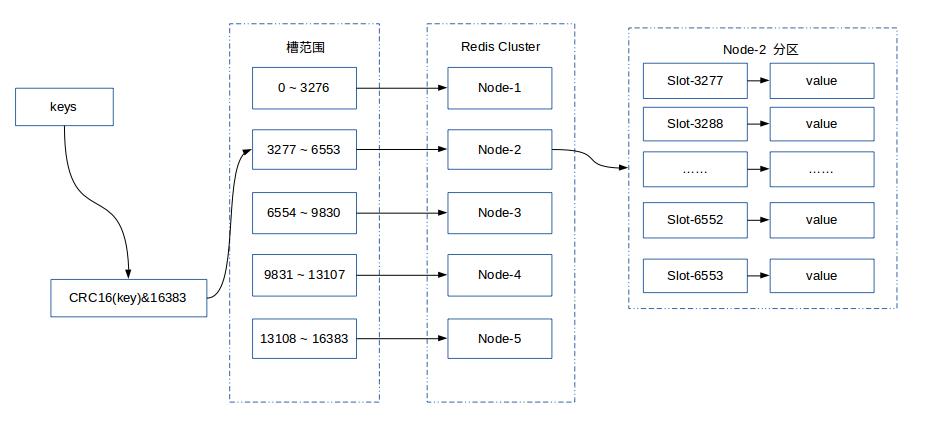
注意:以下的搭建教程比较简单,基于伪集群的模式,如果是生产环境可以每台机部署一个实例。操作基本一致。
这篇教程是Redis集群的简要介绍,而非讲解分布式系统的复杂概念。它主要从一个使用者的角度介绍如何搭建、测试和使用Redis集群,至于Redis集群的详细设计将在“Redis集群规范”中进行描述。
本教程以redis使用者的角度,用简单易懂的方式介绍Redis集群的可用性和一致性。
注意: 本教程要求Redis3.0或以上的版本。
如果你打算部署Redis集群,你可以读一些关于集群的详细设计,当然,这不是必须的。由这篇教程入门,先大概使用一下Redis的集群,然后再读Redis集群的详细设计,也是不错的选择。
Redis集群 101
Redis集群在启动的时候就自动在多个节点间分好片。同时提供了分片之间的可用性:当一部分redis节点故障或网络中断,集群也能继续工作。但是,当大面积的节点故障或网络中断(比如大部分的主节点都不可用了),集群就不能使用。
所以,从实用性的角度,Redis集群提供以下功能:
- 自动把数据切分到多个Redis节点中
- 当一部分节点挂了或不可达,集群依然能继续工作
Redis集群的TCP端口
Redis集群中的每个节点都需要建立2个TCP连接,监听这2个端口:一个端口称之为“客户端端口”,用于接受客户端指令,与客户端交互,比如6379;另一个端口称之为“集群总线端口”,是在客户端端口号上加10000,比如16379,用于节点之间通过二进制协议通讯。各节点通过集群总线检测宕机节点、更新配置、故障转移验证等。客户端只能使用客户端端口,不能使用集群总线端口。请确保你的防火墙允许打开这两个端口,否则Redis集群没法工作。客户端端口和集群总线端口之间的差值是固定的,集群总线端口比客户端端口高10000。
注意,关于集群的2个端口:
- 客户端端口(一般是6379)需要对所有客户端和集群节点开放,因为集群节点需要通过该端口转移数据。
- 集群总线端口(一般是16379)只需对集群中的所有节点开放
这2个端口必须打开,否则集群没法正常工作。
集群节点之间通过集群总线端口交互数据,使用的协议不同于客户端的协议,是二进制协议,这可以减少带宽和处理时间。
Redis集群数据的分片
Redis集群不是使用一致性哈希,而是使用哈希槽。整个Redis集群有16384个哈希槽,决定一个key应该分配到那个槽的算法是:计算该key的CRC16结果再模16834。
集群中的每个节点负责一部分哈希槽,比如集群中有3个节点,则:
- 节点A存储的哈希槽范围是:0 – 5500
- 节点B存储的哈希槽范围是:5501 – 11000
- 节点C存储的哈希槽范围是:11001 – 16384
这样的分布方式方便节点的添加和删除。比如,需要新增一个节点D,只需要把A、B、C中的部分哈希槽数据移到D节点。同样,如果希望在集群中删除A节点,只需要把A节点的哈希槽的数据移到B和C节点,当A节点的数据全部被移走后,A节点就可以完全从集群中删除。
因为把哈希槽从一个节点移到另一个节点是不需要停机的,所以,增加或删除节点,或更改节点上的哈希槽,也是不需要停机的。
如果多个key都属于一个哈希槽,集群支持通过一个命令(或事务, 或lua脚本)同时操作这些key。通过“哈希标签”的概念,用户可以让多个key分配到同一个哈希槽。哈希标签在集群详细文档中有描述,这里做个简单介绍:如果key含有大括号”{}”,则只有大括号中的字符串会参与哈希,比如”this{foo}”和”another{foo}”这2个key会分配到同一个哈希槽,所以可以在一个命令中同时操作他们。
Redis集群的主从模式
为了保证在部分节点故障或网络不通时集群依然能正常工作,集群使用了主从模型,每个哈希槽有一(主节点)到N个副本(N-1个从节点)。在我们刚才的集群例子中,有A,B,C三个节点,如果B节点故障集群就不能正常工作了,因为B节点中的哈希槽数据没法操作。但是,如果我们给每一个节点都增加一个从节点,就变成了:A,B,C三个节点是主节点,A1, B1, C1 分别是他们的从节点,当B节点宕机时,我们的集群也能正常运作。B1节点是B节点的副本,如果B节点故障,集群会提升B1为主节点,从而让集群继续正常工作。但是,如果B和B1同时故障,集群就不能继续工作了。
Redis集群的一致性保证
Redis集群不能保证强一致性。一些已经向客户端确认写成功的操作,会在某些不确定的情况下丢失。
产生写操作丢失的第一个原因,是因为主从节点之间使用了异步的方式来同步数据。
一个写操作是这样一个流程:
1)客户端向主节点B发起写的操作
2)主节点B回应客户端写操作成功
3)主节点B向它的从节点B1,B2,B3同步该写操作
