手把手教你用Unet实现语义分割(Pytorch版)
Posted 只道寻常zero
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手教你用Unet实现语义分割(Pytorch版)相关的知识,希望对你有一定的参考价值。
代码来源:https://github.com/milesial/Pytorch-UNet
1.搭建环境
开始搭建环境之前一定要仔细阅读readme
我选择的是Without Docker,那么我将遵循以下要求来配置环境:

安装CUDA
官网 : https://developer.nvidia.com/cuda-toolkit-archive
可以通过指令nvidia-smi查看自己的电脑能够支持的CUDA的最高版本
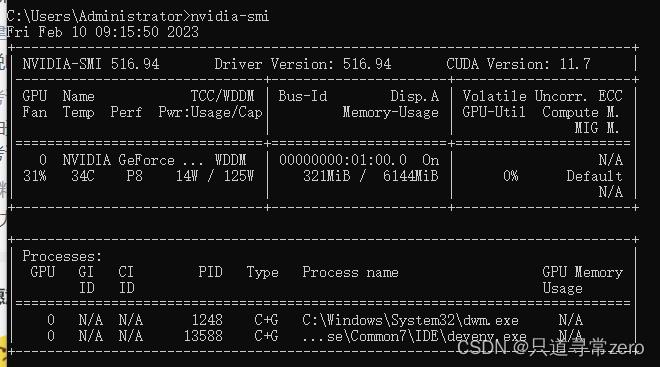
可以看到我的电脑最高支持的CUDA版本是11.7,然后就到官网上选择低于这个版本的CUDA下载就可以啦,我第一次选择的是10.2,但是在安装的时候遇到了问题,因此最终选择了11.3的版本,原因在之后会提到,建议看完教程后再选择合适的CUDA版本。

选择版本之后按照自己的配置选择下载对应的exe即可
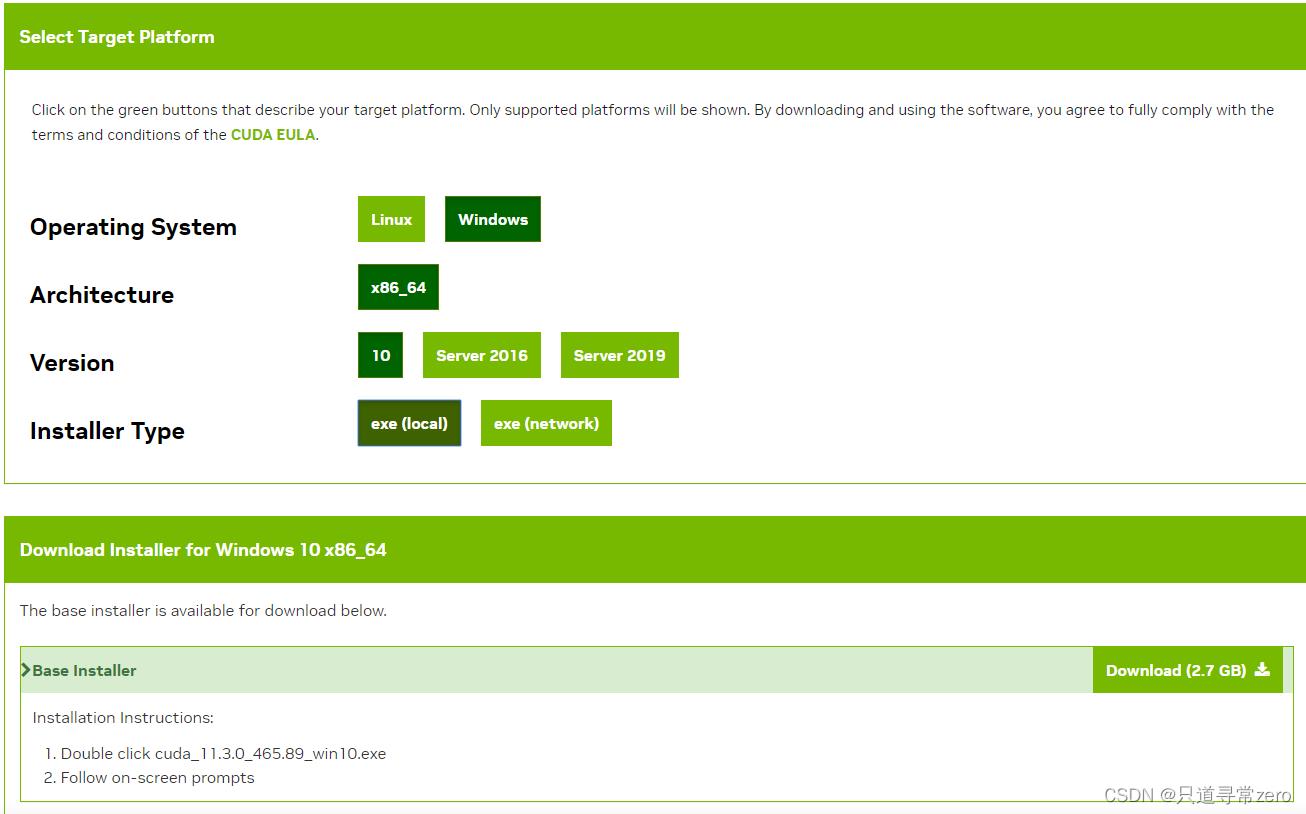
运行exe,开始安装,可以自定义安装路径


