SQL SERVER的统计信息
Posted 赵哲丽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL SERVER的统计信息相关的知识,希望对你有一定的参考价值。
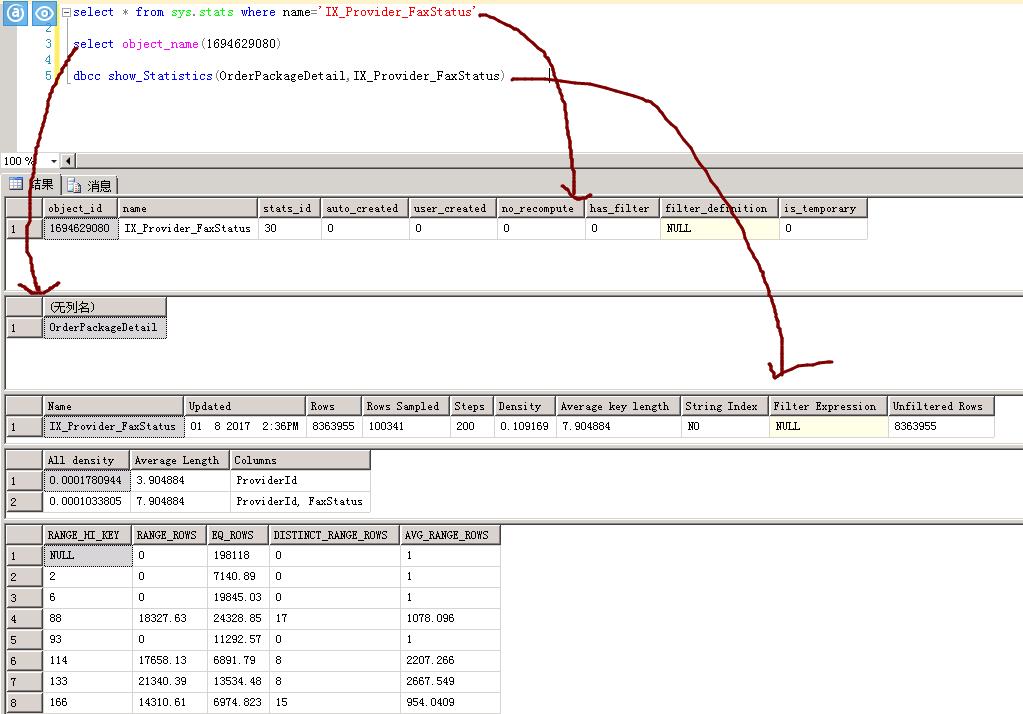
可以看到,统计信息分为三部分内容,头信息,数据字段选择性及直方图。
2.1 头信息
| 列名 | 说明 |
| Name | 统计信息的名称。 |
| Updated | 上次更新统计信息的日期何时间 |
| Rows | 预估表中的行数,不一定是精确的 |
| Rows Sampled | 统计信息的抽样行数,如果小于Rows,则说明直方图和密度结果是更加抽样行估计的 |
| Steps | 直方图中的梯级数。 Number of steps in the histogram. 每个梯级都跨越一个列值范围,后跟上限列值。 直方图梯级是根据统计信息中的第一个键列定义的。 最大梯级数为 200。 |
| Density | 计算公式为 1/统计信息对象第一个键列中的所有值(不包括直方图边界值)的非重复值。 查询优化器不使用此 Density 值,显示此值的目的是为了与 SQL Server 2008 之前的版本实现向后兼容。 |
| Average key length | 统计信息对象中所有键列的每个值的平均字节数。 |
| String Index | Yes 指示统计信息对象包含字符串摘要统计信息,以改进对使用 LIKE 运算符的查询谓词的基数估计;例如 WHERE ProductName LIKE \'%Bike\'。 Yes indicates the statistics object contains string summary statistics to improve the cardinality estimates for query predicates that use the LIKE operator; for example, WHERE ProductName LIKE \'%Bike\'. 字符串摘要统计信息与直方图分开存储,并当它是类型的统计信息对象第一个键列上创建char, varchar, nchar, nvarchar, varchar (max), nvarchar (max),文本,或ntext。 |
| Filter Expression | 包含在统计信息对象中的表行子集的谓词。 NULL = 未筛选的统计信息。 有关筛选的谓词的详细信息,请参阅Create Filtered Indexes。 有关筛选的统计信息的详细信息,请参阅统计信息。 |
| Unfiltered Rows | 应用筛选表达式前表中的总行数。 如果筛选表达式为 NULL,则 Unfiltered Rows 等于 Rows。 |
2.2 数据字段选择性
| 列名 | Description |
