MySQL 笔记
Posted 一只小阿大:)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 笔记相关的知识,希望对你有一定的参考价值。
目录
- 数据库系统框图
- 常见的数据库
- SQL语句分类
- 数据库的数据类型
- 字段约束
- DDL Data Definition Language 数据定义语言
- DQL Data Query Language 数据查询语言
- 关联关系
- 外键约束
- 连接查询
- 子查询/嵌套查询
- 存储过程
- 索引 index
- 事务
- 数据库设计
此文章记录作者笔记,对其他读者来说可能没用
虽然学过数据库,好久没用了,除了简单的语句其他的都忘记的差不多了,重新捡一下。
本文章图片截取自B站千锋教育mysql课程
学完查询语句其实也就没啥了,存储过程以及视图,触发器现开发中用的很少,索引必看!
数据库系统框图
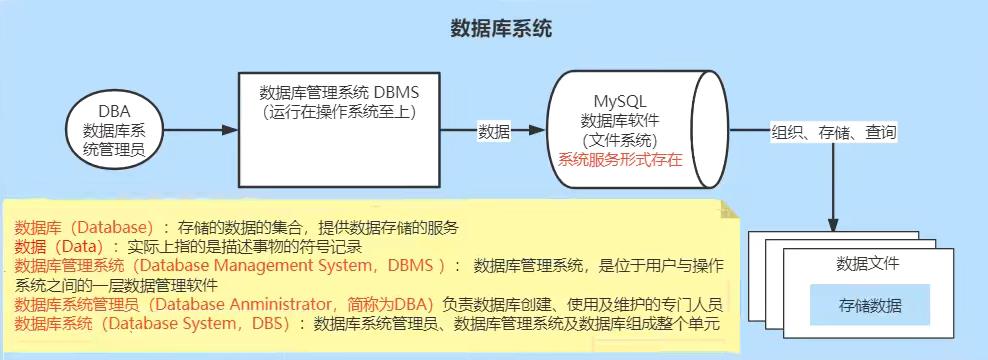
常见的数据库
在关系型数据库数据量非常庞大的时候,会造成查询慢的问题,除了加where字段这样的数据库优化,那么就使用非关系型数据库提升查询速度
关系型数据库(Relational database)
常用的mysql(免费),Orecal(收费),以及本人大学学的SQL Server
非关系型数据库(Not only SQL)
面向检索的列式存储
HaBase(Hadoop子系统)
BigTable(Google)
面向高并发的缓存存储(键值对 Key_Value)
最常见的就是Redis
SQL语句分类

数据库的数据类型
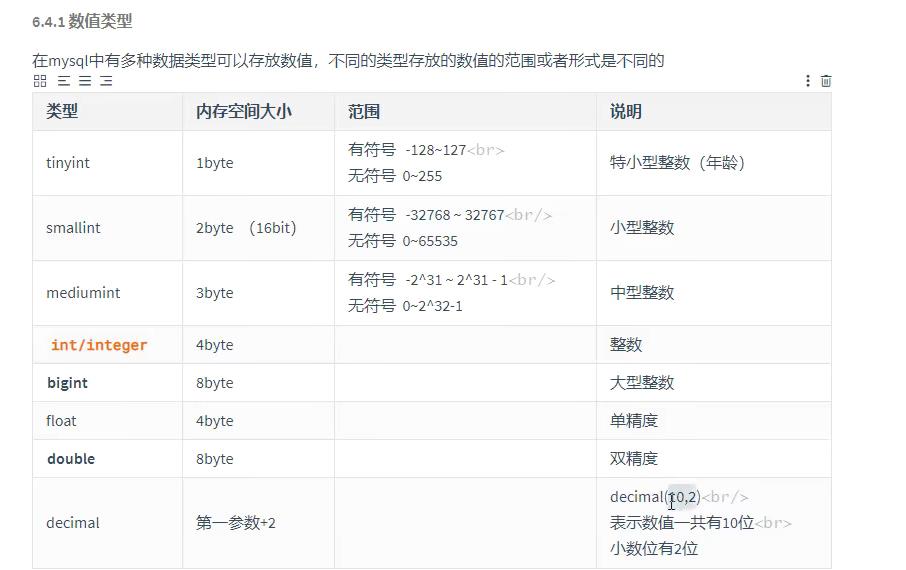
数据库数据类型有三种,分别为数值类型,字符串类型,日期类型。
数值类型
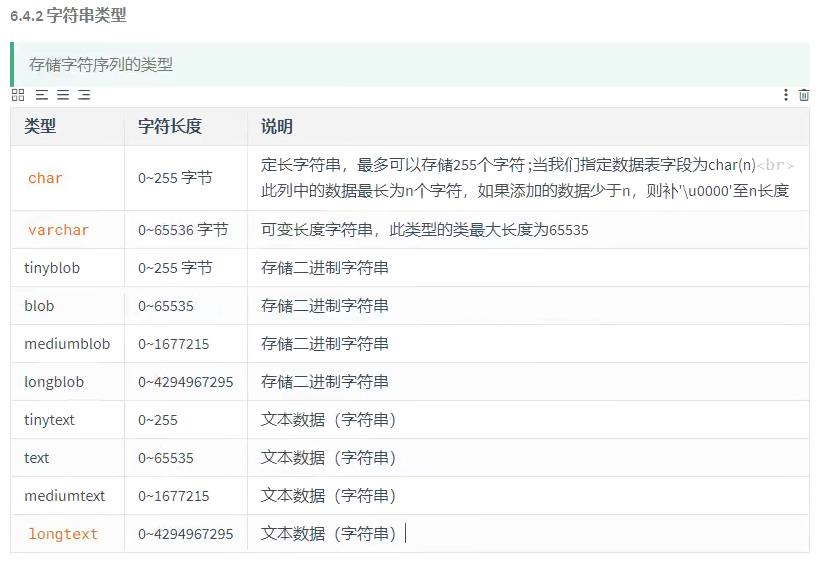
字符串类型
日期类型