一直下一步,直到安装成功
安装cudnn
官网 : https://developer.nvidia.com/rdp/cudnn-archive#a-collapse51b
选择和自己的CUDA对应的版本

直接下载是需要注册账号的,我们可以展开要下载的版本,右键点击要下载的版本复制链接地址,然后拖到迅雷等下载软件帮助下载就可以不需要注册账号。

下载完成后解压,将解压后的三个文件夹复制到CUDA对应的文件夹中,即完成配置。
安装anaconda
这部分网上的教程很多就不赘述了。(好吧其实是懒得截图了)
因为不同的项目需要的环境不同,因此我们可以创建虚拟环境来运行我们的项目:
conda create -n pytorch python=3.8 #创建名为pytorch,python版本为3.8的虚拟环境
conda activate pytorch #激活虚拟环境
conda deacivate #退出虚拟环境
conda remove -n pytorch --all #删除虚拟环境
安装Pytorch
注意:按照readme里的要求,需要安装1.12版本及以上
对应版本安装指令:https://pytorch.org/get-started/previous-versions/
进入到我们刚刚创建的虚拟环境中然后输入对应的指令:
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch
测试是否安装成功:CRTL+R 输入cmd然后回车

如果得到True则说明安装成功!
踩坑记录!!!
这个地方刚开始我安装的时候一直都是false,以为是环境问题,删除重装试了非常多次依然是flase。在网上查了很多方法发现,这可能是因为conda下载下来的版本根本就不是gpu版本的!
输入conda list,可以看到正确版本应该是这样:

如果下载后发现pytorch显示的是cpu版本,那么就是掉入conda的坑里啦。conda默认的是清华源,会从清华源上下载pytorch,如果他找不到你给他指定的版本那么他就会下载一个默认的cpu版本,为了解决这个问题,我选择了一个最简单粗暴的方式,就是看一下有哪些版本,然后去下载对应的cuda,这也就是为什么我后来下载了11.3的CUDA。

