Streampark集成Cloudera Flinkldap告警,以及部署常见问题
Posted 酥酥饼一号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Streampark集成Cloudera Flinkldap告警,以及部署常见问题相关的知识,希望对你有一定的参考价值。
集成背景
我们当前集群使用的是Cloudera CDP,Flink版本为Cloudera Version 1.14,整体Flink安装目录以及配置文件结构与社区版本有较大出入。直接根据Streampark官方文档进行部署,将无法配置Flink Home,以及后续整体Flink任务提交到集群中,因此需要进行针对化适配集成,在满足使用需求上,尽量提供完整的Streampark使用体验。
集成步骤
版本匹配问题解决
首先解决无法识别Cloudera中的Flink Home问题,根据报错主要明确到的事情是无法读取到Flink版本、lib下面的jar包名称无法匹配。
修改对象:
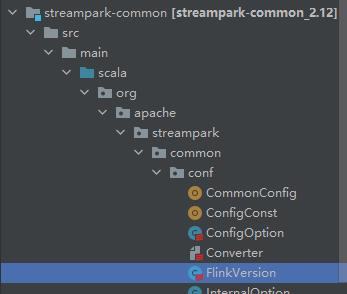
修改源码:(解决无法匹配cloudera jar包)
class FlinkVersion(val flinkHome: String) extends java.io.Serializable with Logger
private[this] lazy val FLINK_VER_PATTERN = Pattern.compile("^(\\\\d+\\\\.\\\\d+)(\\\\.)?.*$")
private[this] lazy val FLINK_VERSION_PATTERN = Pattern.compile("^Version: (\\\\d+\\\\.\\\\d+\\\\.\\\\d)(-csa)?(\\\\d+\\\\.\\\\d+\\\\.\\\\d+\\\\.\\\\d)?, Commit ID: (.*)$")
private[this] lazy val FLINK_SCALA_VERSION_PATTERN = Pattern.compile("^flink-dist_(\\\\d+\\\\.\\\\d*)-(\\\\d+\\\\.\\\\d+\\\\.\\\\d)(-csa.*)?.jar$")
lazy val scalaVersion: String =
val matcher = FLINK_SCALA_VERSION_PATTERN.matcher(flinkDistJar.getName)
if (matcher.matches())
matcher.group(1);
else
// flink 1.15 + on support scala 2.12
"2.12"
lazy val fullVersion: String = s"$version_$scalaVersion"
lazy val flinkLib: File =
require(flinkHome != null, "[StreamPark] flinkHome must not be null.")
require(new File(flinkHome).exists(), "[StreamPark] flinkHome must be exists.")
val lib = new File(s"$flinkHome/lib")
require(lib.exists() && lib.isDirectory, s"[StreamPark] $flinkHome/lib must be exists and must be directory.")
