如何高效地构建像 ChatGPT 这样的大型 AI 模型?
Posted 禅与计算机程序设计艺术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何高效地构建像 ChatGPT 这样的大型 AI 模型?相关的知识,希望对你有一定的参考价值。
目录
How to build Large AI Models like ChatGPT efficiently如何高效地构建像 ChatGPT 这样的大型 AI 模型
Increasing the Number of Tokens 增加代币数量
Applying Filters and letting simple models do most of your tasks应用过滤器并让简单的模型完成大部分任务
How to build Large AI Models like ChatGPT efficiently
如何高效地构建像 ChatGPT 这样的大型 AI 模型
The techniques you can use to use large data models in your systems without breaking your bank
您可以用来在系统中使用大数据模型而不会破坏您的资金的技术
Large Models have captured a lot of attention from people. By adding more parameters and data to the model, we can add more capabilities to a system. Additional parameters allow for more kinds of connections in your neurons, giving your neural networks both better performance on existing tasks and the ability to develop new kinds of skills, as this gif shows us-
大型模型引起了人们的广泛关注。通过向模型添加更多参数和数据,我们可以为系统添加更多功能。额外的参数允许在你的神经元中建立更多种类的连接,让你的神经网络在现有任务上有更好的表现,并能够开发新的技能,正如这个 gif 向我们展示的那样 -
This image is courtesy of the Pathways system which I covered here此图片由我在此处介绍的 Pathways 系统提供
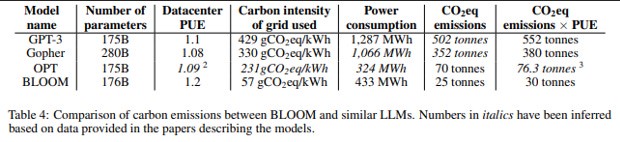
People have been excited about these models and what they can achieve. Pretty much everyone I’ve talked to recently has told me that they are looking to integrate these models into their system. However, there is a huge problem with using these models- they are extremely expensive. According to researchers who wrote, Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model, it took roughly 50.5 tons of CO2 equivalent to train the large-language model BLOOM. GPT-3 released over 500 tons of CO2 equivalent-
人们对这些模型以及它们可以实现的目标感到兴奋。最近与我交谈过的几乎每个人都告诉我,他们正在寻求将这些模型集成到他们的系统中。然而,使用这些模型存在一个巨大的问题——它们极其昂贵。根据撰写“估算 176B 参数语言模型 BLOOM 的碳足迹”的研究人员称,训练大型语言模型 BLOOM 大约需要 50.5 吨二氧化碳当量。 GPT-3 释放了超过 500 吨二氧化碳当量-
It’s no surprise that the most requested topic across the multiple polls I ran on multiple platforms was- How to train Large Machine Learning Models efficiently. So in this article, we will be doing just that, covering various techniques to scale up your training efficiency. Without further ado, let’s go-
毫不奇怪,在我在多个平台上进行的多项民意调查中,请求最多的主题是——如何有效地训练大型机器学习模型。所以在这篇文章中,我们将这样做,涵盖各种技术来提高你的训练效率。话不多说,我们走——
Batch Size 批量大小
The right batch size can be one of the most impactful decisions in your model training. Too many data scientists end up ignoring the power that setting the batch size can have on the performance of their AI Models. So how can you use the batch size to train your large deep-learning models efficiently? The first step is to increase your batch size (I know some of you are screaming about generalization. Read on, I cover that later on).
正确的批量大小可能是模型训练中最有影响力的决定之一。太多的数据科学家最终忽视了设置批量大小对其 AI 模型性能的影响。那么如何使用批量大小有效地训练大型深度学习模型呢?第一步是增加批量大小(我知道你们中的一些人对泛化大喊大叫。继续阅读,我稍后会介绍)。
Larger Batch Sizes mean fewer updates to your model while training. This leads to lower computational costs. But this is not the only thing that makes a difference. In my breakdown of the phenomenal report, “Scaling TensorFlow to 300 million predictions per second”, I was surprised by a statement that the authors made. The authors said that they halved their training costs by increasing batch size. This happens because larger batch sizes →fewer batches needed to fully load your dataset.
