分类算法 - 朴素贝叶斯算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分类算法 - 朴素贝叶斯算法相关的知识,希望对你有一定的参考价值。
参考技术A相信很多同学在高中或者大学的时候都学过贝叶斯原理,即条件原理。
现分别有 A、B 两个容器,在容器 A 里分别有 7 个红球和 3 个白球,在容器 B 里有 1 个红球和 9 个白球,现已知从这两个容器里任意抽出了一个红球,问这个球来自容器 A 的概率是多少?
假设已经抽出红球为事件 B,选中容器 A 为事件 A,则有:P(B) = 8/20,P(A) = 1/2,P(B|A) = 7/10,按照公式,则有:P(A|B) = (7/10)*(1/2) / (8/20) = 0.875
之所以称为朴素贝叶斯, 是因为它假设每个输入变量是独立的。 现实生活中这种情况基本不满足,但是这项技术对于绝大部分的复杂问题仍然非常有效。
朴素贝叶斯模型由两种类型的概率组成:
1、每个类别的概率P(Cj);
2、每个属性的条件概率P(Ai|Cj)。
为了训练朴素贝叶斯模型,我们需要先给出训练数据,以及这些数据对应的分类。那么上面这两个概率,也就是类别概率和条件概率。他们都可以从给出的训练数据中计算出来。一旦计算出来,概率模型就可以使用贝叶斯原理对新数据进行预测。
贝叶斯原理、贝叶斯分类和朴素贝叶斯这三者之间是有区别的
贝叶斯原理是最大的概念,它解决了概率论中“逆向概率”的问题,在这个理论基础上,人们设计出了贝叶斯分类器,朴素贝叶斯分类是贝叶斯分类器中的一种,也是最简单,最常用的分类器。朴素贝叶斯之所以朴素是因为它假设属性是相互独立的,因此对实际情况有所约束, 如果属性之间存在关联,分类准确率会降低。
(1) 算法逻辑简单,易于实现
(2)分类过程中时空开销小(假设特征相互独立,只会涉及到二维存储)
(1)理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
(2)在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
库有3种算法:GaussianNB、MultinomialNB和BernoulliNB。
这三个类适用的分类场景各不相同,主要根据数据类型来进行模型的选择。一般来说,如果样本特征的分布大部分是连续值,使用GaussianNB会比较好。如果如果样本特征的分大部分是多元离散值,使用MultinomialNB比较合适。而如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB。
算法 - 朴素贝叶斯分类算法
带你搞懂朴素贝叶斯分类算法
带你搞懂朴素贝叶斯分类算
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。这篇文章我尽可能用直白的话语总结一下我们学习会上讲到的朴素贝叶斯分类算法,希望有利于他人理解。
1 分类问题综述
对于分类问题,其实谁都不会陌生,日常生活中我们每天都进行着分类过程。例如,当你看到一个人,你的脑子下意识判断他是学生还是社会上的人;你可能经常会走在路上对身旁的朋友说“这个人一看就很有钱”之类的话,其实这就是一种分类操作。
既然是贝叶斯分类算法,那么分类的数学描述又是什么呢?
从数学角度来说,分类问题可做如下定义:已知集合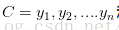
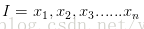
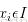
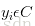
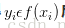
其中C叫做类别集合,其中每一个元素是一个类别,而I叫做项集合(特征集合),其中每一个元素是一个待分类项,f叫做分类器。分类算法的任务就是构造分类器f。
分类算法的内容是要求给定特征,让我们得出类别,这也是所有分类问题的关键。那么如何由指定特征,得到我们最终的类别,也是我们下面要讲的,每一个不同的分类算法,对应着不同的核心思想。
本篇文章,我会用一个具体实例,对朴素贝叶斯算法几乎所有的重要知识点进行讲解。
2 朴素贝叶斯分类
那么既然是朴素贝叶斯分类算法,它的核心算法又是什么呢?