字段约束
除了下图四个约束,还有联合约束,自动增长约束。
联合约束:在一张表中,没有唯一的字段能当主键,这时候使用联合主键,将两个字段联合成的主键,一般联合约束使用较少,还不如添加个id字段当主键。
自动增长约束:比如主键id他肯定不能重复,那么我新增一条数据,id自动增长,但自动增长不能保证连续性,比如自动添加到了15,把7-15的数据删除,他自动添加还是会在16,不会跑到6。

主键约束和唯一约束区别
1.主键约束是唯一的,一张表中只有这一个,但唯一约束可以多个。
2.主键约束可以添加自动增长约束,唯一约束不行。
3.主键约束唯一但不能为空,唯一约束唯一可以为空
4.主键约束字段可以做为其他表的外键,唯一约束字段不可以做为其他表的外键。
DDL Data Definition Language 数据定义语言
数据库

数据表

DQL Data Query Language 数据查询语言
LIKE 模糊查询
数据库有下图这么多数据

执行模糊查询语句,查找表中user_name这一列包含d字符的数据
SELECT user_name FROM sys_user WHERE user_name LIKE ‘%d%’
查询结果如下图

% 代表任意多个的意思
‘%d%’ 表示只要包含d字符
‘%d’ 表示d字符结尾
‘d%’ 表示d字符开头
==’_’==表示一个字符
==’_d%’==表示第二个字符为d的
举例: SELECT user_name FROM sys_user WHERE user_name LIKE ‘_d%’
查询结果处理
最经典的是用当前年份减去年龄获取出生年份
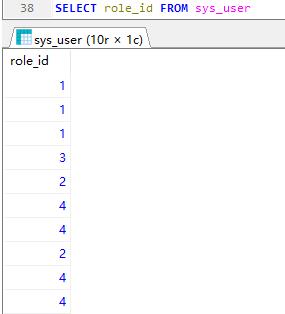
下图是没处理的
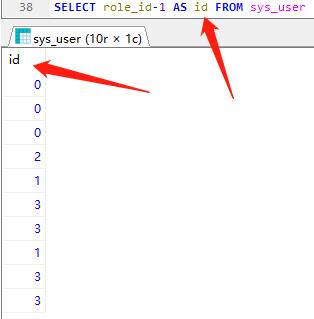
下图是处理了,查询结果减一,并给字段取别名id
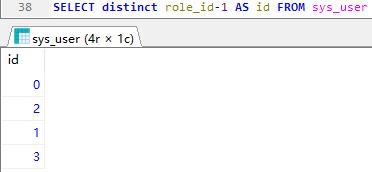
消除重复行 distinct
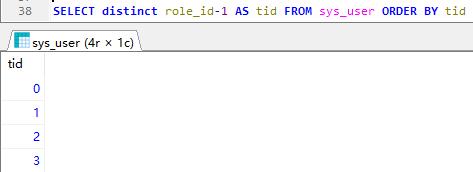
排序 order by
默认为升序(asc),降序为desc
排序根据你查询的字段来排序
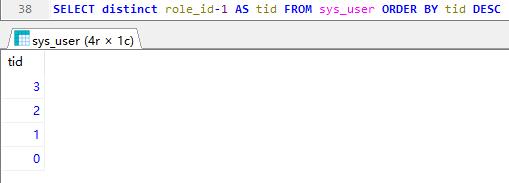
多字段排序
多字段排序算是使用联合索引,那么就会遵循最左原则。
先tid倒序完了,再将phone倒序
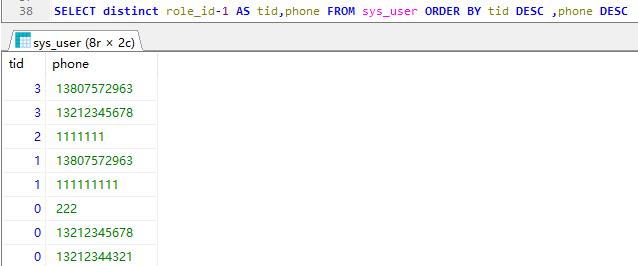
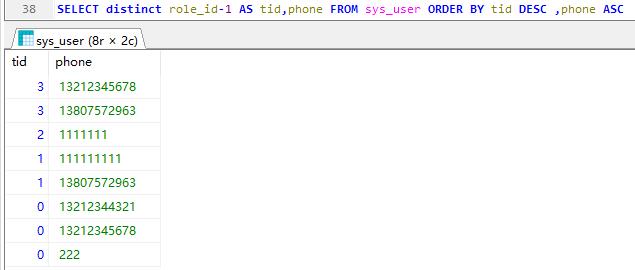
先tid倒序完了,再将phone升序,默认升序,其实ASC可以不用写
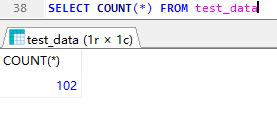
聚合函数
count 统计函数
查询test_data表有多少条数据
也可以添加where条件
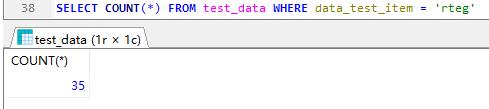
max 最大值
满足查询条件的最大值,下图是查询test_data表,data_test_item = ‘rteg’ id的最大值
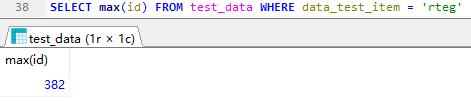
min 最小值
满足查询条件的最小值,下图是查询test_data表,data_test_item = ‘rteg’ id的最小值
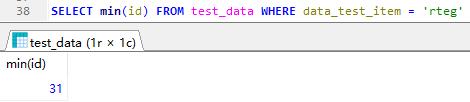
sum 计算总和
满足查询条件的总和,下图是查询test_data表,data_test_item = ‘rteg’ 所有 id 总和
avg 平均值
计算满足查询条件的id平均值

