SQL Server创建复合索引时,复合索引列顺序对查询的性能影响
Posted 有梦就能实现
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL Server创建复合索引时,复合索引列顺序对查询的性能影响相关的知识,希望对你有一定的参考价值。
说说复合索引
写索引的博客太多了,一直不想动手写,有一下两个原因:
一是觉得有炒剩饭的嫌疑,有兄弟曾说:索引吗,只要在查询条件上建索引就行了,真的可以这么暴力吗?
二来觉得,索引是个非常大的话题,很难概括出所有的情况,你不整出点新意来,倒是有抄袭照搬的嫌疑
既然写了,就写一点稍微不一样的东西出来,
好了,废话打住,
/*
20160814备注:今天发现一个类似的文章:http://www.cnblogs.com/fly_zj/archive/2012/08/11/2633629.html ;
可以理解为:添加组合索引时,做相等运算字段应该放在最前面
但这么说也不完全准确,应该说是,将选择性高的字段,放在最前面,通俗说就是,将最有效的过滤条件,方式复合索引的第一位
*/
搭建测试环境:
创建一张表,模拟实际业务中的一个表,往里面填入数据,时间字段上,相对按照时间均匀地填充,其他字段以GUID填充

Create table BusinessInfoTable
(
BuniessCode1 varchar(50),
BuniessCode2 varchar(50),
BuniessCode3 varchar(50),
BuniessCode4 varchar(50),
BuniessStatus1 tinyint,
BuniessStatus2 tinyint,
BuniessDateTime1 Datetime,
BuniessDateTime2 Datetime,
OtherColumn1 varchar(50),
OtherColumn2 varchar(50),
OtherColumn3 varchar(50)
)
declare @i int=0
while @i<1000000
begin
insert into BusinessInfoTable
values
(
NEWID(),NEWID(),NEWID(),NEWID(),RAND()*100,RAND()*100,
DATEADD(MI,@i,GETDATE()),DATEADD(MI,@i,GETDATE()),NEWID(),NEWID(),NEWID()
)
set @i=@i+1
end
现在有这么一个查询(实际上查询远比这个复杂,简化一点,不要刻意造环境)
select OtherColumn2,
BuniessStatus1,
BuniessStatus2,
BuniessDateTime1,
BuniessDateTime2
from BusinessInfoTable
where BuniessDateTime1 between \'2016-6-21\' and \'2016-6-28\'
and BuniessDateTime2 between \'2016-6-21\' and \'2016-6-28\'
and BuniessStatus1 = 55
and BuniessStatus2 = 66
说明一点:
暂时不考虑聚集索引,毕竟一个表上只能有一个聚集索引,
别人也不是傻子,不会轻易去建聚集索引,聚集索引早被占用了
既然被占用了,原则是一般不去动别人现有的东西的,比如别人建了聚集索引,你给人家删了,根据自己的情况建聚集索引,这不是找*么
有经验的你一定考虑符合索引了,同时考虑到为避免Key Lookup导致的书签查找,我们把查询索要的OtherColumn2列include进来
比如这样
CREATE NONCLUSTERED INDEX IDX_1 ON BusinessInfoTable (BuniessStatus1,BuniessStatus2,BuniessDateTime1,BuniessDateTime2) INCLUDE(OtherColumn2)
或者这样,只是索引前导列顺序不一样
CREATE NONCLUSTERED INDEX IDX_2 ON BusinessInfoTable (BuniessDateTime1,BuniessDateTime2,BuniessStatus1,BuniessStatus2) INCLUDE(OtherColumn2)
当然可以随意调整四个列的顺序,我就不过多地做演示了,有兴趣的自己试
这里的前导列的顺序并不会影响到索引的使用,查询的时候都是非聚集索引Seek,绝对的
那么问题来了,完全一样的查询条件,结果一样,使用不同的索引,索引的区别仅仅是列顺序不一样,其代价一样吗,有区别吗?