更大的批量大小意味着训练时对模型的更新更少。这导致较低的计算成本。但这并不是唯一有所作为的事情。在我对非凡报告“将 TensorFlow 扩展到每秒 3 亿次预测”的细分中,我对作者的声明感到惊讶。作者表示,他们通过增加批量大小将训练成本减半。发生这种情况是因为更大的批次大小 → 完全加载数据集所需的批次更少。
There’s a cost associated to moving batches from RAM/disk to GPU memory. Using larger batches = less moving around of your data = less training time. The trade off is that by using larger batches you start missing out on the advantages of stochastic gradient descent.
将批次从 RAM/磁盘移动到 GPU 内存会产生相关成本。使用更大的批次 = 更少的数据移动 = 更少的训练时间。权衡是,通过使用更大的批次,你开始错过随机梯度下降的优势。
-This is something a reader taught me. If you have any insights to share with me, please do comment/reach out. I’m always excited to learn from your experiences.
——这是一位读者教我的。如果您有任何见解要与我分享,请发表评论/联系我。我总是很高兴能从你的经历中学习。
This technique works in a variety of data types, including statistical, textual, and even image. This is a big advantage if you’re looking to build a multi-modal system since this one optimization can take care of multiple components.
该技术适用于多种数据类型,包括统计、文本甚至图像。如果您希望构建多模式系统,这是一个很大的优势,因为这种优化可以处理多个组件。
Here we show one can usually obtain the same learning curve on both training and test sets by instead increasing the batch size during training. This procedure is successful for stochastic gradient descent (SGD), SGD with momentum, Nesterov momentum, and Adam. It reaches equivalent test accuracies after the same number of training epochs, but with fewer parameter updates, leading to greater parallelism and shorter training times.
在这里,我们展示了通常可以通过在训练期间增加批量大小来在训练集和测试集上获得相同的学习曲线。此过程对于随机梯度下降 (SGD)、带动量的 SGD、Nesterov 动量和 Adam 是成功的。它在相同数量的训练时期后达到等效的测试精度,但参数更新较少,从而导致更大的并行性和更短的训练时间。- Don’t Decay the Learning Rate, Increase the Batch Size
- 不要降低学习率,增加批量大小
Now to address the elephant in the room- what about generalization and accuracy? It has been well-noted by AI Researchers that increasing batch size messes up your accuracy and generalization. There is even a well-known term for the lower generalization of large batch training- the generalization gap. About that- it’s a myth. It certainly does exist, if you increase the batch size and do nothing else. However, there are steps you can take to avoid this issue.
现在来解决房间里的大象——泛化和准确性怎么样? AI 研究人员已经注意到,增加批量大小会扰乱您的准确性和泛化能力。对于大批量训练的较低泛化能力,甚至还有一个众所周知的术语——泛化差距。关于那个-这是一个神话。它确实存在,如果你增加批量大小而不做任何其他事情。但是,您可以采取一些步骤来避免此问题。
If you just increase batch sizes w/o changing anything else, your model will get stuck in sharper minima. That is the reason behind the generalization gap This was shown by the paper On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima.
如果您只是增加批次大小而不更改任何其他内容,您的模型将陷入更尖锐的最小值。这就是泛化差距背后的原因 这在关于深度学习的大批量训练:泛化差距和夏普极小值的论文中有所体现。
The authors of the phenomenal paper Train longer, generalize better: closing the generalization gap in large batch training of neural networks propose a great alternative training regimen. They realized that the fewer updates needed by LB models acted as a double-edged sword, reducing performance while improving costs. However, by implementing “Ghost Batch Normalization” we can hit up some amazing results (also think of how cool you would sound if you told people that you implemented Ghost Batch Normalization).
现象级论文 Train longer, generalize better: closing the generalization gap in large batch training of neural networks 的作者提出了一个很好的替代训练方案。他们意识到 LB 模型所需的更新较少是一把双刃剑,在降低性能的同时提高了成本。然而,通过实施“Ghost Batch Normalization”,我们可以得到一些惊人的结果(想想如果你告诉人们你实施了 Ghost Batch Normalization,你听起来会多么酷)。
The random walk visualization is another reason you should consider evolution.
