LSTM神经网络输入输出究竟是怎样的?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LSTM神经网络输入输出究竟是怎样的?相关的知识,希望对你有一定的参考价值。
输入输出都是向量,或者说是矩阵。LSTM用于分类的话,后面一般会接softmax层。个人浅薄理解,拿动作识别分类举例,每个动作帧放入LSTM中训练,还是根据task来训练每个LSTM单元的Weights。所以LSTM的单元数量跟输入和输出都没有关系,甚至还可以几层LSTM叠加起来用。分类的话,一般用最后一个单元接上softmax层。LSTM结构是传统的RNN结构扩展,解决了传统RNN梯度消失/爆炸的问题,从而使得深层次的网络更容易训练。从这个角度理解,可能会容易很多。今年的ResNet也是使传统的CNN更容易训练weights。看来deeplearning越来越深是趋势啊。如果说训练,就一个关键,所谓LSTMUnroll,将RNN展开成一个静态的“并行”网络,内部有“侧向连接”,实现长的短时记忆功能(状态“记忆”在LSTMCell里)。如果说预测,也就一个关键,要将Cell的h和C弄出来,作为当前状态(也就是所谓“记忆”)作为init参数输入,这样,携带了当前记忆状态的网络,预测得到的就是下一个输入了,所谓的recurrent了。那份代码里还包含了一个使用cudnn的实现(built-inRNNoperator),这是一个高性能的版本,可以真正干活的。原来我也尝试搞懂一些天书般的公式,很快发现从那里入手是个错误。强烈推荐:理解LSTM网络(翻译自UnderstandingLSTMNetworks)只要有一点点CNN基础+半个小时,就可以通过这篇文章理解LSTM的基础原理。回答你的问题:和神经元个数无关,不知道你是如何理解“神经元”这个概念的,输入输出层保证tensor的维数和输入输出一致就可以了。
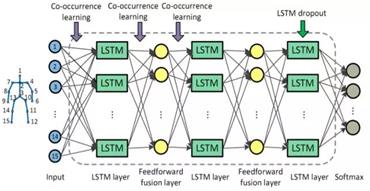
常规feedforward输入和输出:矩阵输入矩阵形状:(n_samples,dim_input)输出矩阵形状:(n_samples,dim_output)注:真正测试/训练的时候,网络的输入和输出就是向量而已。加入n_samples这个维度是为了可以实现一次训练多个样本,求出平均梯度来更新权重,这个叫做Mini-batchgradientdescent。如果n_samples等于1,那么这种更新方式叫做StochasticGradientDescent(SGD)。Feedforward的输入输出的本质都是单个向量。常规Recurrent(RNN/LSTM/GRU)输入和输出:张量输入张量形状:(time_steps,n_samples,dim_input)输出张量形状:(time_steps,n_samples,dim_output)注:同样是保留了Mini-batchgradientdescent的训练方式,但不同之处在于多了timestep这个维度。Recurrent的任意时刻的输入的本质还是单个向量,只不过是将不同时刻的向量按顺序输入网络。所以你可能更愿意理解为一串向量asequenceofvectors,或者是矩阵。
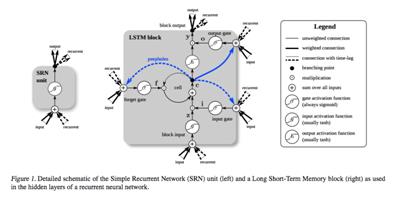
关于如何输入的问题,LSTM是一个序列模型,对于输入数据也是一个序列,LSTM每个时间步处理的是序列中一个时刻的输入,比如你当前输入是一个汉字“我”,因为模型只能接受的是数值向量,因此需要embedding,“我”就需要变成了一个向量,假如是[0.1,0.8,3.2,4.3](通过wordembedding技术获得),这里向量维度是4,那么就需要4个神经元去接收向量中的每个元素,而这四个神经元就构成了当前时刻的LSTMUnit,其他时刻也是这样,从而完成输入。因此就可以知道输入层神经元(LSTMunit中神经元数)的个数等于词向量的size。
以上是关于LSTM神经网络输入输出究竟是怎样的?的主要内容,如果未能解决你的问题,请参考以下文章
回归预测 | MATLAB实现GA-LSTM遗传算法优化长短期记忆网络的数据多输入单输出回归预测
理解 LSTM 中的输入和输出形状 | tf.keras.layers.LSTM(以及对于return_sequences的解释)
LSTM回归预测基于matlab TPA-LSTM时间注意力机制长短期记忆神经网络回归预测(多输入单输出)含Matlab源码 1984期