从上面的流程可以看出来,主节点B并没有等从节点B1,B2,B3写完之后再回复客户端这次操作的结果。所以,如果主节点B在通知客户端写操作成功之后,但同步给从节点之前,主节点B故障了,其中一个没有收到该写操作的从节点会晋升成主节点,该写操作就这样永远丢失了。
就像传统的数据库,在不涉及到分布式的情况下,它每秒写回磁盘。为了提高一致性,可以在写盘完成之后再回复客户端,但这样就要损失性能。这种方式就等于Redis集群使用同步复制的方式。
基本上,在性能和一致性之间,需要一个权衡。
如果真的需要,Redis集群支持同步复制的方式,通过WAIT指令来实现,这可以让丢失写操作的可能性降到很低。但就算使用了同步复制的方式,Redis集群依然不是强一致性的,在某些复杂的情况下,比如从节点在与主节点失去连接之后被选为主节点,不一致性还是会发生。
这种不一致性发生的情况是这样的,当客户端与少数的节点(至少含有一个主节点)网络联通,但他们与其他大多数节点网络不通。比如6个节点,A,B,C是主节点,A1,B1,C1分别是他们的从节点,一个客户端称之为Z1。
当网络出问题时,他们被分成2组网络,组内网络联通,但2组之间的网络不通,假设A,C,A1,B1,C1彼此之间是联通的,另一边,B和Z1的网络是联通的。Z1可以继续往B发起写操作,B也接受Z1的写操作。当网络恢复时,如果这个时间间隔足够短,集群仍然能继续正常工作。如果时间比较长,以致B1在大多数的这边被选为主节点,那刚才Z1发给B的写操作都将丢失。
注意,Z1给B发送写操作是有一个限制的,如果时间长度达到了大多数节点那边可以选出一个新的主节点时,少数这边的所有主节点都不接受写操作。
这个时间的配置,称之为节点超时(node timeout),对集群来说非常重要,当达到了这个节点超时的时间之后,主节点被认为已经宕机,可以用它的一个从节点来代替。同样,在节点超时时,如果主节点依然不能联系到其他主节点,它将进入错误状态,不再接受写操作。
Redis集群参数配置
我们后面会部署一个Redis集群作为例子,在那之前,先介绍一下集群在redis.conf中的参数。
- cluster-enabled
<yes/no>: 如果配置”yes”则开启集群功能,此redis实例作为集群的一个节点,否则,它是一个普通的单一的redis实例。- cluster-config-file
<filename>: 注意:虽然此配置的名字叫“集群配置文件”,但是此配置文件不能人工编辑,它是集群节点自动维护的文件,主要用于记录集群中有哪些节点、他们的状态以及一些持久化参数等,方便在重启时恢复这些状态。通常是在收到请求之后这个文件就会被更新。- cluster-node-timeout
<milliseconds>: 这是集群中的节点能够失联的最大时间,超过这个时间,该节点就会被认为故障。如果主节点超过这个时间还是不可达,则用它的从节点将启动故障迁移,升级成主节点。注意,任何一个节点在这个时间之内如果还是没有连上大部分的主节点,则此节点将停止接收任何请求。- cluster-slave-validity-factor
<factor>: 如果设置成0,则无论从节点与主节点失联多久,从节点都会尝试升级成主节点。如果设置成正数,则cluster-node-timeout乘以cluster-slave-validity-factor得到的时间,是从节点与主节点失联后,此从节点数据有效的最长时间,超过这个时间,从节点不会启动故障迁移。假设cluster-node-timeout=5,cluster-slave-validity-factor=10,则如果从节点跟主节点失联超过50秒,此从节点不能成为主节点。注意,如果此参数配置为非0,将可能出现由于某主节点失联却没有从节点能顶上的情况,从而导致集群不能正常工作,在这种情况下,只有等到原来的主节点重新回归到集群,集群才恢复运作。- cluster-migration-barrier
<count>:主节点需要的最小从节点数,只有达到这个数,主节点失败时,它从节点才会进行迁移。更详细介绍可以看本教程后面关于副本迁移到部分。- cluster-require-full-coverage <yes/no>:在部分key所在的节点不可用时,如果此参数设置为”yes”(默认值), 则整个集群停止接受操作;如果此参数设置为”no”,则集群依然为可达节点上的key提供读操作。
创建和使用Redis集群
注意:手动部署Redis集群能够很好的了解它是如何运作的,但如果你希望尽快的让集群运行起来,可以跳过本节和下一节,直接到”使用create-cluster脚本创建Redis集群”章节。
要创建集群,首先需要以集群模式运行的空redis实例。也就说,以普通模式启动的redis是不能作为集群的节点的,需要以集群模式启动的redis实例才能有集群节点的特性、支持集群的指令,成为集群的节点。