随机游走可视化是您应该考虑进化的另一个原因。
Similarly, for performance, you can maintain your accuracy by adjusting your learning rate and batch size proportionally. If you want more details on Batch Size and Model Performance, read this post.
同样,为了提高性能,您可以通过按比例调整学习率和批量大小来保持准确性。如果您想了解有关批量大小和模型性能的更多详细信息,请阅读这篇文章。
Notice both Batch Size and lr are increasing by 2 every time
注意 Batch Size 和 lr 每次都增加 2
Now moving on to another data related that I personally use quite a bit.
现在转到另一个我个人经常使用的相关数据。
Active Learning 主动学习
Active Learning is based on a simple concept. From the perspective of a Machine Learning Model, all data points are not created equal. Some points are easy to handle, while others require more finesse. If you have a lot of data, then chances are that there is a lot of overlap in data points. So you can discard a significant portion with no problems.
主动学习基于一个简单的概念。从机器学习模型的角度来看,并非所有数据点都是平等的。有些点很容易处理,而另一些则需要更多的技巧。如果你有很多数据,那么数据点很可能有很多重叠。因此,您可以毫无问题地丢弃很大一部分。
This adds another problem. How do we identify the data points which our model would benefit from? There are a few compelling ways. The one I’ve been experimenting with most recently has been using semi-supervised clustering to pick samples that are furthest from the centroids. This was inspired by the Meta AI publication Beyond neural scaling laws: beating power law scaling via data pruning. To those of you interested, I went over this publication in more detail here.
这又增加了一个问题。我们如何确定我们的模型将从中受益的数据点?有一些引人注目的方法。我最近一直在试验的是使用半监督聚类来挑选离质心最远的样本。这是受到 Meta AI 出版物 Beyond neural scaling laws: beating power law scaling via data pruning 的启发。对于那些感兴趣的人,我在这里更详细地阅读了这份出版物。
I’ve been talking about this idea (how you didn’t need tons of data) for a few years now.
几年来我一直在谈论这个想法(你为什么不需要大量数据)。
So far, I’ve had great results with it. However, that is far from the only thing I use. In my work, I rely on ensembles of probabilistic and standard models, randomness, and some adversarial training to build a data point filtering system. This might sound expensive, but each individual piece of this doesn’t have to be too extensive. And they can work very well, to reduce dataset size (and the amount of retraining we need). Below is a full description of the system.
到目前为止,我已经取得了很好的成绩。但是,这远不是我唯一使用的东西。在我的工作中,我依靠概率和标准模型、随机性和一些对抗性训练的集合来构建数据点过滤系统。这听起来可能很昂贵,但其中的每一部分都不必太广泛。它们可以很好地工作,以减少数据集的大小(以及我们需要的再训练量)。以下是系统的完整描述。
This was one of my comments on a discussion on a recent post of the phenomenal AI newsletter Ahead of AI.
这是我对 Ahead of AI 最近发表的一篇关于非凡的 AI 时事通讯的讨论的评论之一。
The paper referenced in that discussion is called When Deep Learners Change Their Mind: Learning Dynamics for Active Learning. It introduced Label Dispersion, a new metric for quantifying the neural network confidence on a prediction. To learn more about it, check out the video I made below. Fair warning, I’m much better at writing than I am at videos🥶🥶
该讨论中引用的论文名为“当深度学习者改变主意时:主动学习的学习动态”。它引入了 Label Dispersion,这是一种用于量化神经网络对预测的置信度的新指标。要了解更多信息,请查看我在下面制作的视频。公平警告,我写的比视频好得多🥶🥶
Now to move on to something that has shown a lot of promise with Large Language Models.
现在继续讨论大型语言模型已经显示出很多前景的东西。
Increasing the Number of Tokens 增加代币数量
With ChatGPT, Bard, and now Meta’s Llama all being language models it’s always good to cover ideas that can help you design more scalable language models. To do so, I will be quoting a very interesting publication, Training Compute-Optimal Large Language Models by the mad lads over at Deepmind. In their research, they were able to develop Chinchilla, a language model with ‘only’ 70 Billion Parameters. However, the performance of Chinchilla was on another level-
使用 ChatGPT、Bard 和现在的 Meta 的 Llama 都是语言模型,涵盖可以帮助您设计更具可扩展性的语言模型的想法总是好的。为此,我将引用一个非常有趣的出版物,由 Deepmind 的疯狂小伙子们训练计算优化大型语言模型。在他们的研究中,他们能够开发 Chinchilla,一种“仅”有 700 亿个参数的语言模型。然而,龙猫的表现却在另一个层面上——
Chinchilla uniformly and significantly outperforms Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), and Megatron-Turing NLG (530B) on a large range of downstream evaluation tasks.