lib
lazy val flinkLibs: List[NetURL] = flinkLib.listFiles().map(_.toURI.toURL).toList
lazy val version: String =
val flinkVersion = new AtomicReference[String]
val cmd = List(s"java -classpath $flinkDistJar.getAbsolutePath org.apache.flink.client.cli.CliFrontend --version")
val success = new AtomicBoolean(false)
val buffer = new mutable.StringBuilder
CommandUtils.execute(
flinkLib.getAbsolutePath,
cmd,
new Consumer[String]()
override def accept(out: String): Unit =
buffer.append(out).append("\\n")
val matcher = FLINK_VERSION_PATTERN.matcher(out)
if (matcher.find)
success.set(true)
flinkVersion.set(matcher.group(1))
)
logInfo(buffer.toString())
if (!success.get())
throw new IllegalStateException(s"[StreamPark] parse flink version failed. $buffer")
buffer.clear()
flinkVersion.get
// flink major version, like "1.13", "1.14"
lazy val majorVersion: String =
if (version == null)
null
else
val matcher = FLINK_VER_PATTERN.matcher(version)
matcher.matches()
matcher.group(1)
lazy val flinkDistJar: File =
val distJar = flinkLib.listFiles().filter(_.getName.matches("flink-dist.*\\\\.jar"))
distJar match
case x if x.isEmpty =>
throw new IllegalArgumentException(s"[StreamPark] can no found flink-dist jar in $flinkLib")
case x if x.length > 1 =>
throw new IllegalArgumentException(s"[StreamPark] found multiple flink-dist jar in $flinkLib")
case _ =>
distJar.head
// StreamPark flink shims version, like "streampark-flink-shims_flink-1.13"
lazy val shimsVersion: String = s"streampark-flink-shims_flink-$majorVersion"
override def toString: String =
s"""
|----------------------------------------- flink version -----------------------------------
| flinkHome : $flinkHome
| distJarName : $flinkDistJar.getName
| flinkVersion : $version
| majorVersion : $majorVersion
| scalaVersion : $scalaVersion
| shimsVersion : $shimsVersion
|-------------------------------------------------------------------------------------------
