Sklearn标准化和归一化方法汇总:标准化 / 标准差归一化 / Z-Score归一化
Posted Laurence Geng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sklearn标准化和归一化方法汇总:标准化 / 标准差归一化 / Z-Score归一化相关的知识,希望对你有一定的参考价值。
Sklearn中与特征缩放有关的五个函数和类,全部位于sklearn.preprocessing包内。作为一个系列文章,我们将逐一讲解Sklearn中提供的标准化和归一化方法,以下是本系列已发布的文章列表:
- Sklearn标准化和归一化方法汇总(1):标准化 / 标准差归一化 / Z-Score归一化
- Sklearn标准化和归一化方法汇总(2):Min-Max归一化
- Sklearn标准化和归一化方法汇总(3):范数归一化
以下是Sklearn中的五种与特征缩放相关的函数和类,我们的研究也是为围绕这些函数和类展开的:
| 名称 | 方法名 | 类名 |
|---|---|---|
| 标准化 / Z-Score 归一化 / 标准差归一化 | sklearn.preprocessing.scale | sklearn.preprocessing.StandardScaler |
| Min-Max 归一化 | sklearn.preprocessing.minmax_scale | sklearn.preprocessing.MinMaxScaler |
| 范数归一化 | sklearn.preprocessing.normalize | sklearn.preprocessing.Normalizer |
| Robust Scaler(无常用别名) | sklearn.preprocessing.robust_scale | sklearn.preprocessing.RobustScaler |
| Power Transformer (无常用别名) | sklearn.preprocessing.power_transform | sklearn.preprocessing.PowerTransformer |
关于各种关于标准化和归一化的概念和分类,我们已经在此前一篇文章《标准化和归一化概念澄清与梳理》中做了详细的梳理和澄清,不清楚的读者可以先阅读一下此文。本文我们研究第一种归一化手段:标准化 / 标准差归一化 / Z-Score归一化。本文地址:https://laurence.blog.csdn.net/article/details/128713962,转载请注明出处!
1. 算法
标准化 / 标准差归一化 / Z-Score归一化的算法是:先求出数据集(通常是一列数据)的均值和标准差,然后所有元素先减去均值,再除以标准差,结果就是归一化后的数据了。经标准差归一化后,数据集整体将会平移到以0点中心的位置上,同时会被缩放到标准差为1的区间内。要注意的是数据集的标准差变为1,并不意味着所有的数据都会被缩放到[-1,1]之间,下文有示例为证。其计算公式如下(其中 μ \\mu μ是均值, σ \\sigma σ是标准差):
x ′ = x − μ σ x^'=\\fracx - \\mu\\sigma x′=σx−μ
2. 示例
在下面的示例中,我们准备了一组身高数据,这组数据符合以170为均值,170*0.15为标准差的正态分布。我们会通过三种方法计算出标准差归一化后的数据,从中我们可以理解标准差归一化的计算逻辑并掌握直接进行标准差归一的工具方法和类,以下是示例将要演示的3种计算方法:
- 根据公式手动计算
- 使用
sklearn.preprocessing.scale直接处理 - 使用
sklearn.preprocessing.StandardScaler直接处理
以下是示例代码:
# 标准差归一化 / Z-Score归一化 / 标准化
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import scale
from sklearn.preprocessing import StandardScaler
# author: https://laurence.blog.csdn.net/
%matplotlib inline
np.random.seed(42)
fig, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=(12,5))