Chinchilla 在大量下游评估任务上一致且显着优于 Gopher (280B)、GPT-3 (175B)、Jurassic-1 (178B) 和 Megatron-Turing NLG (530B)。
This is even more impressive when you consider that Chinchilla had the same computing budget as Gopher. How do they achieve this performance? They had one key insight- too much focus was put on the number of parameters in a model and factors like the number of tokens were overlooked.
当您考虑到 Chinchilla 的计算预算与 Gopher 相同时,这就更令人印象深刻了。他们是如何实现这种性能的?他们有一个关键的见解——过于关注模型中的参数数量,而忽略了令牌数量等因素。
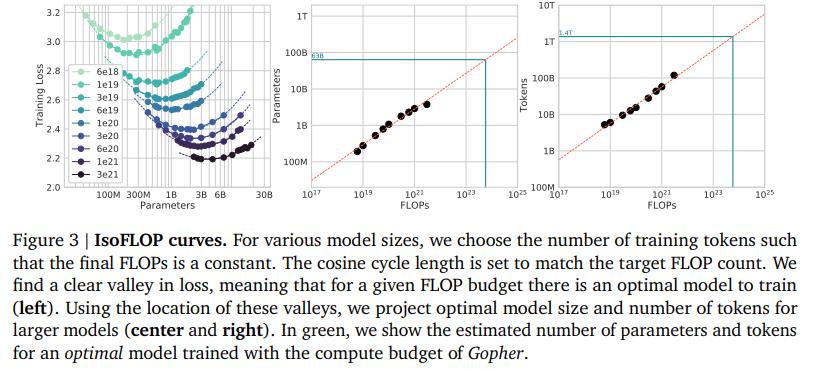
Given a computing budget, it makes sense to put scale up your training tokens and parameters in equal proportions. This leads to better performance, but also lower costs. Since we have a lower number of parameters, we will see a much lower inference cost when running the model. Don’t overlook this advantage. Amazon Web Services estimates that “In deep learning applications, inference accounts for up to 90% of total operational costs”.
给定计算预算,按相等比例扩展训练令牌和参数是有意义的。这会带来更好的性能,但也会降低成本。由于我们的参数数量较少,因此在运行模型时我们会看到更低的推理成本。不要忽视这个优势。 Amazon Web Services 估计“在深度学习应用程序中,推理占总运营成本的 90%”。
…for every doubling of model size the number of training tokens should also be doubled
……模型大小每增加一倍,训练标记的数量也应该增加一倍- Direct Quote from the paper.
- 直接引用论文。
To drill this point home, here is a table comparing the model size and tokens of Chinchilla with some other standards like LaMDA, Gopher, and GPT-3.
为了深入了解这一点,这里有一张表格,将 Chinchilla 的模型大小和令牌与 LaMDA、Gopher 和 GPT-3 等其他一些标准进行了比较。
Now we’re going to move one of the ideas that I’m personally most excited about going forward.
现在,我们将推进我个人最兴奋的想法之一。
Sparse Activation 稀疏激活
Think back to how Neural Networks work. When we train them, input flows through all the neurons, both in the forward and backward passes. This is why adding more parameters to a Neural Network adds to the cost exponentially.
回想一下神经网络是如何工作的。当我们训练它们时,输入流过所有神经元,包括前向和后向传递。这就是为什么向神经网络添加更多参数会成倍增加成本的原因。
Watch the Neural Networks series by 3Blue1Brown for a more thorough explanation.
观看 3Blue1Brown 的神经网络系列以获得更详尽的解释。
Adding more neurons to our network allows for our model to learn from more complex data (like data from multiple tasks and data from multiple senses). However, this adds a lot of computational overhead.