日期函数
日期函数有固定格式,按照固定格式进行添加删除,日期函数说到底也就是字符串函数。
数据库可以 now() 或者 sysdata() 获取当前电脑时间日期
字符串函数
字符串函数是通过sql语句对字符串进行处理
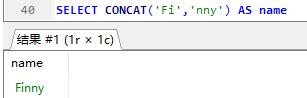
concat 字符串拼接

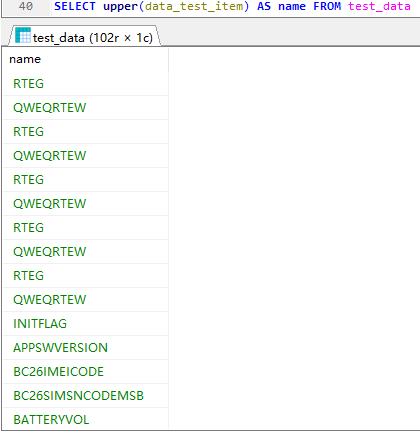
upper 字符串小写转大写
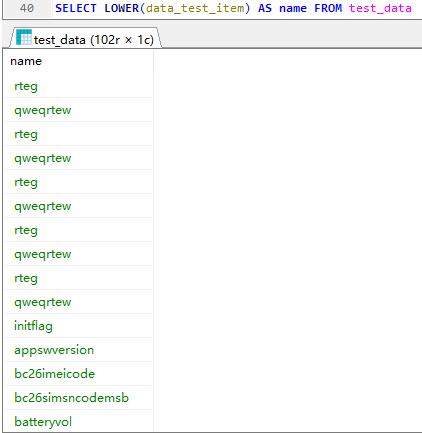
lower 字符串转小写
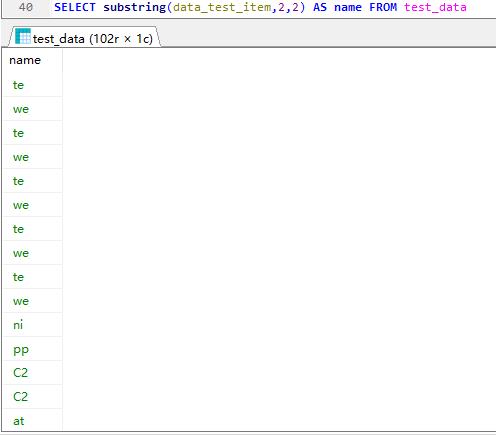
substring 截取指定列中任意字符
数据库从1开始计数不是从0开始计数,取2位
group by 分组查询
将数据表中的数据按照指定的类进行分组
只会显示分组第一条
SELECT 分组字段/聚合函数 FROM 表名 WHERE 条件 GROUP BY 列名
查询测试数据分组,计数同样数据有多少个并取别名为总数,按照降序排序
SELECT data_test_data,COUNT(data_test_data) AS ‘总数’ FROM test_data GROUP BY data_test_data ORDER BY COUNT(data_test_data) DESC
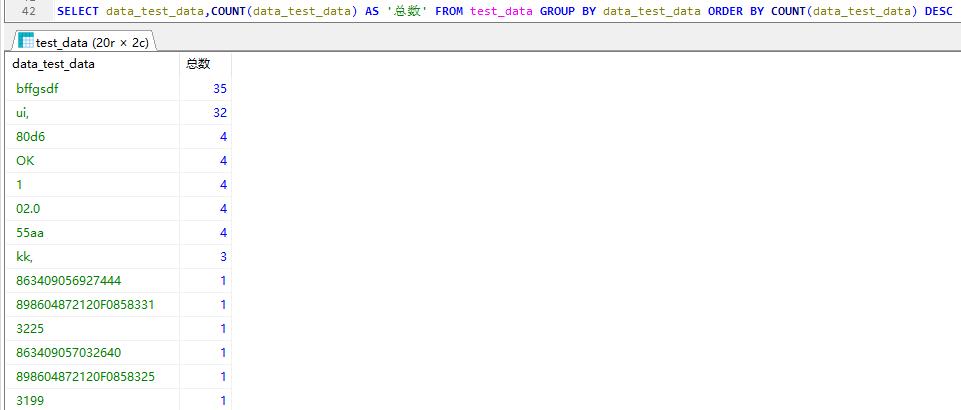
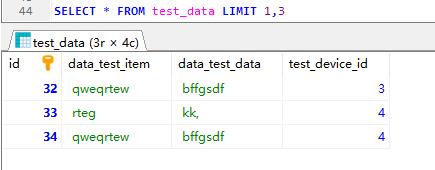
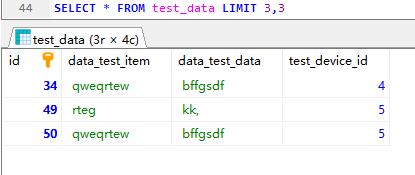
limit 分页查询
会发现第一个参数代表的是索引从哪开始(索引从0 开始),第二个参数是查询记录的条数(如果没有那么多条,那么只会返回有的)
找规律嘛,会发现每页会跟参数二pagesize对应,所以第一页就是从0开始索引就是0*pagesize,也可以写成(1-1)*pagesize


