mysql索引以及优化
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql索引以及优化相关的知识,希望对你有一定的参考价值。
今天看到别人写的一些关于mysql索引的文章,有一些小收获,就以此开启我的随笔记录简单摘了一些重点
转载文章:http://www.cnblogs.com/tgycoder/p/5410057.html
mysql索引实现原理
1. MyISAM引擎使用B+Tree作为索引结构,叶结点的data域存放的是数据记录的地址,MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
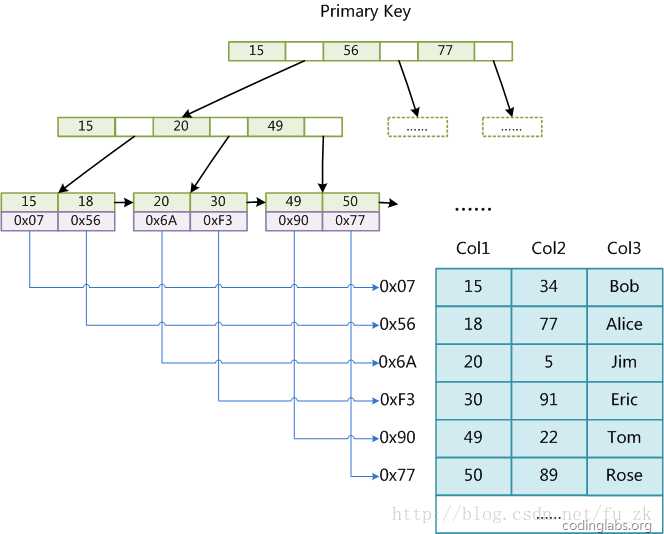
2. InnoDB也使用B+Tree作为索引结构,第一个重大区别是InnoDB的数据文件本身就是索引文件,第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶结点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引
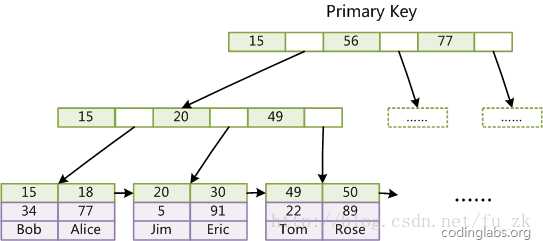
InnoDB主索引(同时也是数据文件)的示意图,可以看到叶结点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
3. 最左前缀与相关优化
之前我理解的最左前缀以为索引的顺序是跟where条件查询的一致不一致就使用不到索引,这是错误的
Ps:最左前缀原则中where字句有or出现还是会遍历全表
(1) 其实where条件的顺序不影响使用索引,比如三个字段添加联合索引t_user表联合索引(name, mobile, create_date)
select * from t_user where mobile = ‘13256767876‘ and create_date= ‘2017-07-31‘ and name = ‘corner‘;
理论上索引对顺序是敏感的,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以使用适合的索引,所以这样也是可以用到索引的
(2)查询条件没有指定索引第一列
如果where条件中没有name条件,只有另外两个无论顺序是什么都是无法用到索引的,如果where条件只有name,status而没有mobile这时候只能用到一列索引,status这一列的索引是用不到的
(3)范围查询
范围列可以用到索引(必须是最左前缀),但是范围列后面的列无法用到索引。同时,索引最多用于一个范围列,因此如果查询条件中有两个范围列则无法全用到索引
表t_title联合索引(emp_no,title,from_date)
EXPLAIN SELECT * FROM employees.titles
WHERE emp_no < ‘10010‘
AND title=‘Senior Engineer‘
AND from_date BETWEEN ‘1986-01-01‘ AND ‘1986-12-31‘;
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 4 | NULL | 16 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
只能用到第一列索引,这里特别要说明MySQL一个有意思的地方,那就是仅用explain可能无法区分范围索引和多值匹配,因为在type中这两者都显示为range。同时,用了“between”并不意味着就是范围查询,例如下面的查询:
全部索引都用到了
EXPLAIN SELECT * FROM employees.titles
WHERE emp_no BETWEEN ‘10001‘ AND ‘10010‘
AND title=‘Senior Engineer‘
AND from_date BETWEEN ‘1986-01-01‘ AND ‘1986-12-31‘;
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 59 | NULL | 16 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
(4)查询条件中含有函数或表达式
如果查询条件中含有函数或表达式,则MySQL不会为这列使用索引
like如果通配符%不出现在开头,则可以用到索引,但根据具体情况不同可能只会用其中一个前缀
EXPLAIN SELECT * FROM employees.titles WHERE emp_no=‘10001‘ AND title LIKE ‘Senior%‘;
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 56 | NULL | 1 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
4.索引选择性与前缀索引
(1)什么情况下判断字段是否应该建立索引,今天刚看到这个"选择性"的概念,除了表数据很少的情况不用建索引因为索引文件本身要消耗存储空间会加重数据库操作的负担,另外一种情况就是索引的选择性比较低:
所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值:Index Selectivity = Cardinality / #T
显然选择性的取值范围为(0, 1],选择性越高的索引价值越大,这是由B+Tree的性质决定的。
这个问题就像是面试时提问我的一个问题:性别列适不适合建立索引?(答案是否定的)
例如,上文用到的employees.titles表,如果title字段经常被单独查询,是否需要建索引,我们看一下它的选择性:
SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles;
+-------------+
| Selectivity |
+-------------+
| 0.0000 |
+-------------+
title的选择性不足0.0001(精确值为0.00001579),所以实在没有什么必要为其单独建索引。
(2)有一种与索引选择性有关的索引优化策略叫做前缀索引,就是用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。下面以employees.employees表为例介绍前缀索引的选择和使用。
从图12可以看到employees表只有一个索引<emp_no>,那么如果我们想按名字搜索一个人,就只能全表扫描了:
EXPLAIN SELECT * FROM employees.employees WHERE first_name=‘Eric‘ AND last_name=‘Anido‘;
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
如果频繁按名字搜索员工,这样显然效率很低,因此我们可以考虑建索引。有两种选择,建<first_name>或<first_name, last_name>,看下两个索引的选择性:

SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.0042 |
+-------------+
SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.9313 |
+-------------+
<first_name>显然选择性太低,<first_name, last_name>选择性很好,但是first_name和last_name加起来长度为30,有没有兼顾长度和选择性的办法?可以考虑用first_name和last_name的前几个字符建立索引,例如<first_name, left(last_name, 3)>,看看其选择性:
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.7879 |
+-------------+
选择性还不错,但离0.9313还是有点距离,那么把last_name前缀加到4:
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.9007 |
+-------------+
这时选择性已经很理想了,而这个索引的长度只有18,比<first_name, last_name>短了接近一半,我们把这个前缀索引 建上:
ALTER TABLE employees.employees
ADD INDEX first_name_last_name4 (first_name, last_name(4));
此时再执行一遍按名字查询,比较分析一下与建索引前的结果:
SHOW PROFILES;
+----------+------------+---------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------------------------------------+
| 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name=‘Eric‘ AND last_name=‘Anido‘ |
| 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name=‘Eric‘ AND last_name=‘Anido‘ |
+----------+------------+---------------------------------------------------------------------------------+
以上是关于mysql索引以及优化的主要内容,如果未能解决你的问题,请参考以下文章