| Density | 密度为 1/非重复值。 结果显示统计信息对象中各列的每个前缀的密度,每个密度显示一行。 非重复值是每个行前缀和列前缀的列值的非重复列表。 例如,如果统计信息对象包含键列 (A, B, C),结果将报告以下每个列前缀中非重复值列表的密度:(A)、(A,B) 以及 (A, B, C)。 使用前缀 (A, B, C),以下每个列表都是一个非重复值列表:(3, 5, 6)、(4, 4, 6)、(4, 5, 6) 和 (4, 5, 7)。 使用前缀 (A, B),相同列值则具有以下非重复值列表:(3, 5)、(4, 4) 和 (4, 5) |
| Average Length | 存储列前缀的列值列表的平均长度(以字节为单位)。 例如,如果列表 (3, 5, 6) 中的每个值都需要 4 个字节,则长度为 12 个字节。 |
| columns | 为其显示 All density 和 Average length 的前缀中的列的名称。 |
2.3 直方图
| 列名 | Description |
|---|---|
| RANGE_HI_KEY | 直方图梯级的上限列值。 列值也称为键值。 |
| RANGE_ROWS | 其列值位于直方图梯级内(不包括上限)的行的估算数目。 |
| EQ_ROWS | 其列值等于直方图梯级的上限的行的估算数目。 |
| DISTINCT_RANGE_ROWS | 非重复列值位于直方图梯级内(不包括上限)的行的估算数目。 |
| AVG_RANGE_ROWS | 重复列值位于直 方图梯级内(不包括上限)的平均行数(如果 DISTINCT_RANGE_ROWS > 0,则为 RANGE_ROWS / DISTINCT_RANGE_ROWS)。 |
直方图,用于计算数据中每个非重复值出现的频率。使用统计信息对象的第一个键列中的列值来计算直方图,可以通过抽样行或者全表扫描的形式。如果是抽样创建,那么,这里边的 存储总行数何非重复值总数则为估计值。
创建直方图的时候,查询优化器对列值进行排序,同时计算每个非重复列值匹配的个数,然后将这列非重复列值 分为 1-200个连续的直方图梯级中,每个梯级包含一个列值范围,该范围介于两个边界值之间的所有可能列值,不包含边界值本身,最小的排序列值是第一个直方图梯级的上限值。
3 影响统计信息的选项
每个表格或者索引视图 何时创建统计信息、基于哪些列创建统计信息及何时更新统计信息,需要根据 AUTO_CREATE_STATISTICS 、 AUTO_UPDATE_STATISTICS、 AUTO_UPDATE_STATISTICS_ASYNC 的设定值 来确定,这三个属于 数据库级别的选项,可以通过系统视图查看,也可以通过 图形界面选择数据库的“属性”,查看“选项”。

1 --查看数据库统计信息选项设定值 2 SELECT 3 name dbname, 4 is_auto_create_stats_on, 5 is_auto_update_stats_on, 6 is_auto_update_stats_async_on 7 FROM sys.databases
3.1 AUTO_CREATE_STATISTICS
默认为ON。自动创建统计信息选项,仅应用于 表格单列统计信息!!!