关联关系
MySQL是一个关系型数据库,不仅可以存储数据,还可以维护数据与数据之间的关系–通过在数据表中添加字段建立外键约束
想要表与表之间关联,那么就需要存储另一个表的唯一字段,比如主键id或者唯一索引
数据与数据之间的关联关系分为四种:
- 一对一
- 一对多
- 多对一
- 多对多
多对多的话需要建立一个关系表,把另外两张表的主键都放到该表中建立联系。
外键约束
开发中通常外键约束不会使用,自己知道这个字段是存储其他表id就行了,确保其他表有这个id
因为设置外键约束会有级联,要删除相关的主键,必须把其他表外键绑定的id给删除才能删除主键,就比较麻烦。
连接查询
在MySQL中可以使用join实现多表的联合查询–连接查询,join按照其功能分为三个操作
- inner join 内连接
- left join 左连接
- right join 右连接
内连接
使用内连接会获取多表集合的笛卡尔积(每条数据都对应的另一个表的全部),如果有两张表A和B,那么就是A*B,会造成数据非常多,然后再过滤,会导致速度很慢,拿下面语句举例
SELECT * FROM test_device INNER JOIN test_data WHERE test_device.id = test_data.test_device_id

那么就可以选择使用ON,那么ON和WHERE区别在于,ON是先比较,再连接。WHERE指的条件筛选,会先生成笛卡尔积再筛选。
左连接
语法跟内连接一样,但有个细小的区别
select * from leftTable LEFT JOIN rightTable ON 匹配条件
