MapReduce编程模型及其在Hadoop上的实现
Posted YDDMAX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce编程模型及其在Hadoop上的实现相关的知识,希望对你有一定的参考价值。
转自:https://www.zybuluo.com/frank-shaw/note/206604
MapReduce基本过程
关于MapReduce中数据流的传输过程,下图是一个经典演示: 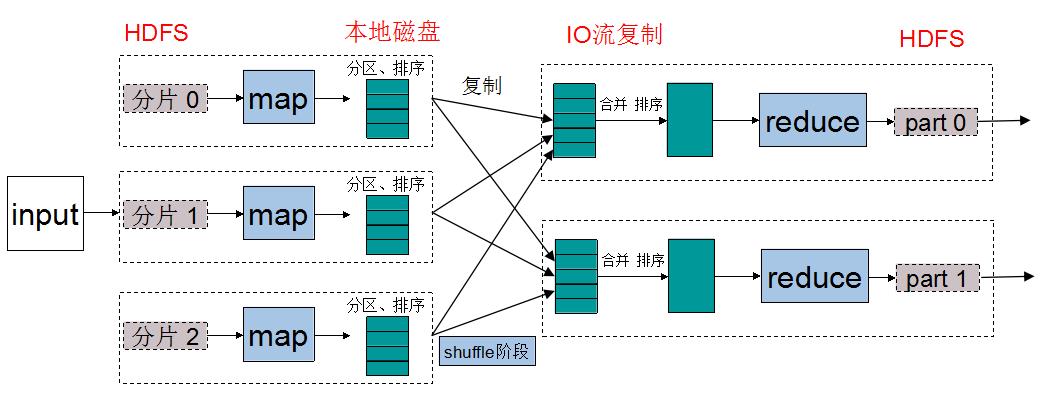
关于上图,可以做出以下逐步分析:
- 输入数据(待处理)首先会被切割分片,每一个分片都会复制多份到HDFS中。上图默认的是分片已经存在于HDFS中。
- Hadoop会在存储有输入数据分片(HDFS中的数据)的节点上运行map任务,可以获得最佳性能(数据TaskTracker优化,节省带宽)。
- 在运行完map任务之后,可以看到数据并不是存回HDFS中,而是直接存在了本地磁盘上,因为map输出数据是中间数据,该中间数据由reduce任务处理之后才会产生最终输出结果,reduce任务完成之后这些数据是要被删除掉的。
- map的输出结果会在本地进行分区,并进行排序,这是为之后的reduce阶段做准备。分区方法常用的是对key值进行Hash转换之后求模,这样就可以将相同key值的数据放在同一个分区,reduce阶段同一个分区的数据会被安排到同一个reduce中。
- 如果有必要,可以再map阶段设置combine方法,combine方法与reduce方法的函数体是同一个(做的事是一样的),只不过combine方法针对的对象只是当前map中key值相同的数据,而reduce方法处理的是所有输入数据中相同的key对应的数据。也就是说,它只是reduce的一个小分身。这么做的目的是为了减轻从map阶段传送到reduce阶段的IO传送负担,也是节省带宽的一种方式(做了combine优化之后,传送的数据量会大大减少)。
- 每一个reduce都会将所有map对应分区的数据通过IO复制过来,进行合并。合并的过程包含排序的过程,因为要将相同的key值对应的数据统一处理。在reduce计算阶段,reduce的输入键是key,而输入值是相同的key数据对应的value所构成的一个迭代器数据结构。
- 经过reduce处理之后,最后的输出结果就是我们想要的结果。该输出会存储在HDFS中,第一块副本存储在本地节点上,其他副本存储在其他机架节点中。进一步,可以将这些输出结果作为另一个MapRuce任务的输入,进行更多的任务计算。
OK,大致的步骤就是这样。这里面有很多实践上的细节值得注意。本人经验为0,说不出任何实际的经验之谈。下一节写的只是尝试解决自己在认知过程中冒出的一些疑惑,查阅网上资料之后得到的一些解惑。
疑问及解答
1. 如何设置分片的数量?