查询优化器根据查询谓词的使用情况,在表格上单独给某一列创建统计信息(这些单列暂时未创建直方图),协助查询计划的基数估计。
该选项不决定是否为索引创建统计信息,也不生产筛选统计信息。
通过该选项创建的统计信息,名称以 _WA 开头。可以通过sys.stats视图查看。
1 SELECT OBJECT_NAME(s.object_id) AS object_name, 2 COL_NAME(sc.object_id, sc.column_id) AS column_name, 3 s.name AS statistics_name 4 FROM sys.stats AS s JOIN sys.stats_columns AS sc 5 ON s.stats_id = sc.stats_id AND s.object_id = sc.object_id 6 WHERE s.name like \'_WA%\' 7 ORDER BY s.name;
3.2 AUTO_UPDATE_STATISTICS
默认为ON。自动更新统计信息选项,查询优化器自动确定统计信息何时过期何时需要更新。
通常情况,从上次自动更新至今,如果期间积累了较大数量的数据变更,包括插入、删除及修改,或表结构变更等,均会造成统计信息过期。
该选项适用于为索引创建统计信息对象、查询谓词中的单列以及使用 create statistics 语句创建的统计信息。
3.3 AUTO_UPDATE_STATISTICS_ASYNC
默认为OFF。异步自动更新统计信息选项,确定查询优化器是使用 同步统计信息更新还是异步统计信息更新。OFF则代表使用同步自动更新统计信息,这样,查询计划始终使用最新的统计信息进行编译执行,如果遇到统计信息过期,则会在查询编译前等待更新统计信息,若是异步自动更新统计信息,则在遇到统计信息过期时,直接使用现有统计信息编译然后执行,即使可能由于统计信息过期造成编译不佳,执行计划非最优,但仍按照编译结果运行。
该选项使用于适用于 为索引创建的统计信息对象、查询谓词中的单列以及使用 CREATE STATISTICS 语句创建的统计信息。
通常情况下,使用 同步自动更新统计信息,则设置该选项为OFF,而在以下两种情况下,则可开启为ON(来自官网):
- 应用程序贫富执行相同查询或者类似查询,与同步统计信息更新相比,使用异步统计信息更新查询的响应时间可以不受影响,避免出现等待最新统计信息的情况;
- 应用程序遇到了客户端请求超时,这些超时是由于一个或多个查询正在等待更新后的统计信息所导致的。 在某些情况下,等待同步统计信息可能会导致应用程序因过长超时而失败。
4 何时创建与更新
4.1 创建
- 查询优化器自动创建
- 创建索引时,查询优化器自动为表格或者视图上的索引创建统计信息
-
- 在 AUTO_CREATE_STATISTICS 为 ON 时,查询优化器为查询谓词中的单列创建统计信息
- 手动执行创建
- CREATE STATISTICS 创建
常规情况下,查询优化器创建的统计信息就可以满足我们的大多数需求,但是如果出现以下情况,可以考虑手动创建:
- 数据库引擎优化顾问建议创建
- 查询谓词包含尚不位于相同索引中的多个相关列
- 查询从数据的子集中选择数据
- 查询缺少统计信息
4.2 更新
统计信息定义在普通的表格上,当发生以下任一变化时,统计信息就会被认为是过时的,下次使用到的时候,会自动触发更新动作:
- - 表格从没有数据变成大于等于1条数据;
- - 对于数据量小于500行的表格,当统计信息的第一个字段数据累计变化量大于500以后;
- - 对于数据量大于500行的表格,当统计信息的第一个字段数据累计变化量大于500+(20%*表格数据总量)以后。
这三种情况下,第三种情况最容易出现更新不及时的情况,比如一张100万的表格,它最近一个月的数据增长是15万左右,由于小于20%,统计信息没有更新,这就导致了有关最近一个月数据sql执行有不是很正确的信息提供,那么就需要定期去检查并及时更新统计信息!
临时表上可以有统计信息,其维护策略基本和普通表格一样,但是表变量上不能建立统计信息。
1 --更新指定统计信息 2 UPDATE STATISTICS Sales.SalesOrderDetail AK_SalesOrderDetail_rowguid; 3 GO 4 5 --更新表格上的所有统计信息 6 UPDATE STATISTICS Sales.SalesOrderDetail; 7 GO 8 9 --更新整个数据库上的所有统计信息 10 EXEC sp_updatestats; 11 12 --删除统计信息 13 DROP STATISTICS Purchasing.Vendor.VendorCredit, Sales.SalesOrderHeader.CustomerTotal; 14 GO 15 16 --查看统计信息上一次更新时间 17 18 SELECT 19 OBJECT_NAME(OBJECT_ID) 20 FROM sys.stats 21 WHERE STATS_DATE(object_id, stats_id) is not null
以上是关于SQL SERVER的统计信息的主要内容,如果未能解决你的问题,请参考以下文章