|""".stripMargin
Flink Home指定
由于Cloudera Flink的默认安装路径为/opt/cloudera/parcels/Flink-$version,而执行/opt/cloudera/parcels/Flink-$version/bin/flink 为整体环境配置,vi flink可查看到具体过程
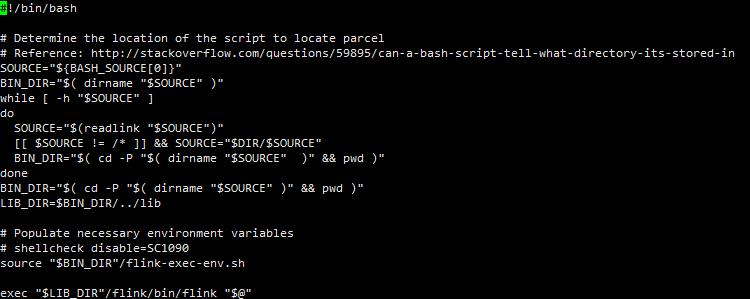
实际的flink提交路径在/opt/cloudera/parcels/Flink-$version/lib/flink/bin/flink,因此/opt/cloudera/parcels/Flink-$version/lib/flink可以理解为真正的Flink Home,具体查看该目录下内容
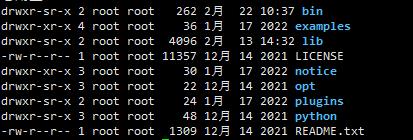
发现缺少conf目录,倘若配置该目录在Streampark为Flink Home将无法访问到集群,因此可软连接Flink配置或者在该路径下编辑集群中的Flink配置文件。

综上,前置配置和打包好代码(代码中可能会涉及到自己使用上的优化修改)之后,可以进行部署。
注意2.0的版本打包的话直接执行源码中的build.sh即可,选择混合部署,生成的包在dist目录下。
部署流程
前置部署流程建议参考官方步骤安装部署 | Apache StreamPark (incubating)
特别注意需要对元数据库进行初始化以及初始数据插入,执行sql在$streamarkHome/script/data&schema
根据官方的意思需要将mysql的connector添加到lib目录下,不然无法连接数据库。
在conf/application.yml中修改数据源为mysql,配置好集群中使用到的用户(默认hdfs),默认在hdfs创建streampark的工作目录hdfs:///streampark。
部署结果验证
部署完成之后,执行bin下的startup.sh 可以启动集群,在web上进入部署地址ip:port(默认10000)
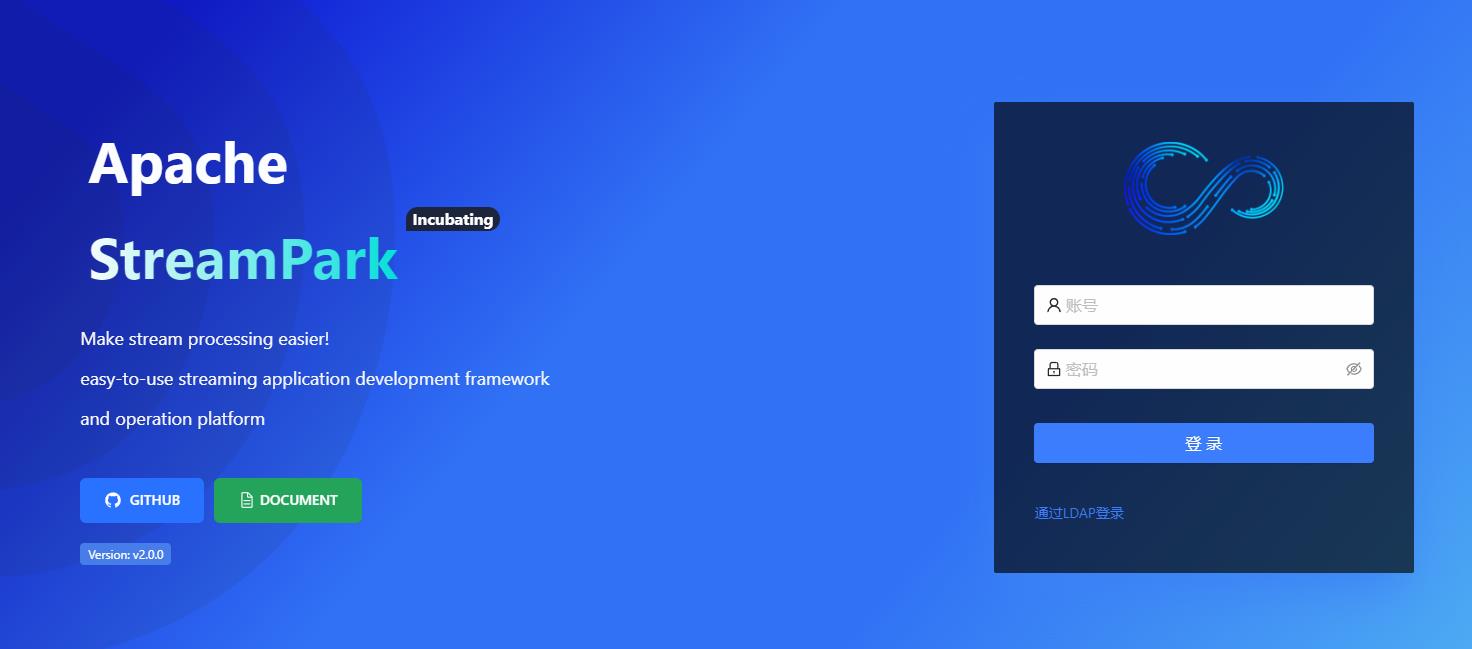
使用默认账号 admin streampark可以进去
