MapReduce编程模型——在idea里面邂逅CDH MapReduce
Posted 肥猪猪爸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce编程模型——在idea里面邂逅CDH MapReduce相关的知识,希望对你有一定的参考价值。
🏠MapReduce
MapReduce是一个分布式运算程序的编程框架,它是hadoop的重要组成部分,其主要负责分布式计算。MapReduce具有高容错性的优点,适合海量数据的离线处理。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。编写一个完整的MapReduce任务只需要三步:
1、编写mapper阶段的逻辑代码
2、编写reducer阶段的逻辑代码
3、将mapper阶段和reducer阶段组合,连同一些配置,组织成主任务,并提交任务。
更为复杂的任务可以多次重复以上三步。
本文在IDEA中编写基于CDH的MapReduce任务并操作CDH平台HDFS中的文件。
MapReduce的原理有很多可以参考的文章,这里只给出实操的部分。
🏠案例
本文要完成的目标是统计HDFS上文本文件中单词的个数,包括中文,单词的分隔符采用空格。HDFS用户采用匿名用户:anonymous,文件输入路径是:/user/anonymous/mrtest/one/input,输出路径是:/user/anonymous/mrtest/one/output。用户和路径读者均可自行修改。
程序处理流程大致如下:
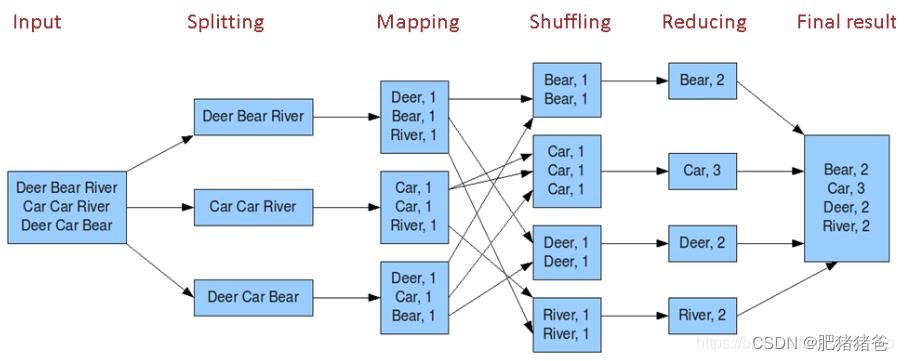
👉环境
大数据平台:集群 CDH 6.2.3
本地开发环境:Windows10
👉部署本地开发环境
下载winutils-master并解压,解压后,目录内容如下:
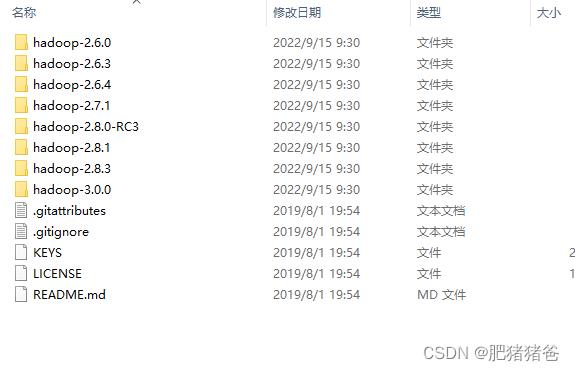
将该目录中的 hadoop-3.0.0 文件夹路径设置为环境变量 HADOOP_HOME,将 hadoop-3.0.0\\bin 中的 hadoop.dll 复制到 C:\\Windows\\System32 目录下。
👉编写代码
1、在IDEA中新建maven项目
2、登录CDH管理页面,下载HDFS的配置文件,如下:
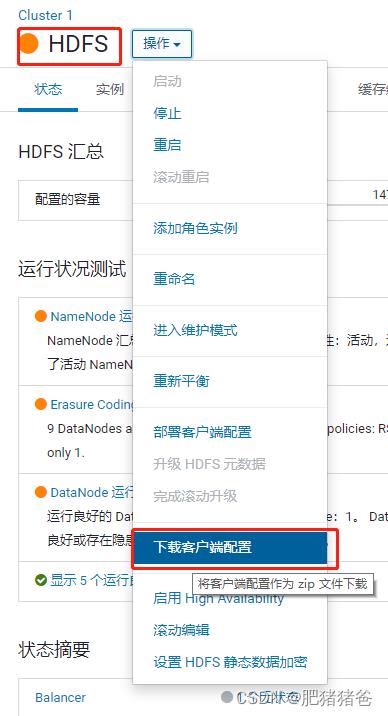
文件下载到本地后,解压,将里面的 core-site.xml 和 hdfs-site.xml 两个文件复制到项目的resources目录下:
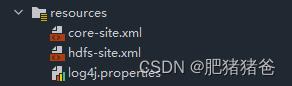
3、编写代码
项目的pom文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hadooptest</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<hadoop_version>3.0.0-cdh6.3.2</hadoop_version>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>$hadoop_version</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>$hadoop_version</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>$hadoop_version</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>$hadoop_version</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-yarn-api -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>$hadoop_version</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
日志输出配置如下:
log4j.rootLogger=INFO,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%dyy/MM/dd HH:mm:ss %p %c2: %m%n
Mapper类如下:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
// 分词
String[] words = value.toString().split(" ");
Text text = new Text();
IntWritable cnt = new IntWritable(1);
for (String word : words)
text.set(word);
context.write(text, cnt);
Reducer类如下
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
int sum = 0;
for (IntWritable val : values)
sum += val.get();
result.set(sum);
context.write(key, result);
主程序如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class App
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException
// 设置用户
System.setProperty("HADOOP_USER_NAME", "anonymous");
// 任务配置
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "my wordcount");
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setJarByClass(App.class);
// 输入输出路径
Path inputPath = new Path("mrtest/one/input");
Path outputPath = new Path("mrtest/one/output");
// 输出目录若存在,则进行删除
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(outputPath))
fileSystem.delete(outputPath, true);
// 给任务设置输入输出路径
FileInputFormat.addInputPath(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 提交任务
boolean flag = job.waitForCompletion(true);
if (flag)
System.out.println("程序运行结束!!");
作者这水平有限,有不足之处欢迎留言指正!!
以上是关于MapReduce编程模型——在idea里面邂逅CDH MapReduce的主要内容,如果未能解决你的问题,请参考以下文章