向我们的网络添加更多神经元允许我们的模型从更复杂的数据(例如来自多个任务的数据和来自多个感官的数据)中学习。然而,这增加了大量的计算开销。
Sparse Activation allows for a best-of-both-worlds scenario. Adding a lot of parameters allows our model to learn more tasks effectively (and make deeper connections). Sparse Activation lets you use only a portion of your network, cutting down your inference. This allows the network to learn and get good at multiple tasks, without being too costly.
稀疏激活允许两全其美的场景。添加大量参数可以让我们的模型有效地学习更多任务(并建立更深层次的联系)。稀疏激活让您只使用网络的一部分,从而减少推理。这允许网络学习并擅长多项任务,而不会花费太多。
Of the sparsity algorithms I’ve come across, my favorite has been Sparse Weight Activation Training (SWAT). It has had great results, the use of zombie neurons allows for more diverse networks than dropout or other sparsity algorithms, and it has great results.
在我遇到的稀疏算法中,我最喜欢的是稀疏权重激活训练 (SWAT)。它取得了很好的效果,僵尸神经元的使用允许比 dropout 或其他稀疏算法更多样化的网络,并且它取得了很好的效果。
For ResNet-50 on ImageNet SWAT reduces total floating-point operations (FLOPS) during training by 80% resulting in a 3.3× training speedup when run on a simulated sparse learning accelerator representative of emerging platforms while incurring only 1.63% reduction in validation accuracy. Moreover, SWAT reduces memory footprint during the backward pass by 23% to 50% for activations and 50% to 90% for weights.
对于 ImageNet 上的 ResNet-50,SWAT 将训练期间的总浮点运算 (FLOPS) 减少了 80%,从而在代表新兴平台的模拟稀疏学习加速器上运行时训练速度提高了 3.3 倍,而验证准确度仅降低了 1.63%。此外,SWAT 在向后传递过程中减少了 23% 到 50% 的激活内存占用和 50% 到 90% 的权重占用。
To learn more about this algorithm, watch this video. Now onto the final technique. This is a technique that Deep Learning Engineers in particular would really benefit from integrating into their work process.
要了解有关此算法的更多信息,请观看此视频。现在进入最后的技术。这是一种技术,特别是深度学习工程师可以从集成到他们的工作流程中真正受益。
Applying Filters and letting simple models do most of your tasks
应用过滤器并让简单的模型完成大部分任务
The best way to build and use huge models efficiently- don’t use them a lot. Instead let simple models/filters do most of your tasks, and use your large AI model only when it is absolutely needed. This is technically cheating, but worth mentioning. Too many Data Scientists and Machine Learning Engineers get caught up in trying to build the perfect model to accomplish the task. Even if it is achieved, this model is likely going to be extremely expensive, since it has to account for lots of edge cases. A better alternative is to sometimes give up on a task. Using fixed rules models/filters to handle these edge cases is a great alternative. I will illustrate this with a personal story.
高效构建和使用大型模型的最佳方式——不要经常使用它们。相反,让简单的模型/过滤器完成你的大部分任务,只有在绝对需要时才使用你的大型 AI 模型。这在技术上是作弊,但值得一提。太多的数据科学家和机器学习工程师忙于尝试构建完美的模型来完成任务。即使实现了,这个模型也可能非常昂贵,因为它必须考虑很多边缘情况。更好的选择是有时放弃一项任务。使用固定规则模型/过滤器来处理这些边缘情况是一个很好的选择。我将用一个个人故事来说明这一点。
Earlier on in my journey into Machine Learning, I was asked to help a team improve their information mining bot. The bot used Deep Learning to extract the key features from the text but was struggling to extract one key piece of information. Their performance was around 68%. The bot had hit a wall, and they weren’t sure how to proceed. So they got me on.