左表和右表根据LEFT JOIN来看,在左边就是左表,在右边就是右表
左连接:显示左表中所有数据,如果在有右表中存在与左表记录满足匹配条件的数据,则进行匹配;如果右表中不存在匹配数据,则显示为NULL
左连接和内连接区别,内连接是需要查到两张表有匹配关系的,左连接是有匹配关系显示,没有匹配关系不显示(NULL)
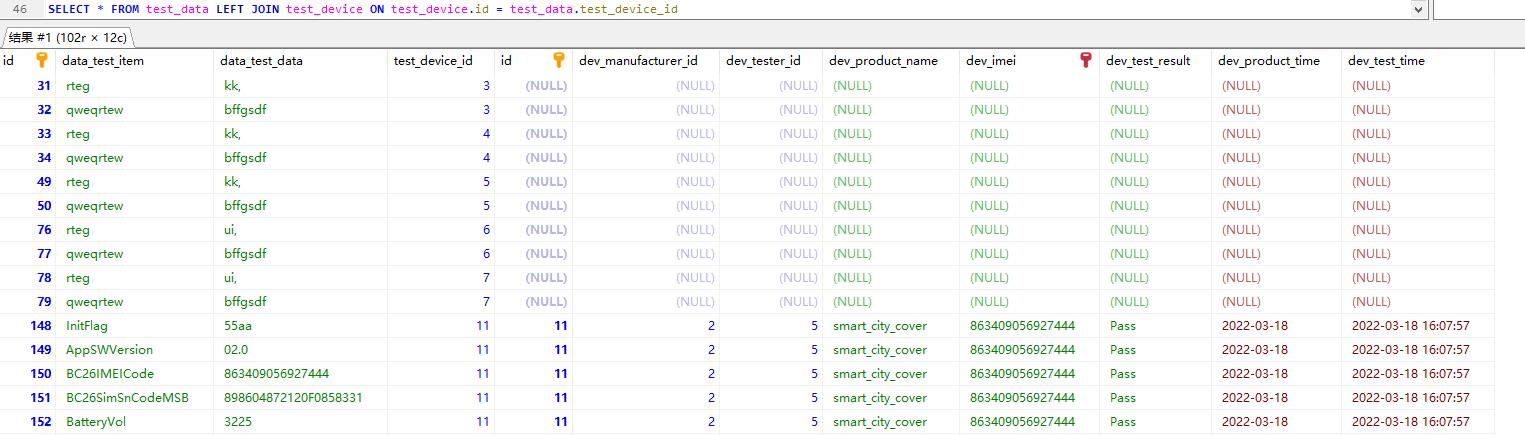
右连接
左连接是显示左表,右连接就是显示右表,没啥大区别
别名
如果两张数据表都有id这个字段,如何区分,加上表名即可
之前有个字段别名AS,那么可以对表取别名,在表名后添加即可
SELECT * FROM test_data da LEFT JOIN test_device de ON de.id = da.test_device_id
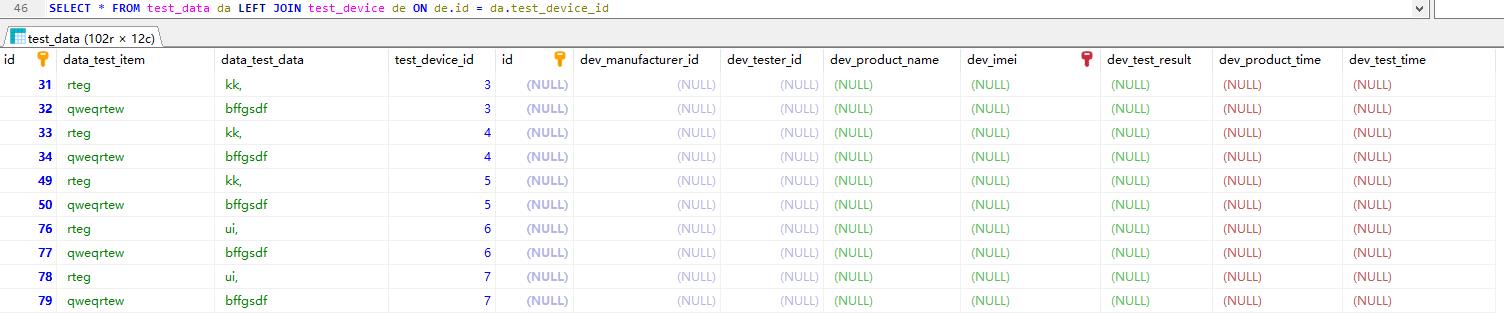
子查询/嵌套查询
子查询:先进行一次查询,查询的结果作为第二次查询的源/条件
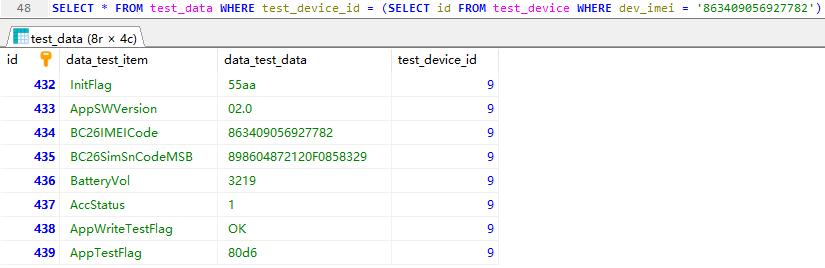
单行单列
SELECT * FROM test_data WHERE test_device_id = (SELECT id FROM test_device WHERE dev_imei = ‘863409056927782’)
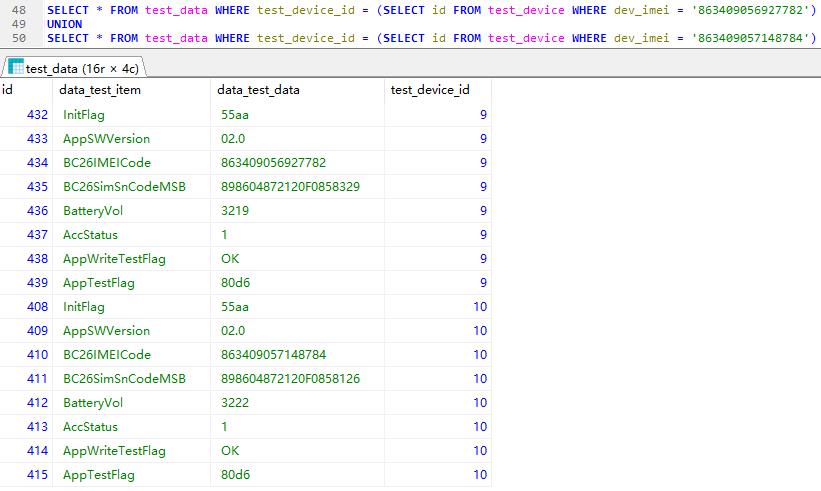
多行单列
union 将多个查询结果整合在一起,传统方法,比较麻烦
还有一种方法,配合模糊查询以及IN关键字或者NOT IN即可达到想要的效果

