mysql数据库,排序的语句
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql数据库,排序的语句相关的知识,希望对你有一定的参考价值。
有一个mysql表名是student,字段有:sid,sname,sage,sclass,sscore,
要求按照分数(sscore)的高低输学生的名字和班级?
具体如下:
1、第一步,创建一个测试表,代码如下,见下图,转到下面的步骤。
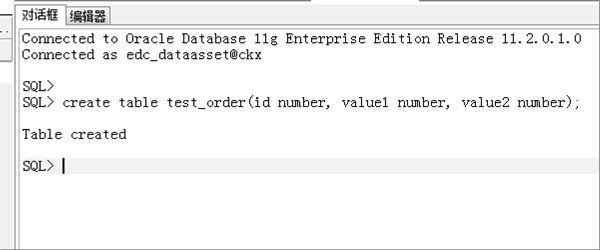
2、第二步,完成上述步骤后,插入测试的数据,代码如下,见下图,转到下面的步骤。

3、第三步,完成上述步骤后,查询表中所有记录的数量,代码如下,见下图,转到下面的步骤。

4、第四步,完成上述步骤后,按照value1字段的升序,按value2字段的降序编写sql,代码如下,见下图。这样,就解决了这个问题了。
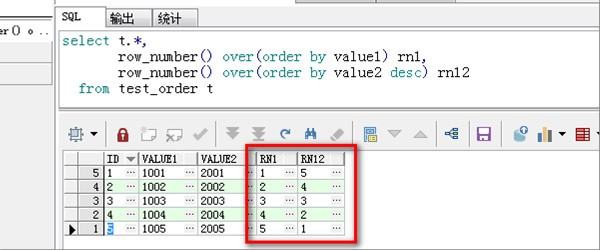
在执行查询结果时,默认情况下查询结果无序排列。但我们有时需要对数据按一定规则进行排序。这时可以通过ORDER BY子句来实现这个功能。语法如下:
SELECT <*,column [alias],...> FROM table
[WHERE condition(s)]
[ORDER BY column[ASC|DESC]];
默认是ASC指定的升序排列,DESC用来指定降序排列。
1、升序排序:
使用ORDER BY子句时,默认情况下数据是按升序排列的,故可以用ASC关键字指点升序排列,或者不指定,默认就是升序,显示效果是一样的,如下图:
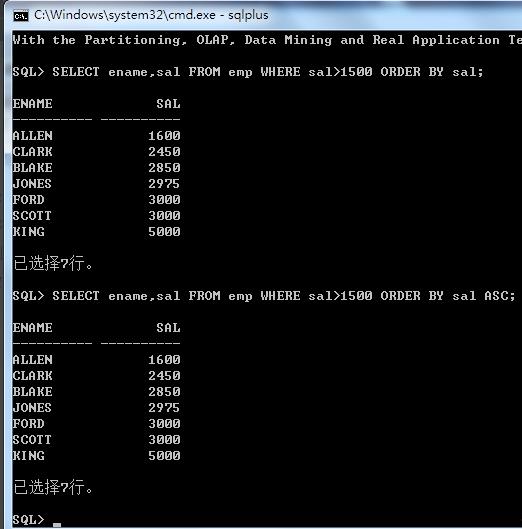
2、降序排序:
当需要查询结果降序排列时,必须在排序后指定DESC关键字。如下图是查看职员薪水的降序排列:

举例说明:
1.查询所有学生记录,按年龄升序排序
SELECT *
FROM stu
ORDER BY sage ASC;
2.查询所有学生记录,按年龄降序排序
SELECT *
FROM stu
ORDER BY age DESC;
3.查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序
SELECT * FROM emp
ORDER BY sal DESC,empno ASC;
参考技术C select sname,sclass from student order by sscore desc本回答被提问者采纳 参考技术D select sclass,sname ,sscore from student order by sscore descMySQL高级SQL语句
引言
对MySQL数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。
一、常用查询
(增、删、改、查)
1.按关键字查询
使用select语句可以将需要的数据从MySQL数据库中查询出来,如果对查询的结果进行排序,可以使用order by 语句来对语句实现排序,并最终将排序后的结果返回给用户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段
select 字段1,字段2... from 表名 order by 字段1,字段2... asc #查询结果以升序方式显示,asc可以省略
select 字段1,字段2... from 表名 order by 字段1,字段2,... desc #查询结果以降序方式显示
- ASC是按照升序进行排序,是默认的排序方式,即ASC可以省略。
- SELECT语句中如果没有指定具体的排序方式,则默认按ASC方式进行排序。
- DESC是按照降序方式进行排列。当然order by前面也可以使用where子句对查询结果进一步过滤。
1.1升序排序
select id,name,score from class1 order by score asc;
#查询id,name,goal字段的记录,并且以goal进行升序排列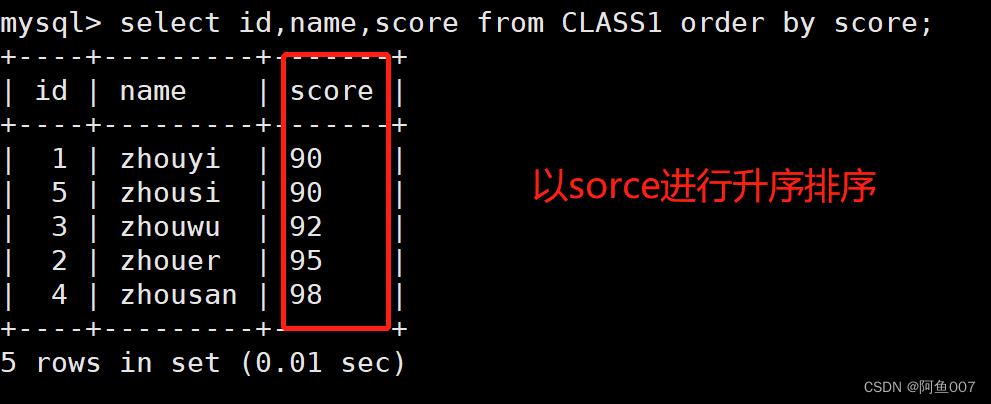
1.2降序排序

1.3结合where进行条件过滤
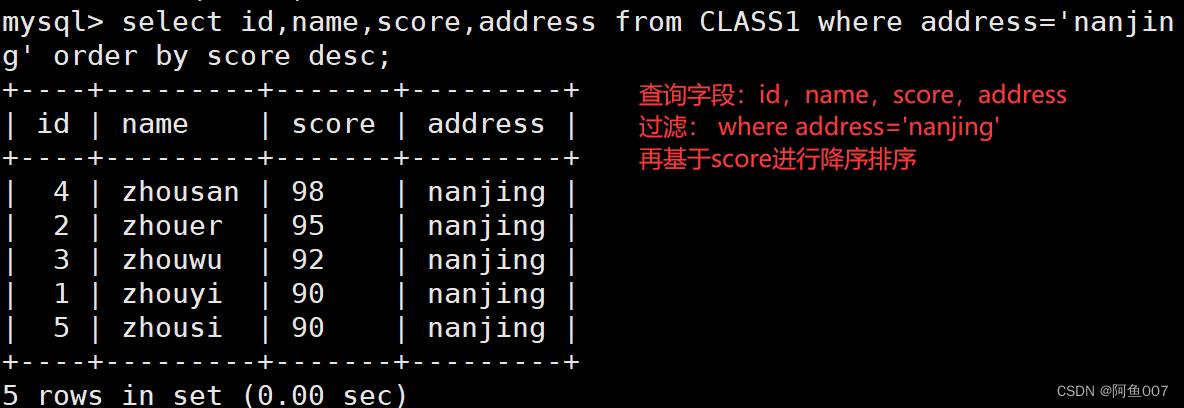
1.4多字段排序
ORDER BY 语句也可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,order by 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定,但order by之后的第一个参数只有在出现相同值时,第二个字段才有意义
select id,name,score,hobbid from CLASS1 order by hobby,score desc;
#查询id,name,score,hobbid字段,先按照hobbid进行升序,如果出现相同的hobbid,就按照score进行降序排列