在我进入机器学习之旅的早期,我被要求帮助一个团队改进他们的信息挖掘机器人。该机器人使用深度学习从文本中提取关键特征,但难以提取一条关键信息。他们的表现约为68%。机器人碰壁了,他们不确定如何继续。所以他们让我上了。
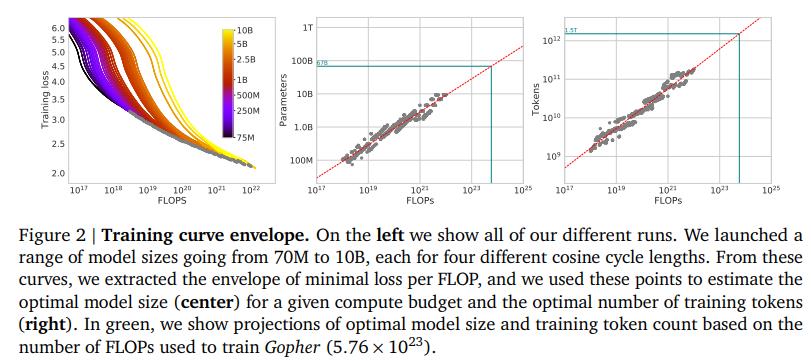
Even when Chinchilla was ‘compute optimal’, it still needed a lot of FLOPs. Keep that in mind. Often efficient or small language models, are only small relative to the monstrously big models like GPT-3.
即使 Chinchilla 是“计算最优”的,它仍然需要大量的 FLOP。记住这一点。通常是高效或小型语言模型,相对于像 GPT-3 这样的巨大模型来说只是小的。
I threw the kitchen sink of Machine Learning techniques at it. The better models were out of budget (the bot was called a lot) and the smaller models got tripped up. In the end, I gave up and presented a regex for it. The regex handled the normal cases perfectly and failed with all the weird exceptions. So we were dealing with a performance of 77%. I expected the people to be disappointed since my solution did not use Machine Learning (I had been hired as a Machine Learning Engineer).
我把机器学习技术的厨房水槽扔给了它。更好的模型超出了预算(机器人被调用了很多),而较小的模型被绊倒了。最后,我放弃了并为它提供了一个正则表达式。正则表达式完美地处理了正常情况,并因所有奇怪的异常而失败。所以我们处理的是 77% 的性能。我希望人们会失望,因为我的解决方案没有使用机器学习(我被聘为机器学习工程师)。
Instead, the clients who hired me were excited. They liked the performance and low computational costs. This helped me realize one thing- no one really cared how I solved the problem, they cared that it was solved well. This opened up my mind. In the end, I used Regex systems to handle the general cases (+a few of the edge cases). I layered this with the more costly model if these filters did not work. The end result- 89% performance with lower average computational costs than the original system.
相反,雇用我的客户很兴奋。他们喜欢性能和低计算成本。这帮助我意识到一件事——没有人真正关心我是如何解决问题的,他们关心的是问题解决得好。这打开了我的思路。最后,我使用 Regex 系统来处理一般情况(+一些边缘情况)。如果这些过滤器不起作用,我将其与成本更高的模型分层。最终结果 - 89% 的性能和比原始系统更低的平均计算成本。
Photo by Erik Mclean on Unsplash
Erik Mclean 在 Unsplash 上拍摄的照片
If you’re building powerful models, it is prudent to reserve their use to when needed. Most problems can be reasonably solved with simpler techniques. Reducing the number of times you have to use your juggernaut is generally easier than making your juggernaut more efficient.
如果您正在构建强大的模型,谨慎的做法是将它们保留到需要的时候使用。大多数问题都可以用更简单的技术合理地解决。减少你必须使用你的主宰的次数通常比让你的主宰更有效率更容易。
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people.
这就是这件作品。我感谢你的时间。与往常一样,如果您有兴趣与我合作或查看我的其他作品,链接将位于此电子邮件/帖子的末尾。如果您喜欢我的作品,我将非常感谢您的匿名推荐。你可以把它丢在这里。如果您发现这篇文章有价值,我将很感激您与更多人分享。
For those of you interested in taking your skills to the next level, keep reading. I have something that you will love.
对于那些有兴趣将自己的技能提升到一个新水平的人,请继续阅读。我有一些你会喜欢的东西。
Upgrade your tech career with my newsletter ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!
通过我的时事通讯“Tech Made Simple”提升您的技术职业生涯!凭借专家见解、技巧和资源,在 AI、软件工程和技术行业保持领先地位。单击此链接,新订阅者可享受 20% 的折扣。立即订阅并简化您的技术之旅!

以上是关于如何高效地构建像 ChatGPT 这样的大型 AI 模型?的主要内容,如果未能解决你的问题,请参考以下文章