python3.8 + cuda11.3 + cudnn8_0 全都是对应的版本就不会出错啦!
链接地址:https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/win-64/
安装依赖
可以根据readme所给的指令,直接pip install -r requirements.txt
文件内容:
matplotlib==3.6.2
numpy==1.23.5
Pillow==9.3.0
tqdm==4.64.1
wandb==0.13.5
但是这样会很慢,推荐使用镜像源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib==3.6.2
注意,这些命令都要在我们刚刚创建的虚拟环境中执行。
2.数据准备
参考博客 : https://blog.csdn.net/ECHOSON/article/details/122914826
准备两个文件夹,一个是原始图片,一个是标注后的mask
使用的标注软件是labelme
可以使用命令行下载并使用,激活虚拟环境,输入:
pip install labelme #同样也可以使用镜像源
之后直接在命令行中输入labelme就可以启动了。
得到json文件后要转成png格式才能够使用,转换代码:
from __future__ import print_function
import argparse
import glob
import math
import json
import os
import os.path as osp
import shutil
import numpy as np
import PIL.Image
import PIL.ImageDraw
import cv2
def json2png(json_folder, png_save_folder):
if osp.isdir(png_save_folder):
shutil.rmtree(png_save_folder)
os.makedirs(png_save_folder)
json_files = os.listdir(json_folder)
for json_file in json_files:
json_path = osp.join(json_folder, json_file)
os.system("labelme_json_to_dataset ".format(json_path))
label_path = osp.join(json_folder, json_file.split(".")[0] + "_json/label.png")
png_save_path = osp.join(png_save_folder, json_file.split(".")[0] + ".png")
label_png = cv2.imread(label_path, 0)
label_png[label_png > 0] = 255
cv2.imwrite(png_save_path, label_png)
# shutil.copy(label_path, png_save_path)
# break
if __name__ == '__main__':
# !!!!你的json文件夹下只能有json文件不能有其他文件
json2png(json_folder="D:/Project/testData/jsons/",png_save_folder="D:/Project/testData/jsons/labels/")
最终文件结构如下
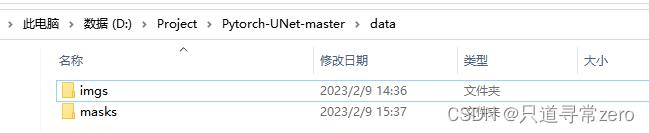
imgs中放的是原始图片,masks里是标注后的mask,注意图片名称要一一对应。这部分可看参考博客,博主写的很详细。
主要想说的是数据增强以及遇到的坑。
由于原始数据的数量很少,因此训练效果不佳,想到可以通过数据增强的方式来扩充图片的数量。
使用Augmentor来做语义分割的数据增强
创建一个虚拟环境Augmentor,激活虚拟环境并下载Augmentor:
conda create -n Augmentor python=3.8
conda activate Augmentor
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Augmentor
新建两个文件夹test1和test2
import Augmentor
# 确定原始图像存储路径以及掩码文件存储路径,需要把“\\”改成“/”
p = Augmentor.Pipeline("D:/Project/Augmentor/test1") #原图
p.ground_truth("D:/Project/Augmentor/test2") #标注后的图
# 图像左右互换: 按照概率0.5执行
p.flip_left_right(probability=0.5)
p.flip_top_bottom(probability=0.5)
#随机亮度增强/减弱,min_factor, max_factor为变化因子,决定亮度变化的程度,可根据效果指定
p.random_brightness(probability=1, min_factor=0.7, max_factor=1.2)
#随机颜色/对比度增强/减弱
#p.random_color(probability=1, min_factor=0.0, max_factor=1)
p.random_contrast(probability=1, min_factor=0.7, max_factor=1.2)
#随机翻转(flip_random)
p.flip_random(probability=1)
# 最终扩充的数据样本数可以更换为100。1000等
p.sample(1000)
最终图片都会输出到output文件夹中,然后手动将原图和mask分开。
为训练做准备,我们需要把图片的名字修改一下,一是保证原图和mask的名字是一样的,二是生成的图片名称中有两个.,不利于训练的时候分割名字
批量修改图片名称代码如下,大家根据自己的需要稍微修改一下代码即可:
#批量修改后缀名
path = 'D:/Project/Pytorch-UNet-master/data/imgs' #文件地址
list_path = os.listdir(path) #读取文件夹里面的名字
for index in list_path: #list_path返回的是一个列表 通过for循环遍历提取元素
name = index.split('.')[0] + '.png'
print(name)
os.rename(os.path.join(path,index),os.path.join(path,name))
到这一步我们已经得到了扩充后的1000张图片以及对应的mask,新的问题出现了,我在训练的时候只需要两类,类似于下图这种,只有0和255两种像素:

但是数据增强之后得到的图片像素值可能有很多种,因此我们需要做个简单的修改让我们的图片像素值满足训练的需要(c++实现):
void getFiles(string path, vector<string>& files);
int main()
vector<string> files;
string path = "D:\\\\Project\\\\Augmentor\\\\mask";
getFiles(path, files);
// 遍历文件夹下所有文件
for (int i = 0; i < files.size(); i++)
Mat src = imread(files[i]);
for (int i = 0; i < src.rows; i++)
for (int j = 0; j < src.cols; j++)
if(src.at<cv::Vec3b>(i, j)[0] > 50)
src.at<cv::Vec3b>(i, j)[0] = 255;
src.at<cv::Vec3b>(i, j)[1] = 255;
src.at<cv::Vec3b>(i, j)[2] = 255;
else
src.at<cv::Vec3b>(i, j)[0] = 0;
src.at<cv::Vec3b>(i, j)[1] = 0;
src.at<cv::Vec3b>(i, j)[2] = 0;
imwrite(files[i], src);
return 0;
void getFiles(string path, vector<string>& files)
//文件句柄
long long hFile = 0;
//文件信息
struct _finddata_t fileinfo;
string p;
if ((hFile = _findfirst(p.assign(path).append("\\\\*").c_str(), &fileinfo)) != -1)
do
//如果是目录,迭代之
//如果不是,加入列表
if ((fileinfo.attrib & _A_SUBDIR))
if (strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0)
getFiles(p.assign(path).append("\\\\").append(fileinfo.name), files);
else
files.push_back(p.assign(path).append("\\\\").append(fileinfo.name));
while (_findnext(hFile, &fileinfo) == 0);
_findclose(hFile);
到这一步就离成功很接近了,但是我在将图片丢进去训练的时候依然出现了问题,提示我两次输入的维度不一样,经过排查发现,这是因为原始的mask是8位图,而增强后的mask是24位图,所以我们还需要把位深转换一下:
#24位转8位
path = 'D:/Project/Augmentor/mask' #文件地址
path1 = 'D:/Project/Augmentor/masktest'
list_path = os.listdir(path) #读取文件夹里面的名字
for index in list_path: #list_path返回的是一个列表 通过for循环遍历提取元素
print(os.path.join(path,index))
p1 = os.path.join(path,index)
p2 = os.path.join(path1,index)
print(p1)
print(p2)
img = cv2.imread(os.path.join(path,index)) # 填要转换的图片存储地址
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imwrite(os.path.join(path1,index),img) # 填转换后的图片存储地址,若在同一目录,则注意不要重名
至此,所有对图片的处理才算是完全完成了。
3.开始训练
修改合适的参数以及自己要分割的类别数等等,img_scale是图片resize的比例,如果图片太大训练的时候出现显存不足的错误的时候,可以尝试将这个值改小一些。
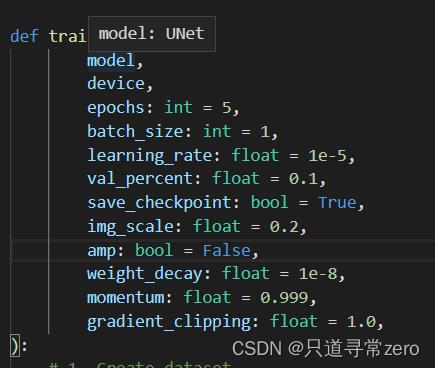
然后就可以开始训练啦!使用命令行执行的话记得一定到进入到对应的磁盘以及虚拟环境下,如果不在同个磁盘会报错,环境不对的话就更不能执行了。
执行命令:

以上是关于手把手教你用Unet实现语义分割(Pytorch版)的主要内容,如果未能解决你的问题,请参考以下文章