2.and和or判断
大型数据库中,有时查询数据需要数据符合某些特点,“and"和"or"表示"且"和"或”
2.1and和or的使用
select * from info where score >90 and score <=98;
#查找score大于90和小于等于98的字段

select * from info where score93 > or score <=90;
#查找score大于93或者小于等于90
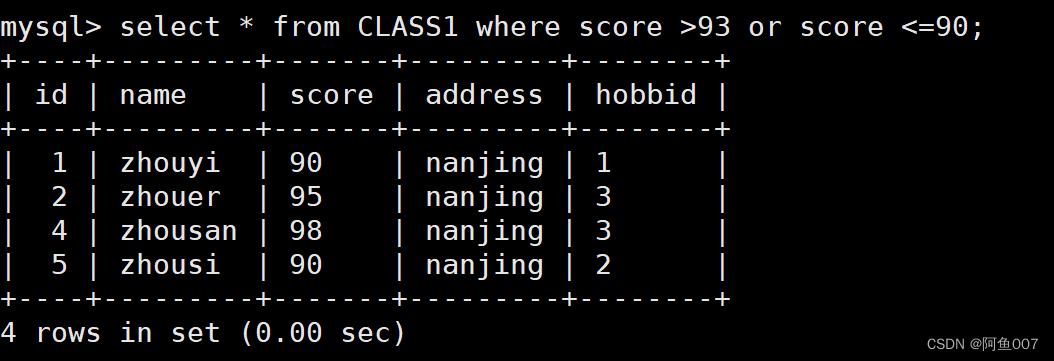
2.2嵌套、多条件使用
select * from CLASS1 where score >90 and (score >90 and score <98);
#查找score大于90且在90和98之间的数据

select * from CLASS1 where score >90 and (score >90 and score <98) order by score asc
#查找score大于90且在90和98之间的数据并进行升序排序

3.distinct 查询不重复记录
语法:
select distinct 字段 from 表名;
#distinct必须放在最开头
#distinct只能使用需要去重的字段进行操作
#distinct去重多个字段时,含义是:几个字段同时重复时才能会过滤,会默认按左边第一个字段为依据
select distinct hobbid from CLASS1;
#使用distinct查询不重复记录(相当于去重)