多行多列
多条件查询
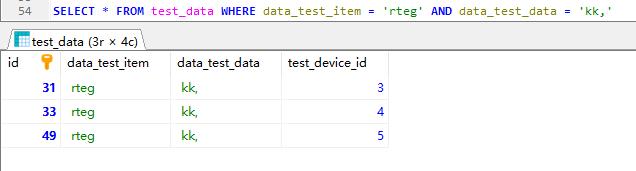
使用子查询实现
先查询data_test_item为rteg的数据再查询结果表中data_test_data为kk,的数据
查询结果表称为虚拟表,需要别名
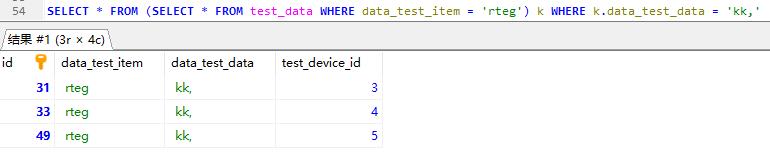
存储过程
存储过程介绍
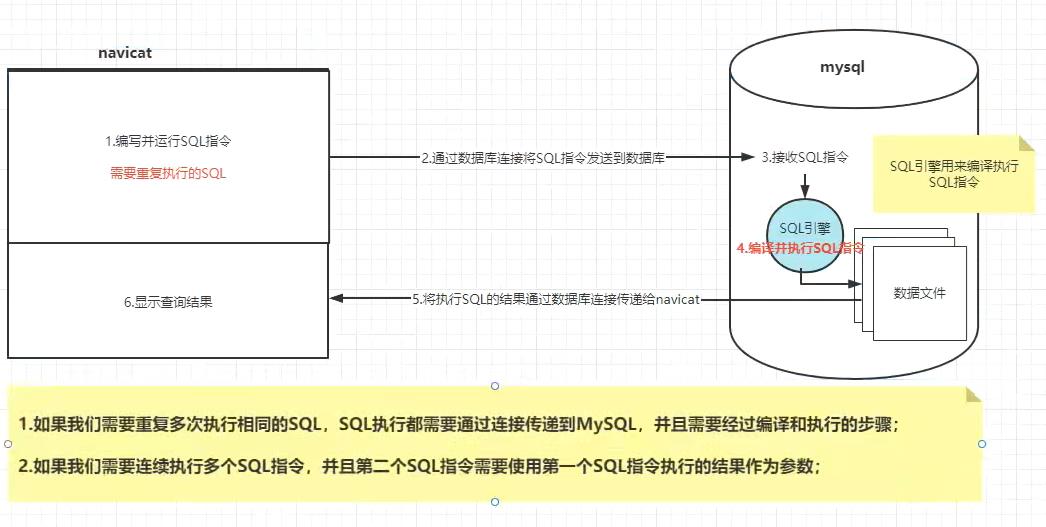
SQL指令执行过程
下面黄底是根据SQL执行流程存在的两个问题
SQL存储过程的介绍
按照上图SQL执行流程,我们可以提前写好编译好一个SQL语句,并且给他取别名,需要使用这条指令的时候,直接通过指令名调用,就会执行SQL执行。
存储过程:
-
将能够完成特定功能的SQL指令进行封装(SQL指令集),编译后存储在数据库服务器上,并且为之取了一个名字;
-
当客户端需要执行这个功能时,不用编写SQL指令,直接通过封装的SQL指令的名字完成调用即可。
这时候SQL执行步骤2就不是发送SQL指令了,而是发送指令名字,SQL引擎就会去找有没有这个指令,找到后加载,就不需要编译。
SQL指令也不需要在网络中传递,网络资源节省,还可有效的防止恶意程序进行拦截修改,也不需要对SQL语句重复编译。
简而言之就是SQL不在网络中传递,即可节省网络资源又可提升数据库安全性

存储过程优缺点
优点:
- SQL指令无需客户端编写,通过网络传输,可节省网络开销,同时避免SQL指令在网络传输过程中被恶意篡改保证安全性;
- 存储过程经过编译创建并保存在数据库中的,执行过程无需重复的进行编译操作,对SQL指令的执行过程进行了性能提升;
- 存储过程中多个SQL指令之间存在逻辑关系,支持流程控制语句(分支,循环),可以实现更为复杂的业务;
缺点
- 存储过程是根据不同的数据库进行编译、创建并存储在数据库中;当我们需要切换到其他的数据库产品时,需要重写编写针对于新数据库的存储过程;
- 存储过程受限于数据库产品,如果需要高性能的优化会成为一个问题 ;
- 在互联网项目中,如果需要数据库的高(连接)并发访问,使用存储过程会增加数据库的连接执行时间(因为我们将复杂的业务交给了数据库进行处理)
创建存储过程
创建存储过程语法
create procedure <proc_name>([IN/OUT args])
begin
SQL语句
end
调用存储过程
call proc_name(args)
定义变量
set @m = 0;
显示变量
select @m from dual;
dual是系统表,定义的变量都在这个表中
我试了半天,查了半天没解决这个错误,后续看课程评论解决
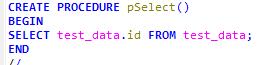


DELIMITER //
create procedure proc_test1(IN a int,IN b int,OUT c int)
begin
set c = a+b;
end //
DELIMITER ;
索引 index