登录进去之后点击设置中心可以进行Flink home的配置

LDAP集成
主要是需要配置conf下application.yml中的ldap配置信息即可,然后重启streampark。
使用与踩坑点:
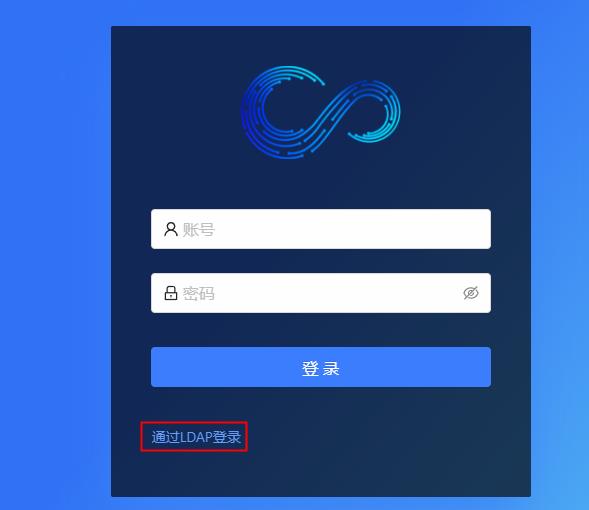
登录选择LDAP登录
利用公司LDAP登录之后,提示

但是刚才使用ladp登录的用户,在streampark上已经创建对应的用户,须在成员管理里面将刚才创建的用户添加到对应的团队中,刚才那个用户才可以登录。
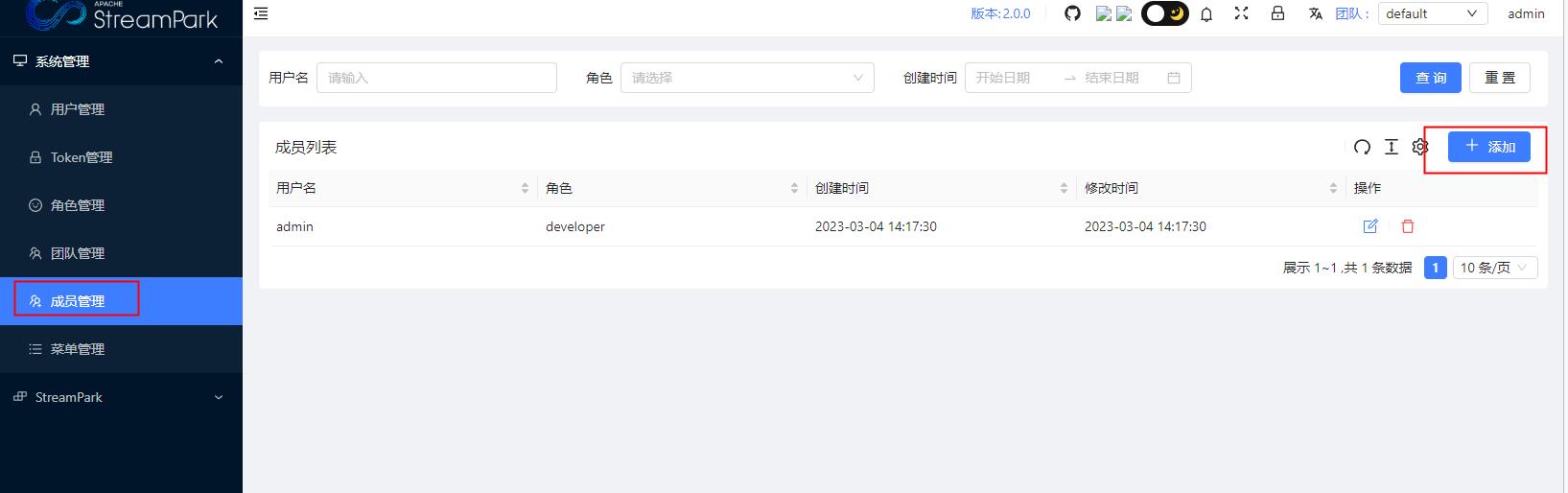
告警配置
主要配置的是企业微信告警,在设置中心配置企业微信机器人的token(注意公司环境为内网的话,需要在代码中修改对应的url,拼接为内网发送地址)
告警模板在代码中的修改路径为:

中间修改了的告警模板,重新打包一下即可。
一些问题及解决办法
一、Hadoop环境
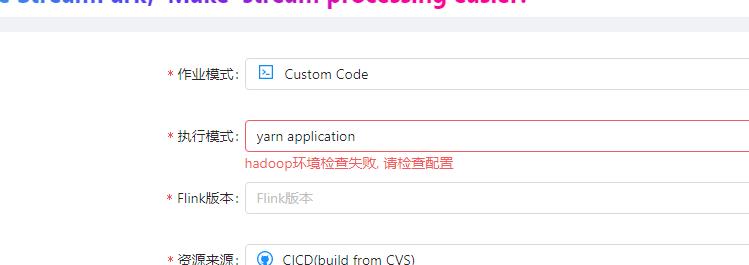
解决办法:在部署Streampark的节点上添加一下hadoop环境即可
vi /etc/profile
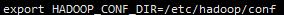
source一下,重启streampark即可
二、依赖jar的初始化
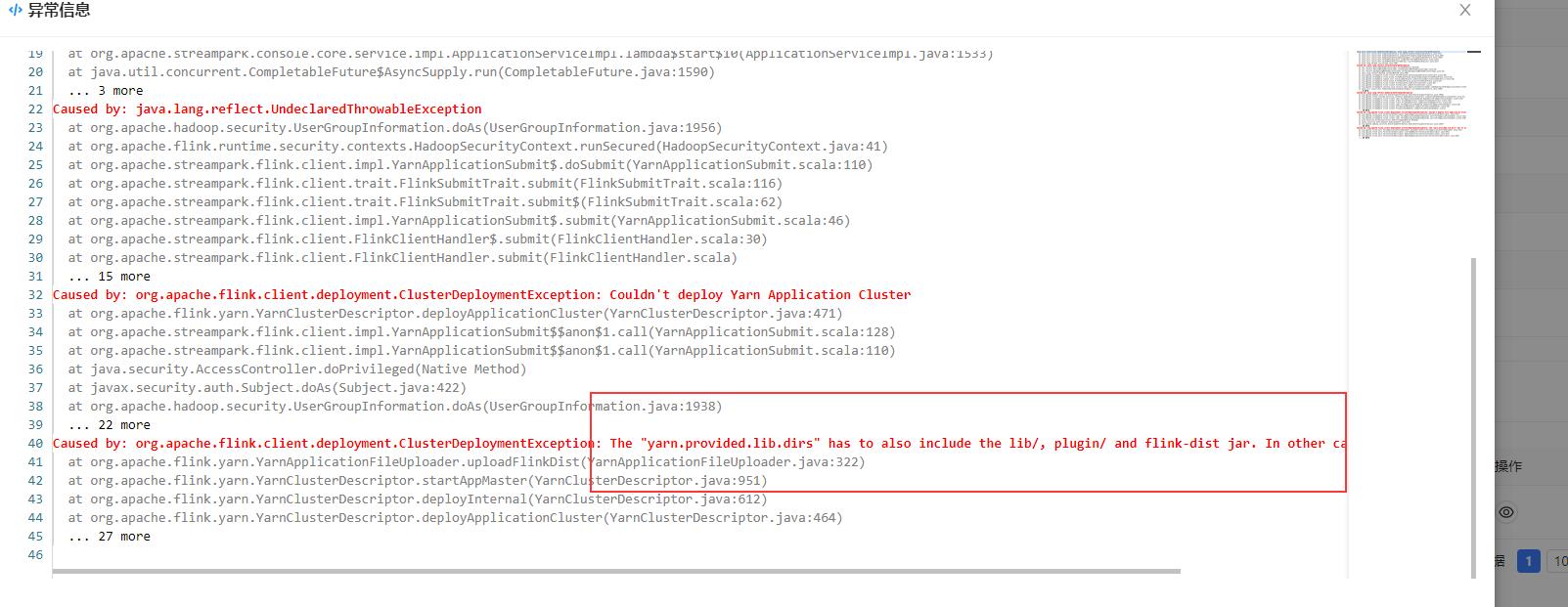
解决办法:在于部署后的streampark在hdfs上的工作目录上lib目录没有正常上传,找到hdfs上初始化的strempark work路径,观察一下hdfs:///streampark/flink/.../下的lib目录是否完整,不完整的话手动将本地Flink Home目录下的lib put上去即可。
以上是关于Streampark集成Cloudera Flinkldap告警,以及部署常见问题的主要内容,如果未能解决你的问题,请参考以下文章
如何将cloudera apache哨句与open ldap集成
Talend BD 5.6 与 Hortonworks Sandbox 2.1 或 Cloudera 5.2 集成面临的问题