4.group by 对结果进行分组
通过SQL查询出来的结果,还可以对其进行分组,使用group by 语句来实现,group by 通常都是结合聚合函数一起使用的
常用的聚合函数包括:计数(count)、求和(sum)、求平均数(avg)、最大值(max)、最小值(min),group by 分组的时候可以按一个或多个字段对结果进行分组处理。
- 对于group by 后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
- group by 有一个原则,就是select后面的所有列中,没有聚合函数的列必须出现在group by后面
语法:
select 字段,聚合函数(字段) from 表名【where 字段 (匹配) 数值】group by 字段名;
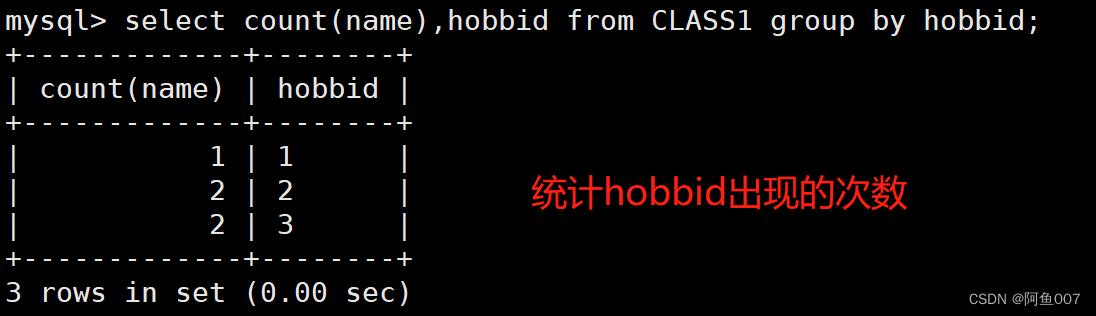
select count(name),hobbid from CLASS1 group by hobbid;
#按hobbid相同的分株,基于name个数进行计数
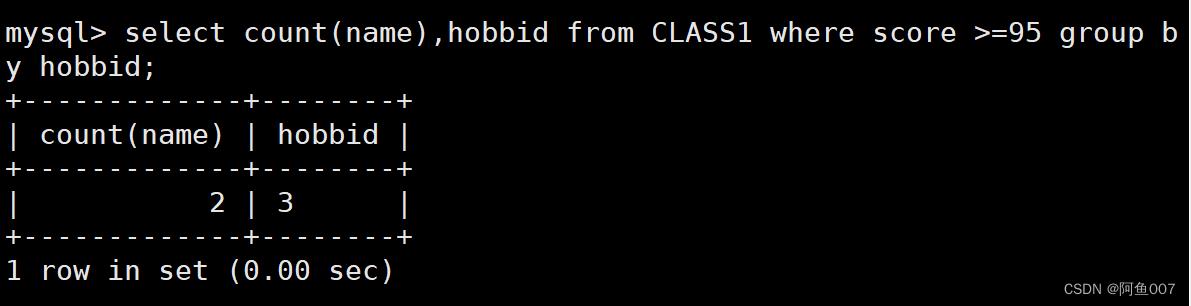
select count(name),hobbid from info where score >=95 group by hobbid;
#筛选score大于等于95的分组,计算个数
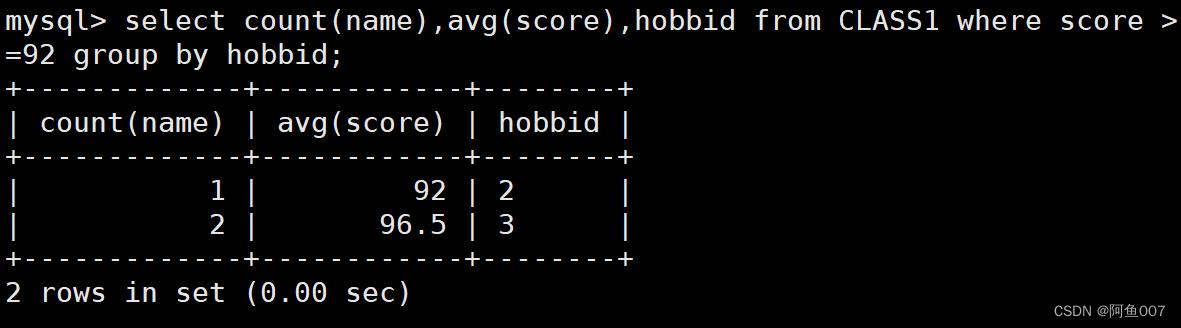
select count(name),avg(score),hobbid from CLASS1 where score >=92 group by hobbid;
#以hobbid进行分组查询,显示score的平均数,hobbid为3的两人平均数
5.limit限制结果条目
limit限制输出的结果
在使用MySQL select 语句进行查询时,结果集返回的时所有匹配的记录(行)。有时候仅需要返回第一行或者前几行,这时候就需要用到limit子句