heights = np.random.normal(loc=170, scale=170*0.15, size=1000)
print("1. 原始数据")
print(f"heights (first 3 elements) = heights[:3]")
print(f"heights mean = heights.mean()")
print(f"heights standard deviation = heights.std()")
ax1.hist(heights, bins=50)
ax1.set_title("raw data")
ax1.annotate(f"σ = heights.std()", (0.5, 0.95), xycoords='axes fraction', va='center', ha='center')
print("--------------------------------------------------------------------------------------------------------------")
print("2. 根据公式手动进行标准差归一化(标准化)")
std_scaled_heights = (heights - heights.mean()) / heights.std()
print(f"std_scaled_heights (first 3 elements) = std_scaled_heights[:3]")
print(f"std_scaled_heights standard deviation = std_scaled_heights.std()")
ax2.hist(std_scaled_heights, bins=50)
ax2.set_title("manually scaled")
ax2.annotate(f"σ = std_scaled_heights.std()", (0.5, 0.95), xycoords='axes fraction', va='center', ha='center')
print("--------------------------------------------------------------------------------------------------------------")
print("3. 使用scale函数进行标准差归一化(标准化)")
std_scaled_heights = scale(heights)
print(f"std_scaled_heights (first 3 elements) = std_scaled_heights[:3]")
print(f"std_scaled_heights standard deviation = std_scaled_heights.std()")
ax3.hist(std_scaled_heights, bins=50)
ax3.set_title("scale()")
ax3.annotate(f"σ = std_scaled_heights.std()", (0.5, 0.95), xycoords='axes fraction', va='center', ha='center')
print("--------------------------------------------------------------------------------------------------------------")
print("4. 使用StandardScaler函数进行标准差归一化(标准化)")
# 在交付给Scaler前,需将一维数据转置为二维单列数组,以便适配Scaler接受的二维数组结构和轴向,即:按列进行缩放(axis=0)
# 受上层Transformer接口的约束,所有Scaler均不接受axis参数,默认按列计算,如要不想或不便转换,可以使用scale(axis=)函数进行缩放
heights = heights.reshape(-1,1)
std_scaled_heights = StandardScaler().fit_transform(heights)
print(f"std_scaled_heights (first 3 elements) = std_scaled_heights[:3].tolist()")