下面是最小的redis集群的配置文件(redis.conf):
port 7000 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes开启集群模式只需打开cluster-enabled配置项即可。每一个redis实例都包含一个配置文件,默认是nodes.conf(启动时会自动生成),用于存储此节点的一些配置信息。这个配置文件由redis集群的节点自行创建和更新,不能由人手动地去修改。
一个最小的集群需要最少3个主节点。第一次测试,强烈建议你配置6个节点:3个主节点和3个从节点。
开始测试,步骤如下:先进入新的目录,以redis实例的端口为目录名,创建目录,我们将在这些目录里运行我们的实例。
类似这样:
mkdir cluster-test cd cluster-test mkdir 7000 7001 7002 7003 7004 7005在7000-7005的每个目录中创建配置文件redis.conf,内容就用上面的最简配置做模板,注意修改端口号,改为跟目录一致的端口。
把你的Redis服务器(用GitHub中的不稳定分支的最新的代码编译来/或者稳定代码)拷贝到cluster-test目录,然后打开6个终端页准备测试。
第一台:
在每个终端启动一个redis实例,指令类似这样:
cd 7000 ../redis-server ./redis.conf在日志中我们可以看到,由于没有nodes.conf文件不存在,每个节点都给自己一个新的ID。
[82462] 26 Nov 11:56:55.329 * No cluster configuration found, I\'m 97a3a64667477371c4479320d683e4c8db5858b1这个ID将一直被此节点使用,作为此节点在整个集群中的唯一标识。节点区分其他节点也是通过此ID来标识,而非IP或端口。IP可以改,端口可以改,但此ID不能改,直到这个节点离开集群。这个ID称之为节点ID(Node ID)。
第二台:
第三台:
第四台:
第五台:
第六台:
重复第一台的操作。
创建集群
现在6个实例已经运行起来了,我们需要给节点写一些有意义的配置来创建集群。redis集群的命令工具redis-trib可以让我们创建集群变得非常简单。redis-trib是一个用ruby写的脚本,用于给各节点发指令创建集群、检查集群状态或给集群重新分片等。redis-trib在Redis源码的src目录下,需要gem redis来运行redis-trib。
gem install redis创建集群只需输入指令:
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005这里用的命令是create,因为我们需要创建一个新的集群。选项”–replicas 1”表示每个主节点需要一个从节点。其他参数就是需要加入这个集群的Redis实例的地址。
我们创建的集群有3个主节点和3个从节点。
redis-trib会给你一些配置建议,输入yes表示接受。集群会被配置并彼此连接好,意思是各节点实例被引导彼此通话并最终形成集群。最后,如果一切顺利,会看到类似下面的信息:
[OK] All 16384 slots covered这表示,16384个哈希槽都被主节点正常服务着。
使用create-cluster脚本创建redis集群
如果你不想像上面那样,单独的手工配置各节点的方式来创建集群,还有一个更简单的系统(当然也没法了解到集群运作的一些细节)。
在utils/create-cluster目录下,有一个名为create-cluster的bash脚本。如果需要启动一个有3个主节点和3个从节点的集群,只需要输入以下指令
#1
create-cluster start #2
create-cluster create在步骤2,当redis-trib要你接受集群的布局时,输入”yes”。
现在你可以跟集群交互,第一个节点的起始端口默认是30001。当你完成后,停止集群用如下指令:
create-cluster stop请查看目录下的README,它有详细的介绍如何使用此脚本。
实际操作如下:
版本:4.0.2
下载地址:https://redis.io/download
离线版本:(链接: https://pan.baidu.com/s/1bpwDtOr 密码: 4cxk)
源码编译:
wget http://download.redis.io/releases/redis-4.0.2.tar.gz tar xzf redis-4.0.2.tar.gz cd redis-4.0.2 make
如果不安装到指定位置,那么程序默认放在src文件夹下,
创建集群文件及文件夹:
