Storm与Hadoop的角色和组件比较
Posted 大数据和人工智能躺过的坑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Storm与Hadoop的角色和组件比较相关的知识,希望对你有一定的参考价值。
不多说,直接上干货!
Storm与Hadoop的角色和组件比较
Storm 集群和 Hadoop 集群表面上看很类似。但是 Hadoop 上运行的是 MapReduce 作业,而在 Storm 上运行的是拓扑 Topology,这两者之间是非常不同的。一个关键的区别是:一个MapReduce 作业最终会结束,而一个 Topology 拓扑会永远运行(除非手动杀掉)。表 1-1 列出了 Hadoop 与 Storm 的不同之处。
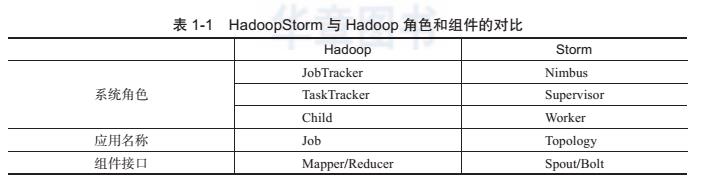
如果只用一个短语来描述 Storm,可能会是这样:分布式实时计算系统。按照 Storm作者的说法, Storm对于实时计算的意义类似于 Hadoop 对于批处理的意义。众所周知,根据Google MapReduce 来实现的 Hadoop 提供了 Map 和 Reduce 原语,使批处理程序变得非常简单和优美。那么 Storm 则是在批处理之前,及时处理了数据。
Storm 与其他大数据解决方案的不同之处在处理方式上。Hadoop 在本质上是一个批处理系统。数据被引入 HDFS 并分发到各个节点进行处理。当处理完成时,结果数据返回到HDFS 供始发者使用。 Storm 支持创建拓扑结构来转换没有终点的数据流。不同于 Hadoop 作业,这些转换从不停止,它们会持续处理到达的数据。
Hadoop 专注于批处理。这种模型对许多情形(如为网页建立索引)已经足够,但还存在其他一些使用模型,它们需要来自高度动态来源的实时信息。为了解决该问题,就得借助 Twitter 推出的 Storm。 Storm 不处理静态数据,但它处理预计会连续的流数据。考虑到Twitter 用户每天生成 1.4 亿条推文,很容易看到此技术的巨大用途。
Storm 不只是一个传统的大数据分析系统:它是复杂事件处理(CEP)系统的一个示例。CEP 系统通常分为计算和面向检测两类,其中每个系统都可通过用户定义的算法在 Storm 中实现。例如, CEP 可用于识别事件洪流中有意义的事件,然后实时处理这些事件。
Storm 作者 Nathan Marz 提供了在 Twitter 中使用 Storm 的大量示例。一个最有趣的示例是生成趋势信息。 Twitter 从海量的推文中提取所浮现的趋势,并在本地和国家级别维护这些趋势信息。这意味着当一个案例开始浮现时, Twitter 的趋势主题算法就会实时识别该主题。这种实时算法是使用 Storm 实现的基于 Twitter 数据的一种连续分析。

以上是关于Storm与Hadoop的角色和组件比较的主要内容,如果未能解决你的问题,请参考以下文章
聊聊批计算、流计算、Hadoop、Spark、Storm、Flink等等