高性能mysql 第5章 创建高可用的索引
Posted 张小贱1987
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高性能mysql 第5章 创建高可用的索引相关的知识,希望对你有一定的参考价值。
b-tree索引
一定程度上说,mysql只有b-tree索引。他没有bitmap索引。还有一个叫hash索引的,只在Memory存储引擎中才有。
b-tree索引跟oracle中的大同小异。
mysql中关于b-tree的限制:
只有做全值拼配或者根据左前缀匹配。我猜测是因为mysql没有基于cost的优化器,它没有对index full scan的操作。因为无法衡量这种full scan是否划得来。所以只能对前缀进行匹配,没有后缀或者中间匹配这种逻辑。
多列索引
如果是多列索引,顺序很重要,如果没有从索引的第一列开始查询,那么将不会使用索引。
比如索引建立在A,B,C列上。
- 如果对B= ? and C = ? 无法使用索引
- 如果对 A = ? and C = ? 只能A =?生效 使用索引。
始终将索引的列放在查询的一边,如A + 1 = 2,这种情况不会使用索引,应该是写A = 1。(可能是因为mysql处理的时候,A + 1 是作为隐藏的函数来处理的)。A如果作为函数的参数,也无法使用索引。
前缀索引:
前缀索引用在大字段上或者长度比较尝的字符串上,使用字符串的前缀作为索引。传入一个参数,代表截取的长度。
语法:
结果:

使用了索引。
前缀索引的缺陷:因为只存储了前缀,所以无法作为数据来操作,如order by和group by的部分,无法使用这个索引来优化。
聚簇索引:
聚簇索引是一种数据的存储方式,不是一种具体的索引类型。
innodb默认使用聚簇索引来存放数据。
在聚簇索引中,innodb将使用主键索引(没有定义主键的,会自动生成隐藏的主键来实现聚簇索引),将数据直接挂在b-tree索引的叶子结点上。也就是说,数据并不是按照插入顺序存放在一个固定的磁盘区域里的,而是按照主键的顺序分散在b-tree上的。
其他的索引,如果把他们思考为一个key-value的格式的话,oracle的value存储的是数据的物理地址,而innodb存储的是主键。
聚簇索引的优点:
- 很显然,根据索引查询数据的速度会变快。
聚簇索引的缺点:
- 全表扫描变慢。
- 插入速度受到影响。特别是大批量的插入,速度肯定不是上顺序存储的结构。
- 更新的时候,如果更新的是主键列,那么速度回大大受到影响。不过这种需求基本不会有的。
- 二级索引(非主键索引,都要经过两次才能找到数据,第一次找主键,第二次找数据)会变的庞大。
作者在这个章节又提到,使用自增数字作为主键,因为这种主键是顺序的,不会影响插入性能。作者还做了实验,使用自增数字作为主键的插入速度是使用uuid的2-3倍(大数据量下)。
但是使用自增索引,并发插入的情况下,性能会很慢吧。
覆盖索引:
如果一个索引包含了所需要查询的所有字段。我么就叫覆盖索引。
覆盖索引能大大的提升性能。
其他:
mysql不能再索引中使用like操作。这是底层存储引擎API限制。现在的API只有等于 大小 小于这种比较操作。
排序中使用索引:
mysql排序可以使用索引,但是前提是排序的顺序要和索引的顺序一致。
限制,只能满足如下条件才能使用索引:
- 索引的列顺序和order by字句的顺序完全一致(或者跟前面部分一致)
- 并且所有列的排序方向(正序倒序)都一样(注意这里是order by中所有列一样 如都是asc或者desc)。