mkdir cluster-test cd cluster-test mkdir 7000 7001 7002 7003 7004 7005
进入7000创建redis.conf,内容如下:
cd 7000 sudo vim redis.conf #内容 port 7000 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes
进入7001创建redis.conf,内容如下:
cd 7001
sudo vim redis.conf
#内容
port 7001
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
进入7002创建redis.conf,内容如下:
cd 7002
sudo vim redis.conf
#内容
port 7002
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
进入7003创建redis.conf,内容如下:
cd 7003
sudo vim redis.conf
#内容
port 7003
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
进入7004创建redis.conf,内容如下:
cd 7004
sudo vim redis.conf
#内容
port 7004
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
进入7005创建redis.conf,内容如下:
cd 7005
sudo vim redis.conf
#内容
port 7005
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
分别启动6台集群:
cd 7000
../redis-server ./redis.conf
cd 7001 ../redis-server ./redis.conf
cd 7002 ../redis-server ./redis.conf
cd 7003 ../redis-server ./redis.conf
cd 7004 ../redis-server ./redis.conf
cd 7005 ../redis-server ./redis.conf
创建集群:
先安装ruby
sudo apt-get ruby
进入src文件夹
再通过gem安装redis
cd src gem install redis
如果出现错误,参考:http://www.cnblogs.com/EasonJim/p/7629314.html
启动
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
期间会提示输入yes,然后基本完成。输出的信息上有提示哪些是主节点和从节点。
参考:
http://ifeve.com/redis-cluster-tutorial/(以上内容部分转自此篇文章)
http://blog.csdn.net/fengshizty/article/details/51368004 (节点操作的测试)
http://www.redis.cn/topics/cluster-tutorial.html
http://ifeve.com/redis-cluster-spec/
http://os.51cto.com/art/201512/499551.htm
http://blog.csdn.net/robertohuang/article/details/70766809
http://blog.csdn.net/robertohuang/article/details/70768922
http://blog.csdn.net/robertohuang/article/details/70833231
http://blog.chinaunix.net/uid-28396214-id-4981572.html
http://blog.51yip.com/nosql/1725.html
http://www.cnblogs.com/wuxl360/p/5920330.html
http://blog.csdn.net/men_wen/article/details/72853078
以上是关于Ubuntu 16.04下Redis Cluster集群搭建(官方原始方案)的主要内容,如果未能解决你的问题,请参考以下文章
Ubuntu16.04下安装redis并实现helloworld
Ubuntu 16.04下Redis Cluster集群搭建(官方原始方案)
Ubuntu16.04下nginx+mysql+php+redis
Ubuntu16.04下安装redis缓存服务器并输出helloworld