是下面这个贝叶斯公式:
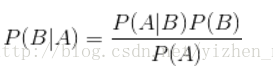
换个表达形式就会明朗很多,如下:
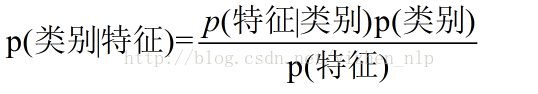
我们最终求的p(类别|特征)即可!就相当于完成了我们的任务。
3 例题分析
下面我先给出例子问题。
给定数据如下:
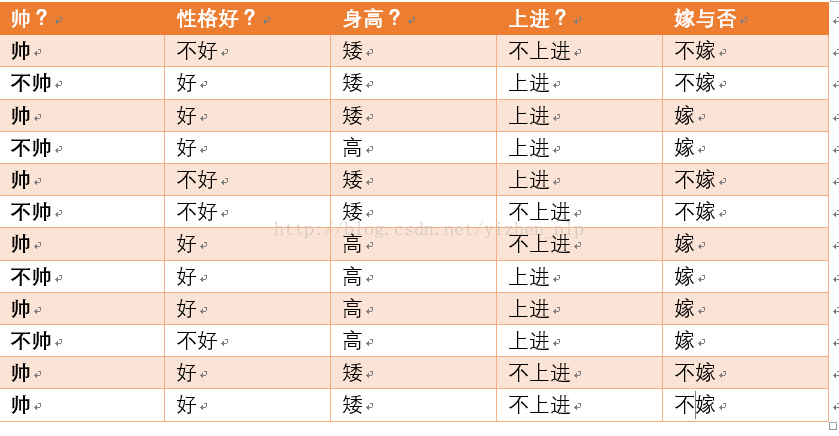
现在给我们的问题是,如果一对男女朋友,男生想女生求婚,男生的四个特点分别是不帅,性格不好,身高矮,不上进,请你判断一下女生是嫁还是不嫁?
这是一个典型的分类问题,转为数学问题就是比较p(嫁|(不帅、性格不好、身高矮、不上进))与p(不嫁|(不帅、性格不好、身高矮、不上进))的概率,谁的概率大,我就能给出嫁或者不嫁的答案!
这里我们联系到朴素贝叶斯公式:
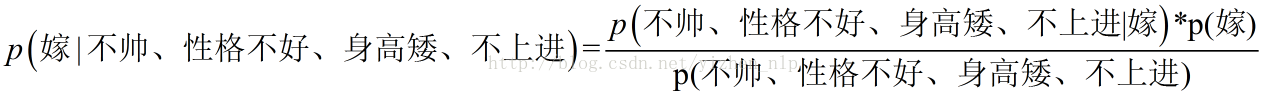
我们需要求p(嫁|(不帅、性格不好、身高矮、不上进),这是我们不知道的,但是通过朴素贝叶斯公式可以转化为好求的三个量.
p(不帅、性格不好、身高矮、不上进|嫁)、p(不帅、性格不好、身高矮、不上进)、p(嫁)(至于为什么能求,后面会讲,那么就太好了,将待求的量转化为其它可求的值,这就相当于解决了我们的问题!)
4 朴素贝叶斯算法的朴素一词解释
那么这三个量是如何求得?
是根据已知训练数据统计得来,下面详细给出该例子的求解过程。
回忆一下我们要求的公式如下:
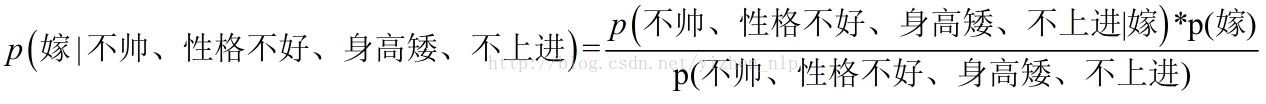
那么我只要求得p(不帅、性格不好、身高矮、不上进|嫁)、p(不帅、性格不好、身高矮、不上进)、p(嫁)即可,好的,下面我分别求出这几个概率,最后一比,就得到最终结果。
p(不帅、性格不好、身高矮、不上进|嫁) = p(不帅|嫁)*p(性格不好|嫁)*p(身高矮|嫁)*p(不上进|嫁),那么我就要分别统计后面几个概率,也就得到了左边的概率!
等等,为什么这个成立呢?学过概率论的同学可能有感觉了,这个等式成立的条件需要特征之间相互独立吧!
对的!这也就是为什么朴素贝叶斯分类有朴素一词的来源,朴素贝叶斯算法是假设各个特征之间相互独立,那么这个等式就成立了!
但是为什么需要假设特征之间相互独立呢?