索引介绍
目的是为了提升查找效率。

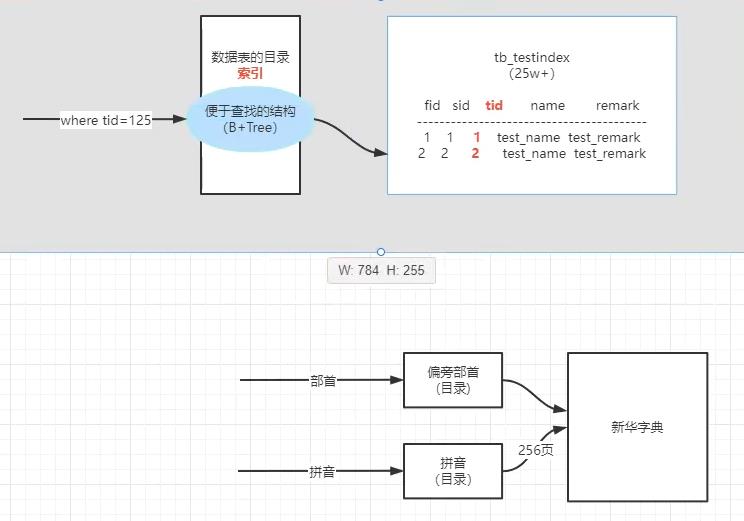
索引分类
MySQL中索引,根据创建索引的列不同,可分为:
- 主键索引
- 唯一索引
- 普通索引
- 组合索引

创建索引
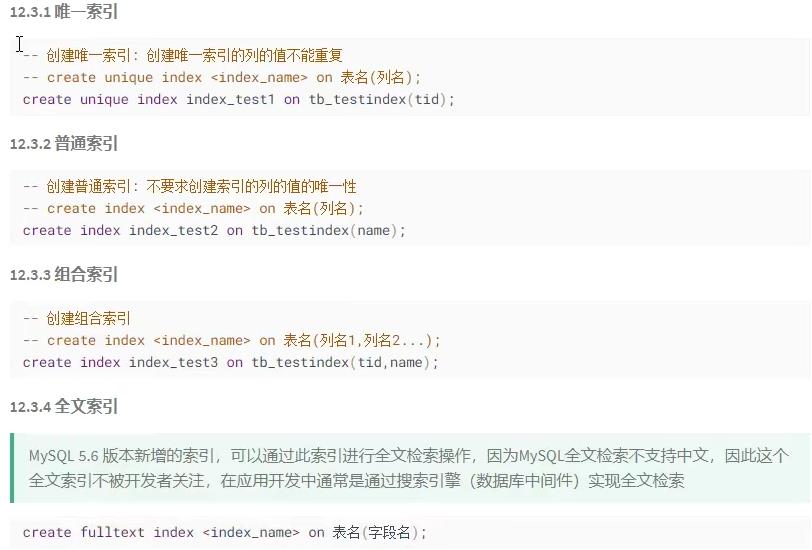
索引使用
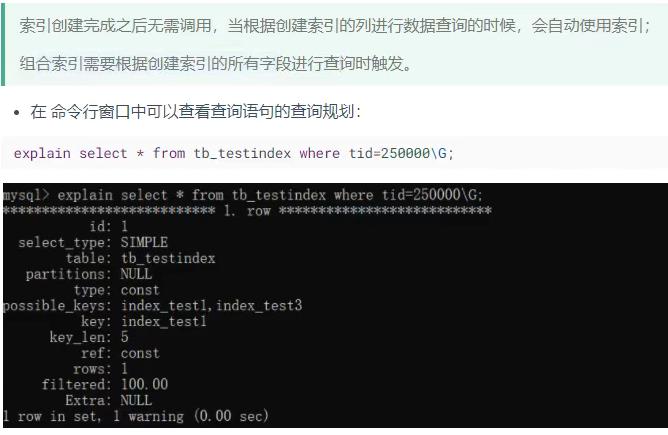

查看索引
命令行查看
show create table Table_Name\\G;
查询数据表索引
SHOW INDEXES FROM Table_Name;
SHOW KEYS FROM Table_Name
删除索引
DROP INDEX Index_Name ON Table_Name
使用总结

事务
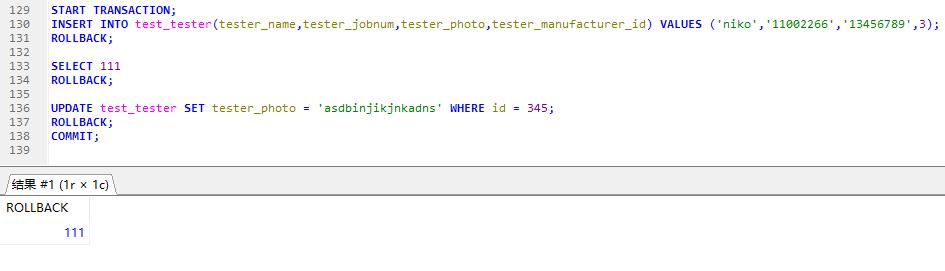
当需要执行多个操作,保证这些操作都完成,拿转账举例,不能这个账户+了1000块钱,另一个账户没有-1000块钱,那肯定不行,所有就有了事务,操作不成功会回滚
我刚刚突发奇想,如果第二次操作失败回滚前,还有其他sql语句修改,那么我感觉会有问题,问同事他跟我说加锁即可。