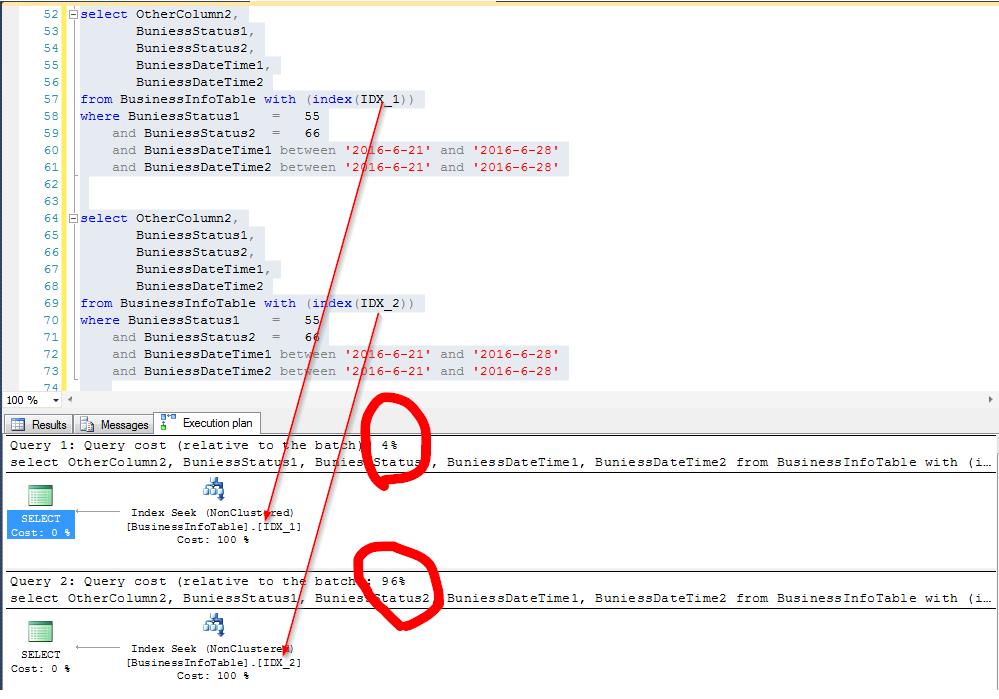
同样查询,使用不同索引的结果(分别是上面的IDX_1和IDX_2):
下面看图说话
看看IO情况
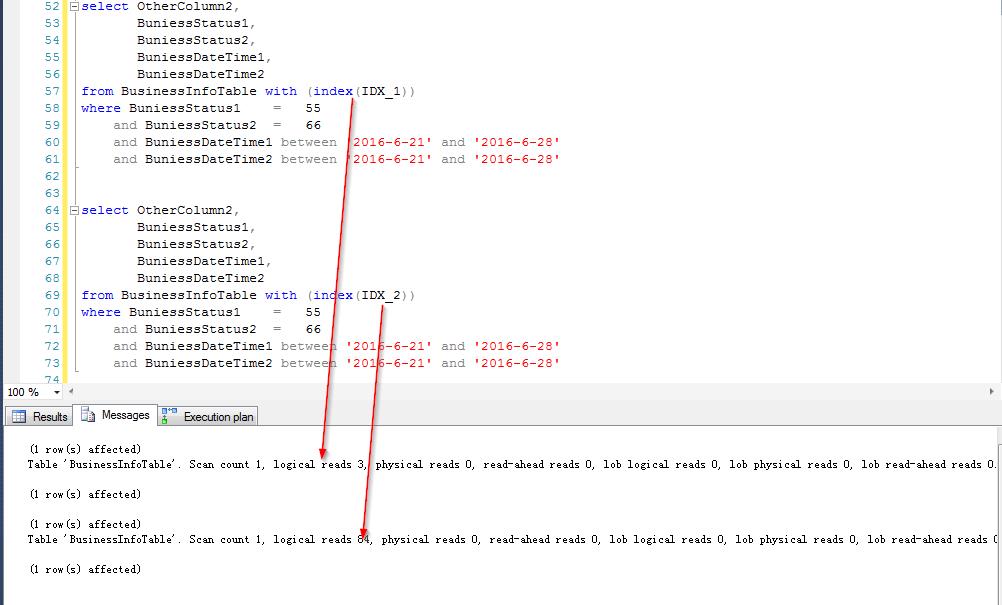
原因分析:
看来是有点差别吧,好似乎这个差别还真不小。
究竟原因在何?
索引是以平衡树(B树)的方式存在的,复合索引的列的顺序决定了B树的信息的存储的顺序
如果是以BuniessStatus1列为前导列,因为BuniessStatus1分布的范围(相对)较小,
这样在查询的时候通过BuniessStatus1=55就可以过滤出来一个比较小的结果集,后面依次用其他条件过滤就相对较快了
比如BuniessStatus1=55过滤出来符合条件的数据有5条,加上BuniessStatus2 BuniessDateTime1 BuniessDateTime2 这三个条件再过滤,出来一条数据。
如果BuniessDateTime1 是索引的前导列,用BuniessDateTime1 between \'2016-6-21\' and \'2016-6-28\'过滤 ,可能会有10000条数据,
然后依次再用 BuniessDateTime2,BuniessStatus1, BuniessStatus2过滤,最后也只有一条符合条件的数据。
差别就在于:一开始的过滤条件,决定了查询多少page初步确定满足条件的数据,再进一步的进行过滤
如果最开始就相对精确地确定了满足查询条件的数据范围,后面可以通过相对较小的代价来最终确认出满足条件的数据
如果最开始相对模糊地却确定了满足查询条件的数据范围,那么这个过程的代价就相对比较大,虽然后面通过每一个条件的过,结果是一样的
当然这种索引的建立跟数据分布有关,但是,这里没有下结论说,复合索引一定要按照什么什么顺序来是最好的
还是那句话:具体问题具体分析,避免经验主义,没有一刀切的手段可以解决所有的问题。
总结:
本文通过一个简单的例子,分析了创建符合索引时,列的顺序对查询的影响,
说明在创建索引的时候,不仅仅要考虑在哪些列上创建索引,同时也要注意到,索引列的顺序,是否会对查询产生影响。
避免一说到索引,就是“在查询条件上建索引”的暴力做法。
以上是关于SQL Server创建复合索引时,复合索引列顺序对查询的性能影响的主要内容,如果未能解决你的问题,请参考以下文章
SQL Server创建复合索引时,复合索引列顺序对查询的性能影响
SQL Server创建复合索引时,复合索引列顺序对查询的性能影响
sql server 2005 一个索引多个字段,字段的排列顺序对搜索有啥影响??