- 如果有多张表关联,那么order by的所有列都在第一章表上的时候才能使用索引。
假如多列索引是(rental_date、inventory_id、customer_id)以下是列子是没有问题的:
1).............where rental_date = \'2005-05-25\' order by inventory_id desc;
2)..............where rental_date > \'2005-05-25\' order by rental_date,inventory_id;
以下几个列子是不能使用索引进行排序的查询:
1).........where rental_date = \'2005-05-25\' order by inventory_id desc,customer_id asc;
原因:使用了两种不同的排序方向
2).........where rental_date = \'2005-05-25\' order by inventory_id,staff_id;
原因:此处引用了一个不在索引中的列staff_id
3).........where rental_date = \'2005-05-25\'order by customer_id;
原因:不能形成最左前缀
4)........where rental_date > \'2005-05-25\' order by inentroy_id,custmoer_id;
原因:这个在第一列上有范围条件,不能形成等于条件,因此不能形成最左前缀原则
5)........where rental_date = \'2005-05-25\' and inventory_id in(1,2) order by customer_id;
原因:在inventory_id上定义了多个等于条件
重复索引
MySQL允许在相同列上创建多个索引,无论是有意的还是无意的。MySQL需要单独维护重复的索引,并且优化器在优化查询的时候也需要逐个地进行考虑,这会影响性能。
重复索引:是指在相同的列上按照相同的顺序创建的相同类型的索引。应该避免这样创建重复索引,发现后也应该立即移除。
上面的操作相当于建了三个重复的索引。
ps:网上有专门的工具来检测重复索引。
冗余索引
冗余索引和重复索引有一些不同,如果创建了索引(A,B),再创建索引(A)就是冗余索引,因为这只是前一个索引的前缀索引。因此索引(A,B)也可以当索引(A)来使用(这种冗余只是对B-Tree索引来说)。冗余索引通常发生在为表添加新索引的时候。例如,有人可能会增加一个新的索引(A,B)而不是扩展已有的索引(A)。还有一种情况是将一个索引扩展为(A,ID),其中ID是主键,对于InnoDB来说主键列已经包含在二级索引中了,索引也是冗余的。
大多数的情况下都不需要冗余索引,应该尽量扩展已有的索引而不是创建新索引。但也有时候出于性能方面的考虑需要冗余索引,因为扩展已有的索引会导致其变得太大,从而影响其它使用该索引的查询的性能。
eg:如果在整数列上有一个索引,现在需要额外增加一个很长的VARCHAR列来扩展该索引,那性能可能会急剧下降。
范围查询:
如果执行计划中的type是range,那么代表是范围查询。
举例如下(其实age用 tinyint unsign就够了,但是建的不合理):
-
name varchar(40),
-
age MEDIUMINT
-
)
-
查看各种sql的执行计划,注意type和key_len列。