事务特性
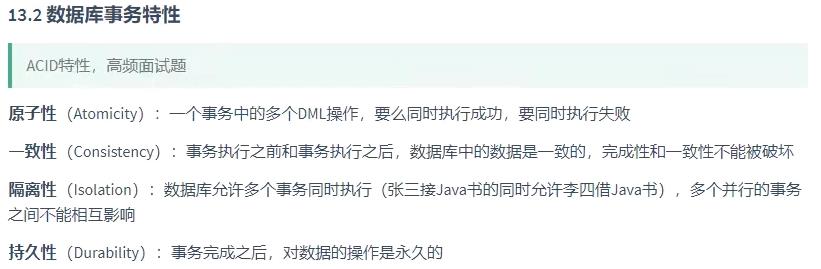
事务管理

事务隔离级别
参考文章
MySQL事务之脏读问题
MySQL脏读、不可重复读、幻读
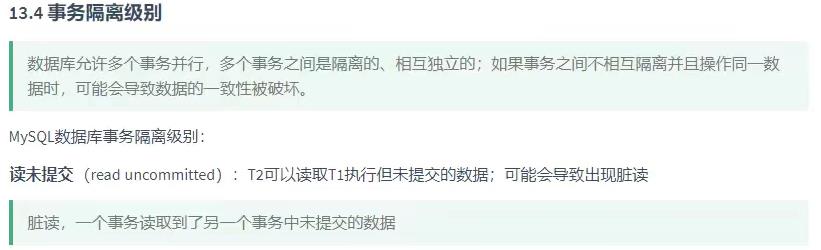
读未提交
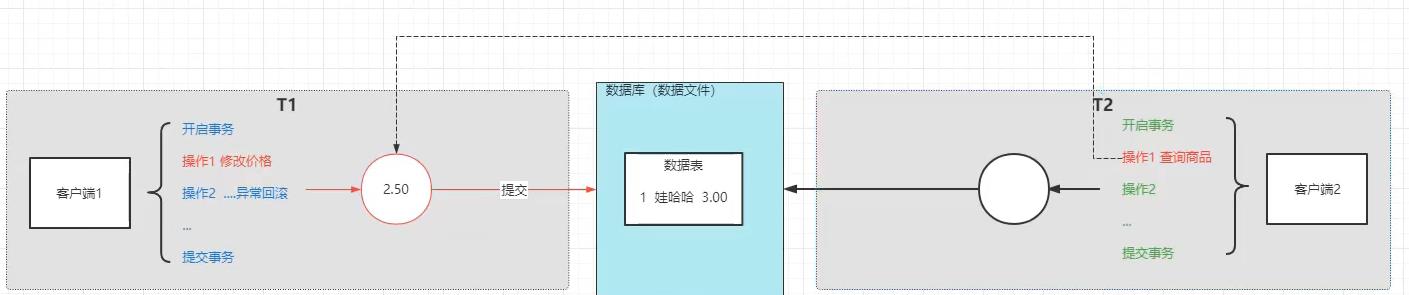
T1事务修改价格,把价格修改成2.5,T2没读数据库的数据文件,读的是T1缓存的2.5,但是T1事务回滚了,实际还是3块钱,T2读的2.5,就造成了数据的不一致性,这就是脏读
脏读:一个事务读取到了另一个事物中未提交的数据
读已提交
T1操作1 在T2操作1与操作2之间执行,T2操作两次读取的数据不一致,就会造成虚读
不可重复读(虚读):在同一个事务中,两次查询操作读取到数据不一致


可重复读
T2执行第一次查询之后,在事物结束之前其他事物不能修改对应的数据:避免了不可重复读(虚读),只是不能修改但可以新增,可能导致幻读。
幻读:T2对数据表中的数据进行修改然后查询,在查询之前T1向数据表中新增了一条数据,就导致T2以为修改了所有数据,但却查询出了与修改不一致的数据
串行化
同时只允许一个事物对数据表进行操作;可以避免所有问题,脏读,虚读,幻读。
总结
| 隔离级别 | 脏读 | 不可重复读(虚读) | 幻读 |
|---|---|---|---|
| read uncommitted | √ | √ | √ |
| read committed | × | √ | √ |
| repeatable read | × | × | √ |
| serializable | × | × | × |
- 我们可以通过设置数据库默认的事物隔离级别来控制事物之间的隔离性;
- 也可以通过客户端与数据库连接设置来设置事务间的隔离性(在应用程序中设置–Spring);
- MySQL数据库默认的隔离级别为可重复读(REPEATABLE-READ)
如何查看数据库隔离级别
在MySQL8.0.3之前
sselect @@tx_isolation;
在MySQL8.0.3之后
SELECT @@TRANSACTION_isolation;
设置MySQL默认隔离级别
格式:SET SESSION TRANSACTION ISOLATION LEVEL 等级
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
数据库设计

数据库设计流程

以上是关于MySQL 笔记的主要内容,如果未能解决你的问题,请参考以下文章