已知map的数量与分片的数量相同(一般情况下都是这样)。如果分片数量太少(每个分片很大),那么mapper的数量就会太少,整个任务的执行就会慢。如果分片分得太多(每个分片很小),那么管理分片的总时间和构建map任务的总时间将决定着整个任务的执行时间。由此看来,合理设置一个分片的大小很重要。
在《Hadoop权威指南 第四版英文版》一书中,有讲到:一个合理的分片大小趋向于HDFS的一个块的大小(最新的版本一个块大小为128M)。当然我们可以自己设置分片的大小。
在新版的org.apache.hadoop.mapred.InputFormat抽象类中,有getSplits(JobConf job, int numSplits)方法,其中的numSplits只是一个hint,实际上的分片数量计算公式是这样的:
minSize=max{minSplitSize,mapred.min.split.size} (minSplitSize大小默认为1B)
maxSize=mapred.max.split.size(不在配置文件中指定时大小为Long.MAX_VALUE)
splitSize=max{minSize,min{maxSize,blockSize}}
其中mapred.min.split.size、mapred.max.split.size、blockSize均可以再配置文件中配置,前面两个在mapred-site.xml中,最后一个可在在hdfs-site.xml中进行配置,单位均为B。
可以看到,如果参数mapred.min.split.size、mapred.max.split.size都设置为默认值的话,那么splitSize的大小即为blockSize的大小。
实际运算过程中还会有一些小小的优化:
文件大小/splitSize>1.1,创建一个split0,文件剩余大小=文件大小-splitSize
.....
剩余文件大小/splitSize<= 1.1 将剩余的部分作为一个split
每一个分片对应一个map任务,这样map任务的数目也就显而易见啦。
参考:http://www.cnblogs.com/yueliming/p/3251285.html
2.是不是一个map就一台机器呢?
这就是小白的问题了。其实并不是一个map一台机器。一个TaskTracker(具体含义下面会讲到)就是一台机器,而每一个TaskTracker都有固定数量的map槽与reduce槽。也就是说,一台机器上面有可能会有多个map与reduce同时运行,当然这些map与reduce之间可能运行的任务都是不同的。
MapReduce在Hadoop上的具体实现
可以说以上编程模型其实就是Google提出来的最基本的MapReduce编程模型, 来源于谷歌论文《MapReduce: Simplified Data Processing on Large Clusters》。但是在Hadoop上的具体实现是怎样的呢?这个我们同样需要了解。来看一下这张图: 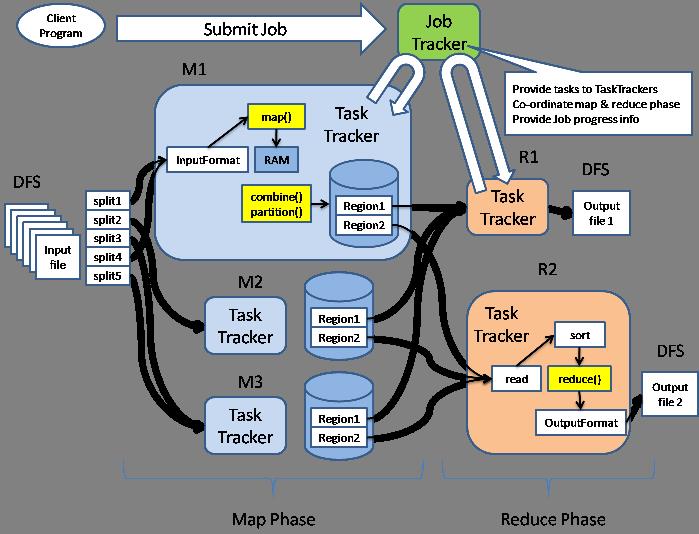
这个实现机制就是MapReduce1,在Hadoop2.x的时候实现机制变成了YARN。了解MapReduce1对于我们理解Hadoop非常有帮助,晚些时候会写一篇专门关于YARN的文章。
如果细看,可以发现,MapReduce1实现图其实与一开始的MapReduce的工作流程总体是一致的,只不过多了JobTracker、TaskTracker以及Client这几个角色。map和reduce任务分配给了多个TaskTracker来执行。这几个角色非常重要,有必要详细了解。