1、我们这么想,假如没有这个假设,那么我们对右边这些概率的估计其实是不可做的,这么说,我们这个例子有4个特征,其中帅包括{帅,不帅},性格包括{不好,好,爆好},身高包括{高,矮,中},上进包括{不上进,上进},那么四个特征的联合概率分布总共是4维空间,总个数为2*3*3*2=36个。
36个,计算机扫描统计还可以,但是现实生活中,往往有非常多的特征,每一个特征的取值也是非常之多,那么通过统计来估计后面概率的值,变得几乎不可做,这也是为什么需要假设特征之间独立的原因。
2、假如我们没有假设特征之间相互独立,那么我们统计的时候,就需要在整个特征空间中去找,比如统计p(不帅、性格不好、身高矮、不上进|嫁),
我们就需要在嫁的条件下,去找四种特征全满足分别是不帅,性格不好,身高矮,不上进的人的个数,这样的话,由于数据的稀疏性,很容易统计到0的情况。 这样是不合适的。
根据上面俩个原因,朴素贝叶斯法对条件概率分布做了条件独立性的假设,由于这是一个较强的假设,朴素贝叶斯也由此得名!这一假设使得朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率。
好的,上面我解释了为什么可以拆成分开连乘形式。那么下面我们就开始求解!
我们将上面公式整理一下如下:

下面我将一个一个的进行统计计算(在数据量很大的时候,根据中心极限定理,频率是等于概率的,这里只是一个例子,所以我就进行统计即可)。
p(嫁)=?
首先我们整理训练数据中,嫁的样本数如下:
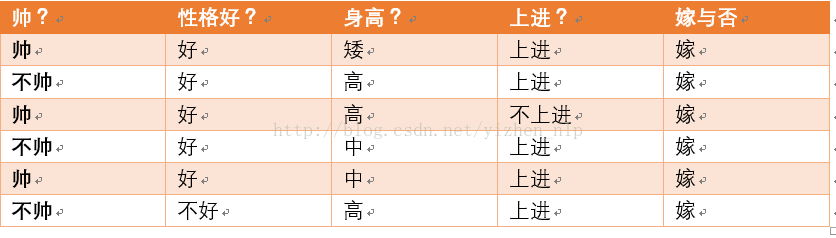
则 p(嫁) = 6/12(总样本数) = 1/2
p(不帅|嫁)=?统计满足样本数如下:

则p(不帅|嫁) = 3/6 = 1/2 在嫁的条件下,看不帅有多少
p(性格不好|嫁)= ?统计满足样本数如下:

则p(性格不好|嫁)= 1/6
p(矮|嫁) = ?统计满足样本数如下:
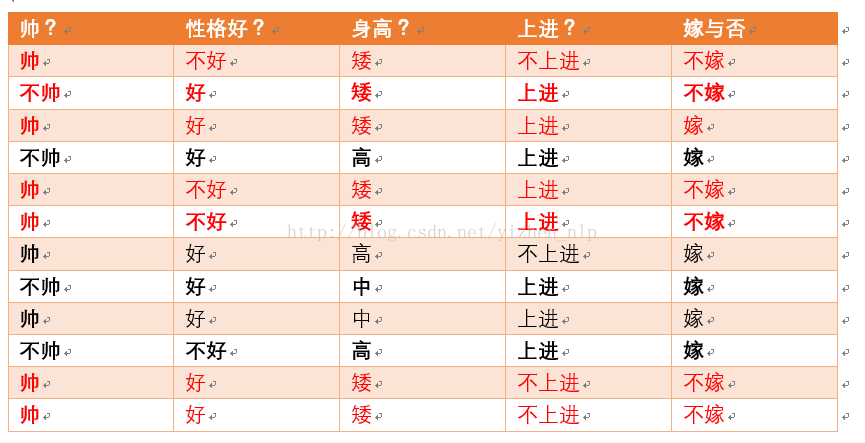
则p(矮|嫁) = 1/6
p(不上进|嫁) = ?统计满足样本数如下:

则p(不上进|嫁) = 1/6
下面开始求分母,p(不帅),p(性格不好),p(矮),p(不上进)
统计样本如下:
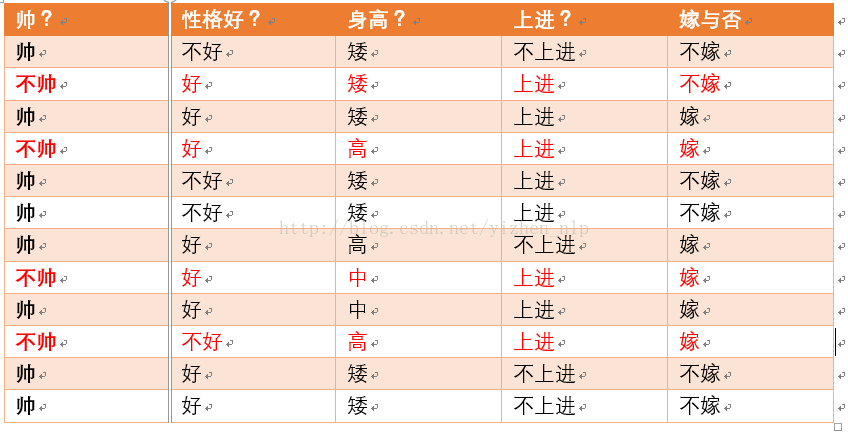
不帅统计如上红色所示,占4个,那么p(不帅) = 4/12 = 1/3
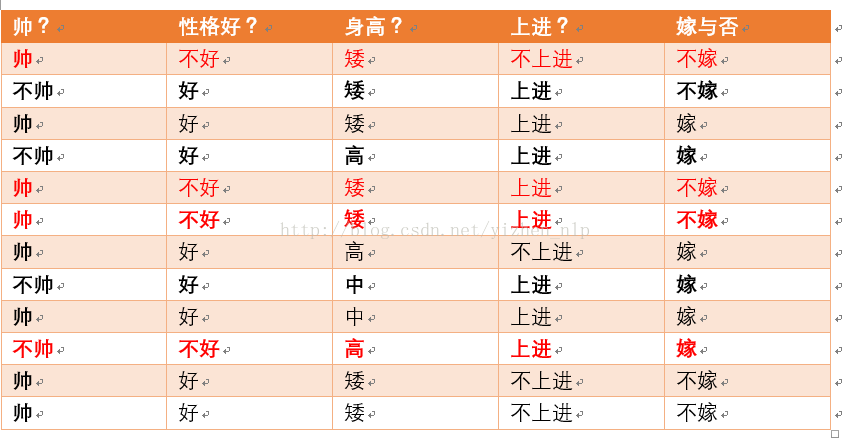
性格不好统计如上红色所示,占4个,那么p(性格不好) = 4/12 = 1/3
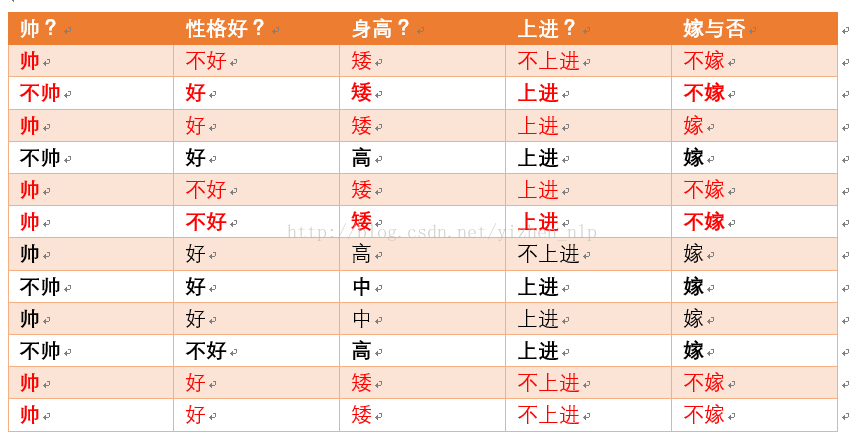
身高矮统计如上红色所示,占7个,那么p(身高矮) = 7/12
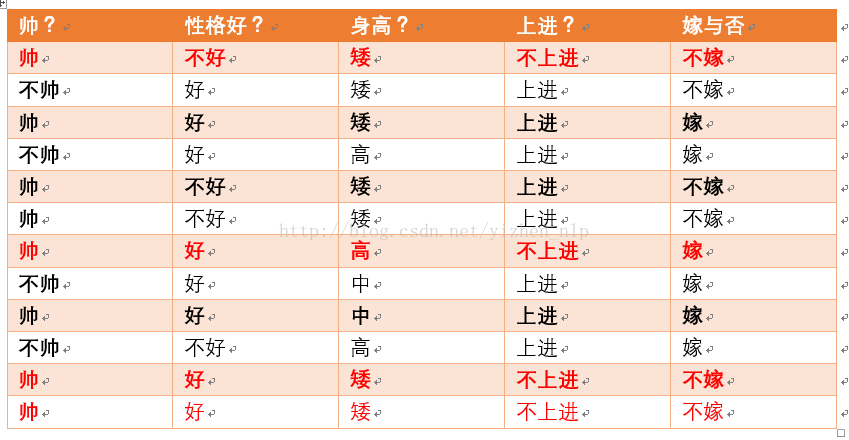
不上进统计如上红色所示,占4个,那么p(不上进) = 4/12 = 1/3
到这里,要求p(不帅、性格不好、身高矮、不上进|嫁)的所需项全部求出来了,下面我带入进去即可,

= (1/2*1/6*1/6*1/6*1/2)/(1/3*1/3*7/12*1/3)
下面我们根据同样的方法来求p(不嫁|不帅,性格不好,身高矮,不上进),完全一样的做法,为了方便理解,我这里也走一遍帮助理解。首先公式如下:

下面我也一个一个来进行统计计算,这里与上面公式中,分母是一样的,于是我们分母不需要重新统计计算!