print(f"std_scaled_heights standard deviation = std_scaled_heights.std()")
ax4.hist(std_scaled_heights, bins=50)
ax4.set_title("StandardScaler")
ax4.annotate(f"σ = std_scaled_heights.std()", (0.5, 0.95), xycoords='axes fraction', va='center', ha='center')
plt.show()
输出数据:
1. 原始数据
heights (first 3 elements) = [182.6662109 166.47426032 186.51605772]
heights mean = 170.49296742346928
heights standard deviation = 24.957518297557534
--------------------------------------------------------------------------------------------------------------
2. 根据公式手动进行标准差归一化(标准化)
std_scaled_heights (first 3 elements) = [ 0.48775857 -0.1610219 0.64201457]
std_scaled_heights standard deviation = 1.0
--------------------------------------------------------------------------------------------------------------
3. 使用scale函数进行标准差归一化(标准化)
std_scaled_heights (first 3 elements) = [ 0.48775857 -0.1610219 0.64201457]
std_scaled_heights standard deviation = 1.0
--------------------------------------------------------------------------------------------------------------
4. 使用StandardScaler函数进行标准差归一化(标准化)
std_scaled_heights (first 3 elements) = [[0.48775857171297676], [-0.16102190351705692], [0.6420145667955481]]
std_scaled_heights standard deviation = 1.0
输出图表:
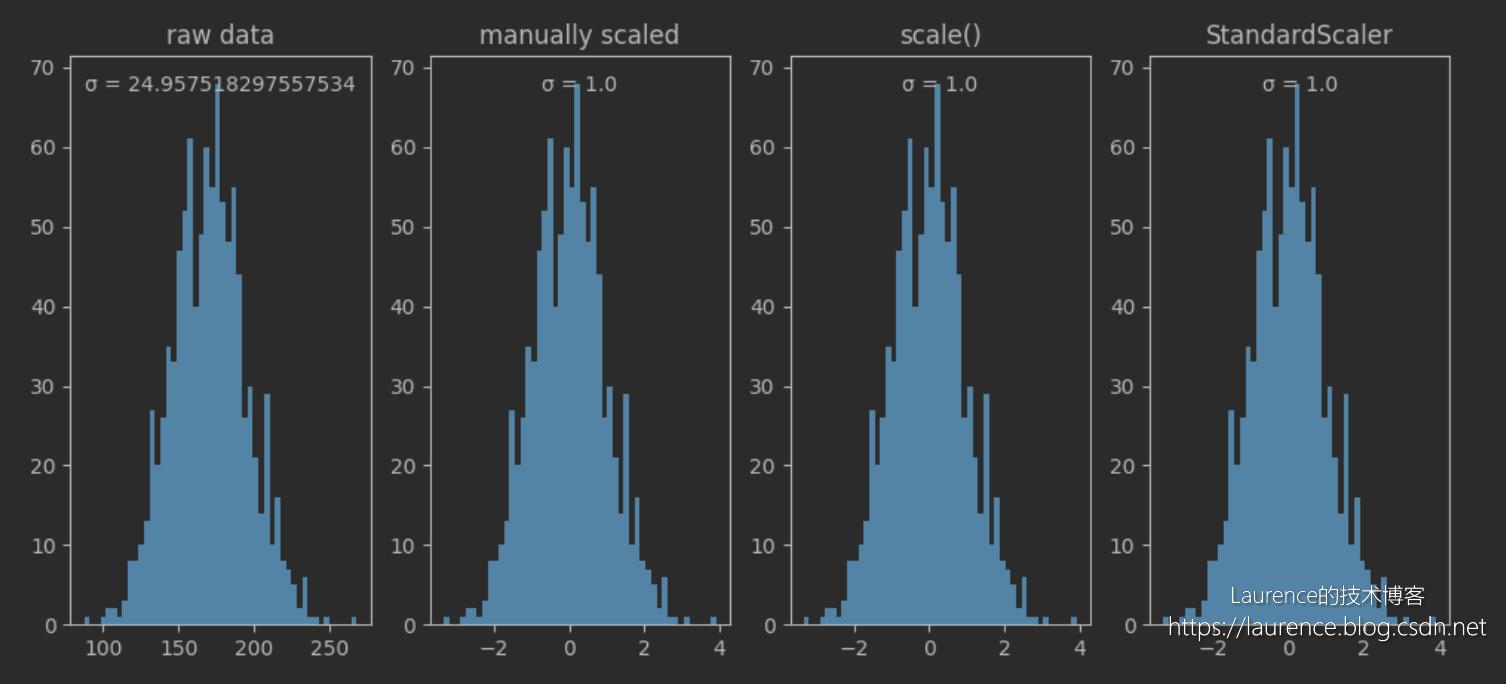
3. 解读
从输出的直方图可以看到:经过标准差归一化后,数据集被平移到了0点为中心的位置上,数据的方差从原来的24.96归置为1,数据分布(直方图形状)不变。关于标准差归一化提醒两个容易无解的地方:
- 经标准差归一化处理后,数据集的总体标准差变为1,而不是所有数据都会被收缩到[-1,1]之间,上图即是一个证明
- 标准差归一化处理不会改变数据分布,这一点很多文章的说法都是错误的,如果原来的数据就不符合正态分布,缩放后的数据依然不会符合(当然,严格的说均值和标准差改变的话,分布也会变,但是分布类型是不会被改变的,原来是什么类型,缩放后还是什么类型)
最后,提醒一下StandardScaler的使用方法:sklearn.preprocessing包内的Scaler类均不接受一维数组,在将一维数组传给Scaler前,需将其转置为(只有一列的)二维数组;此外,受上层Transformer接口的约束,所有Scaler均不接受axis参数,默认按列计算,如要不想或不便转换,可以使用对应函数进行按行缩放(此类场景并不常见),对应函数有axis参数。
以上是关于Sklearn标准化和归一化方法汇总:标准化 / 标准差归一化 / Z-Score归一化的主要内容,如果未能解决你的问题,请参考以下文章
Sklearn标准化和归一化方法汇总:标准化 / 标准差归一化 / Z-Score归一化