关于client
客户端(client):这个是程序员主要工作的部分,工作分别是编写mapreduce程序,配置相应的文件信息,提交作业。如果出现错误了,需要找出错误,修改程序,直到完美运行。
JobTracker与TaskTracker介绍
JobTracker与TaskTracker之间服从的是主从结构。从图中可以看到:主节点JobTracker只有一个,而从节点TaskTracker有很多个。
JobTracker负责:
- 接收客户提交的计算任务
- 把计算任务分配给TaskTracker执行
- 监控TaskTracker的执行情况
TaskTrackers负责:
- 完成JobTracker分配的计算任务
JobTracker与TaskTrackers之间的关系就是项目经理与开发人员的关系。项目经理接到用户的需求清单,那么将用户的需求分配给开发人员来完成。
实现机制
了解了如何从MapReduce迁移到JobTracker TaskTrackers之后,我们来详细讲讲其中的实现机制(下面讲到的每一点都对应图上的相应数字):
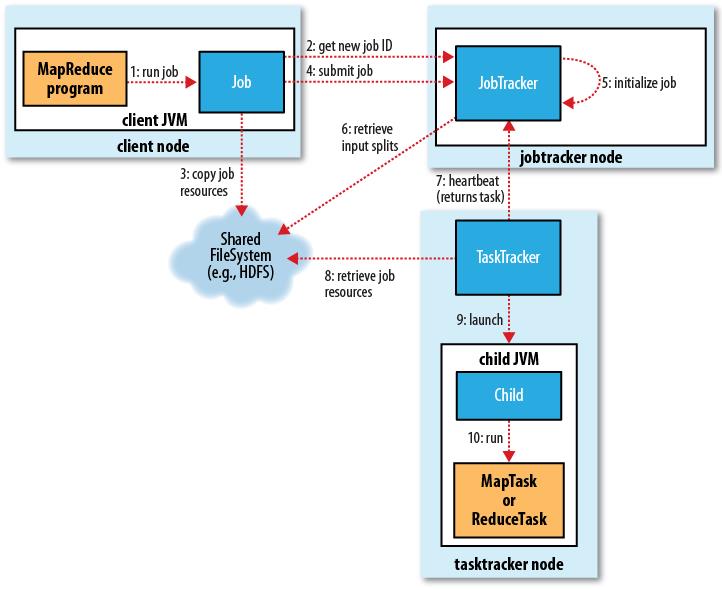
作业的提交
1.写好的一个MapReduce程序就是一个job。点击运行。此时会生成一个JobClient,它会做一系列的准备工作,当准备工作做好了之后,才会向JobTracker提交任务。
2.JobClient向JobTracker请求一个新的job ID。与此同时,JobClient会先做如下检查:
- 检查作业的输出目录,如果未指定或已存在则不提交作业并抛错误给程序;
- 检查输入目录是否存在,如果不存在同样抛出错误;如果存在,JobTracker会根据输入计算输入分片(Input Split)并生成分片,如果分片计算不出来也会抛出错误。
3.JobClient将运行作业所需要的资源(包括作业jar文件,配置文件和计算所得的输入分片)复制到JobTracker的文件系统中以job ID命名的目录下(即HDFS中)。值得注意的是,作业jar副本较多(默认mapred.submit.replication = 10)。
4.上面的准备工作做好了之后,它会给JobTracker提交任务(它会告知JobTracker:大哥,我们这边准备好了,随时可以战斗。哎呀呀,逗比了)。
作业的初始化
5.JobTracker接收到作业提交信息后,将其放入内部队列,交由job scheduler进行调度,并对其进行初始化(初始化就是创建一个正在运行的job对象(封装任务和记录信息),以便JobTracker跟踪job的状态和进程)。
6.初始化完毕后,作业调度器会获取输入分片信息(input split),每个分片创建一个map任务。关于分片的数量问题(即map数量),前面已经有提及。关于reduce数量,则是由用户在配置文件里指定的。
除了map和reduce任务,还有setupJob和cleanupJob需要建立:由每一个TaskTrackers在所有map开始前和所有reduce结束后分别执行。setupJob()创建输出目录和任务的临时工作目录,cleanupJob()删除临时工作目录。
作业的分配
7.每个TaskTracker定期发送心跳给JobTracker,告知自己还活着,并附带消息说明自己是否已准备好接受新任务。JobTracker以此来分配任务,并使用心跳的返回值与TaskTracker通信。JobTracker利用调度算法先选择一个job然后再选此job的一个task分配给TaskTracker.