p(不嫁)=?根据统计计算如下(红色为满足条件):
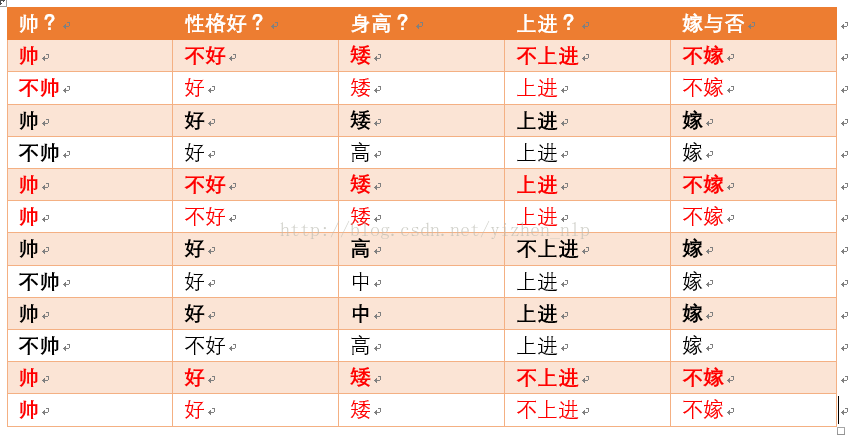
则p(不嫁)=6/12 = 1/2
p(不帅|不嫁) = ?统计满足条件的样本如下(红色为满足条件):
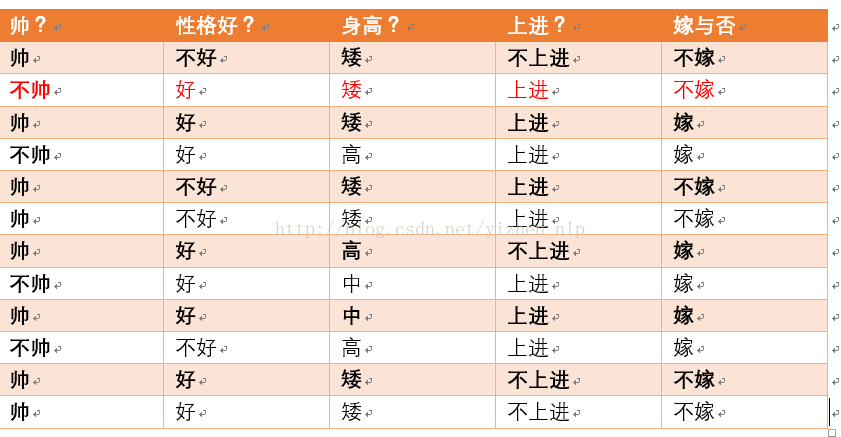
则p(不帅|不嫁) = 1/6
p(性格不好|不嫁) = ?据统计计算如下(红色为满足条件):
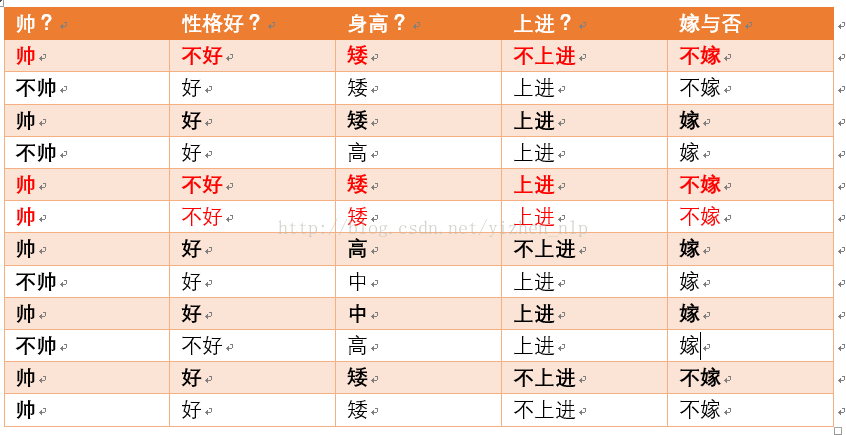
则p(性格不好|不嫁) =3/6 = 1/2
p(矮|不嫁) = ?据统计计算如下(红色为满足条件):
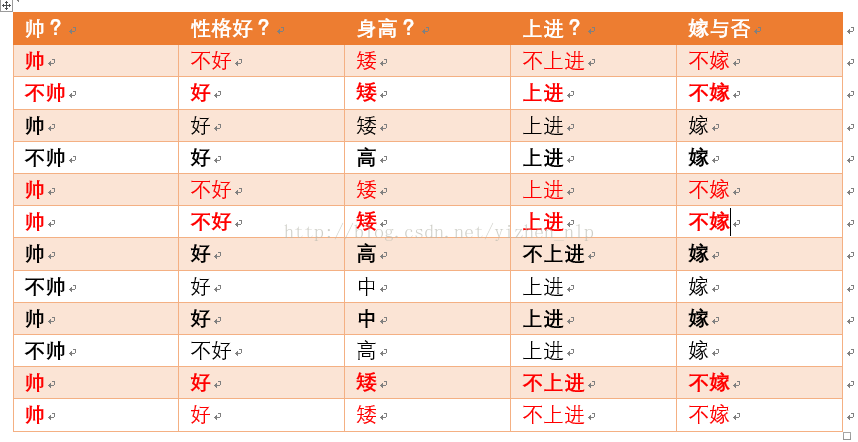
则p(矮|不嫁) = 6/6 = 1
p(不上进|不嫁) = ?据统计计算如下(红色为满足条件):
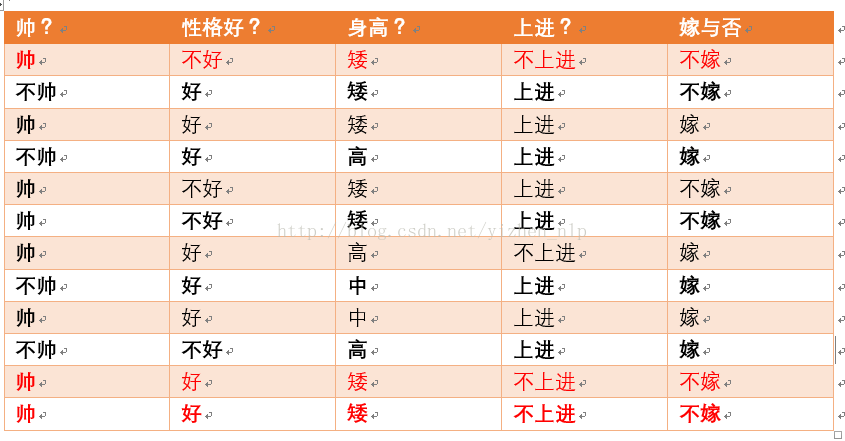
则p(不上进|不嫁) = 3/6 = 1/2
那么根据公式:

p (不嫁|不帅、性格不好、身高矮、不上进) = ((1/6*1/2*1*1/2)*1/2)/(1/3*1/3*7/12*1/3)
很显然(1/6*1/2*1*1/2) > (1/2*1/6*1/6*1/6*1/2)
于是有p (不嫁|不帅、性格不好、身高矮、不上进)>p (嫁|不帅、性格不好、身高矮、不上进)
所以我们根据朴素贝叶斯算法可以给这个女生答案,是不嫁!!!!
5 朴素贝叶斯分类的优缺点
优点:
(1) 算法逻辑简单,易于实现(算法思路很简单,只要使用贝叶斯公式转化医学即可!)
(2)分类过程中时空开销小(假设特征相互独立,只会涉及到二维存储)
缺点:
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
整个例子详细的讲解了朴素贝叶斯算法的分类过程,希望对大家的理解有帮助~
参考:李航博士《统计学习方法》
算法杂货铺--分类算法之朴素贝叶斯分类(Naive Bayesian classification)
(原文链接:https://blog.csdn.net/ccblogger/article/details/81712351)
以上是关于分类算法 - 朴素贝叶斯算法的主要内容,如果未能解决你的问题,请参考以下文章