这个肯定会走索引,key_len是4,那么就只用到了索引中age的部分:
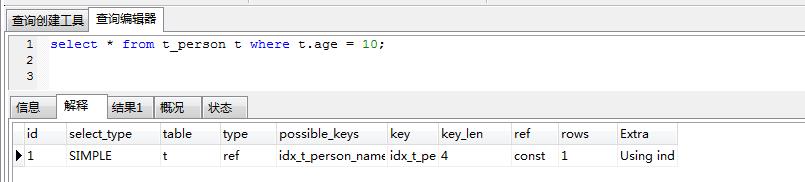
这个也走索引,就跟作者说的不一样了,应该是5.6的改进。注意key_len是4是47,代表使用了复合索引的全部两列。

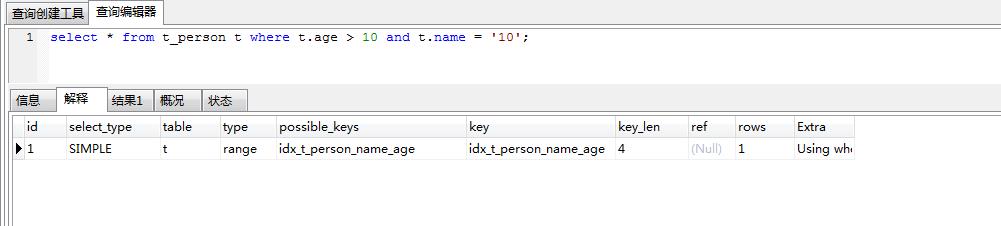
这个type是range,但是key_len是47,代表虽然是范围查询,因为使用的是in,还是用到了索引的全部两列的。

这个type是range,但是key_len是4,代表虽然是范围查询,因为使用的是>,还是只用到索引使用>的那一列。
mysql的统计信息
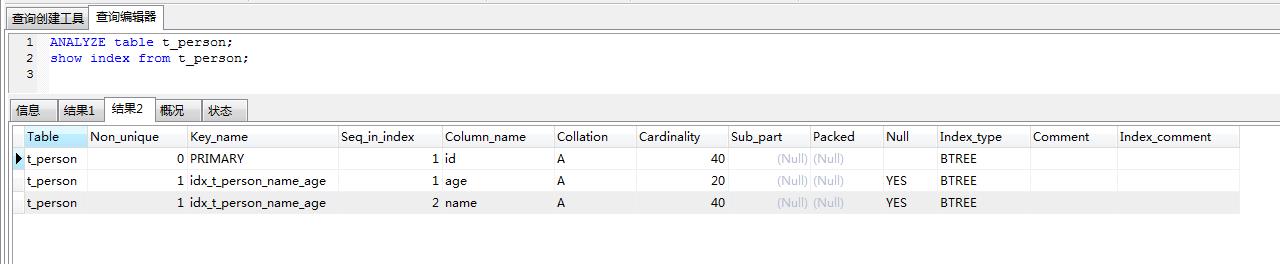
mysql服务层通过两个api了解存储引擎的索引值分布信息,以决定如何使用索引。第一个是records_in_range(),通过向存储引擎传入两个边界值来获取这个范围内大概有多少个数据,对于MyISAM,这个接口返回精确值,对于innodb,这个接口返回估计值。第二个是info()方法,返回各种各类型的数据,包括键值的基数cardinality(每个键值有多少个记录)。可以通过show index from命令查看索引的基数。
关于索引基数,一下来自网络:
基数是数据列所包含的不同值的数量。例如,某个数据列包含值1、3、7、4、7、3,那么它的基数就是4。索引的基数相对于数据表行数较高(也就是说,列中包含很多不同的值,重复的值很少)的时候,它的工作效果最好。如果某数据列含有很多不同的年龄,索引会很快地分辨数据行。如果某个数据列用于记录性别(只有"M"和"F"两种值),那么索引的用处就不大。如果值出现的几率几乎相等,那么无论搜索哪个值都可能得到一半的数据行。在这些情况下,最好根本不要使用索引,因为查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。惯用的百分比界线是"30%"。
所以说,同样一个查询语句,传入的参数不同,可能mysql会采用不同的执行计划,这就是说,mysql部分功能是基于cost的优化器的。
这样的功能是根据表的统计信息来试下的,innodb的统计信息是根据取样来计算估计值的,可以通过analyze table 命令来更新一个表的统计信息。
执行计划中:
mysql5.7中type的类型达到了14种之多,这里只记录和理解最重要且经常遇见的六种类型,它们分别是all,index,range,ref,eq_ref,const。从左到右,它们的效率依次是增强的。
作者:理解索引是怎么工作的非常重要,根据这些理解来创建合适的索引。而不是根据"在多列索引中将选择性高的列放在第一列"或者"应该为where语句中的所有列创建索引"这种经验法则。
我的理解:作者说的还是合理的,上面说的第二个经验法是无稽之谈,第一个有部分是合理的,因为事实上要比这个复杂的多,你的where语句有可能不是=,是>这种,或者你的order by排序的列的顺序不是这样的,或者你想使用覆盖索引来提升性能,都可能影响你的索引创建规则。
以上是关于高性能mysql 第5章 创建高可用的索引的主要内容,如果未能解决你的问题,请参考以下文章
分库分表:超清-MyCAT+MySQL 搭建高可用企业级数据库集群
MyCAT+MySQL 搭建高可用企业级数据库集群——第1章 课程介绍
MyCAT+MySQL 搭建高可用企业级数据库集群——第2章 MyCat入门