每个TaskTracker会有固定数量的map和reduce任务槽,数量有TaskTracker核的数量和内存大小来决定。JobTracker会先将TaskTracker的所有的map槽填满,然后才填此TaskTracker的reduce任务槽。
JobTracker分配map任务时会选取与输入分片最近的TaskTracker,即数据TaskTracker优化。在分配reduce任务用不着考虑数据TaskTracker。
任务的执行
8.TaskTracker分配到一个任务后,首先从HDFS中把作业的jar文件及运行所需要的全部文件(DistributedCache设置的)复制到TaskTracker**本地**。接下来TaskTracker为任务新建一个本地工作目录,并把jar文件的内容解压到这个文件夹下(此时需要用到的就是前面提及的setupJob(),其作用是创建输出目录和任务的临时工作目录)。
9.TaskTracker新建一个taskRunner实例来运行该任务。
10.TaskRunner启动一个新的JVM来运行每个任务。
此时图中显示的所有动作都已经写下来了。只不过还有一些细节需要把握。请看下面:
进度和状态的更新
Child JVM有独立的线程每隔3秒检查任务更新标志,如果有更新就会报告给此TaskTracker;
TaskTracker每隔5秒给JobTracker发心跳;(当然这个时间可以设置)
job tracker合并这些更新,产生一个表明所有运行作业及其任务状态的全局视图。
JobClient.monitorAndPrintJob()每秒查询这些信息。
作业的完成
当JobTracker收到最后一个任务(this will be the special job cleanup task)的完成报告后,便把job状态设置为successful。Job得到完成信息便从waitForCompletion()返回。
最后,JobTracker清空作业的工作状态,并指示TaskTracker也清空作业的工作状态(如删除中间输出)。
失败处理机制
分布式计算过程中节点失败是很常见的。作为一个成熟的实现机制,应该有一套完善的失败处理机制。
在Hadoop的MapReduce1架构中常见失败有三种:任务失败、TaskTracker失败、JobTracker失败。
任务失败
- 子任务失败。当map或者reduce子任务中的代码抛出异常,JVM进程会在退出之前向服进程TaskTracker进程发送错误报告,TaskTracker会将此(任务尝试)task attempt标记为failed状态,释放一个槽以便运行另外一个任务。
- jvm失败。JVM突然退出,即JVM错误,这时TaskTracker会注意到进程已经退出,标记为failed。
值得注意的是:
1)任务失败有重试机制,重试次数map任务设置是mapred.map.max.attempts属性控制,reduce是mapred.reduce.max.attempts属性控制。
2)一些job可以完成任务总体的一部分就能够接受,这个百分比由mapred.map.failures.precent和mapred.reduce.failures.precent参数控制。
3)任务尝试(task attempt)是可以中止(killed)的。
TaskTracker失败
作业运行期间,TaskTracker会通过心跳机制不断与系统JobTracker通信,如果某个TaskTracker运行缓慢、失败或者出现故障,TaskTracker就会停止或者很少向JobTracker发送心跳,JobTracker会注意到此TaskTracker发送心跳的情况,从而将此TaskTracker从等待任务调度的TaskTracker池中移除。
由于TaskTracker中包含有一定数量的map和reduce子任务,这个时候这些子任务怎么处理呢?
1) 如果是map并且成功完成的话, JobTracker会安排此TaskTracker上一成功运行的map任务返回。
2) 如果是reduce并且成功的话,数据直接使用,因为reduce只要执行完了的就会把输出写到HDFS上。
3) 如果他们属于未完成的作业的话,reduce阶段无法获取该TaskTracker上的本地map输出文件,任何任务都需要重新调度。
另外,即使TaskTracker没有失败,如果其上的失败子任务远远高于集群的平均失败子任务数,也会被列入黑名单。可以通过重启从JobTracker的黑名单移除。
###jobtracker失败
jobtracker失败应该说是最严重的一种失败方式了,而且在Hadoop中存在单点故障的情况下是相当严重的,因为在这种情况下作业会最终失败,尽管这种故障的概率极小。
参考:
http://blog.csdn.net/thomas0yang/article/details/41211101
http://www.cnblogs.com/sharpxiajun/p/3151395.html
以上是关于MapReduce编程模型及其在Hadoop上的实现的主要内容,如果未能解决你的问题,请参考以下文章