语法:
select column1,column2,... from table_name limit [offset] number
#limit的第一个参数是位置偏移量(可选参数),设置mysql从哪一行开始显示。
#如果不设定第一个参数,将会从表中的第一条记录开始显示。需要注意的是,第一条记录的位置偏移量是0,第二条是1
#offset:为索引下标
#number:为索引下标后的几位
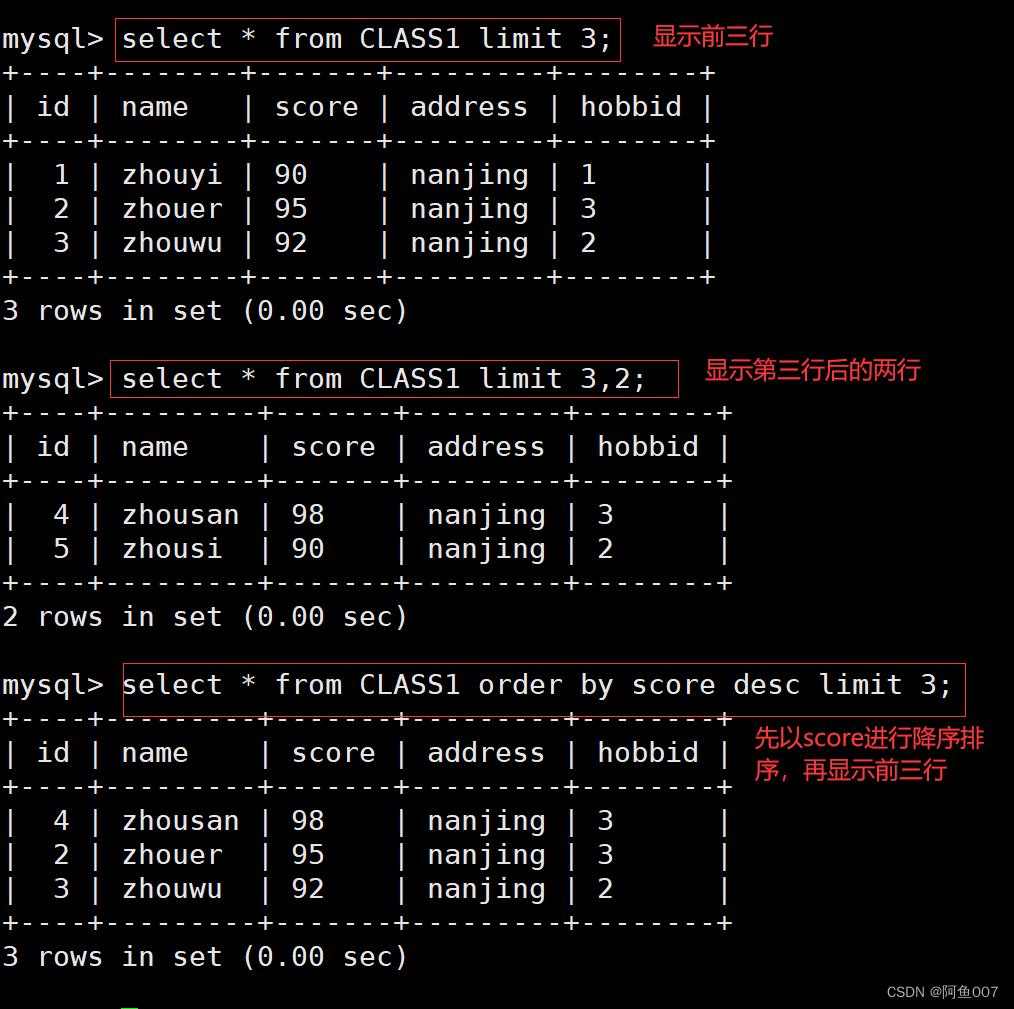
select * from CLASS1 limit 3;
#显示前三行数据内容
select * from CLASS1 limit 3,2;
#显示从第3行开始后面的2行内容(不包括第三行)
select * from CLASS1 order by score desc limit 3;
#嫌疑score进行降序排序,再显示前三行
6.设置别名(alise -as)
再MySQL查询时,当表的名字比较长或者表内某些字段比较长时,为了方便书写或者多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,方便操作,增强可读性
格式:
列的别名:select 字段 as 字段别名 表名;
表的别名:select 别名.字段 from 表名 as 别名;
as可以省略
使用场景
- 对复杂的表进行查询时,别名可以缩短查询语句的长度
- 多表相连查询的时候(通俗易懂,简短sql语句)
注意:在为表设置别名时,要保证别名不能与数据库中其他表的名称冲突
select address as 地区 from CLASS1;
#将address字段设置别名为"地区"显示

6.1查询表的记录的数量,以别名显示
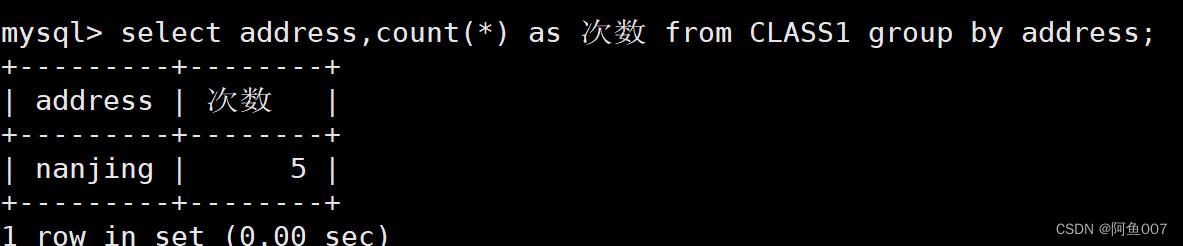
select address,count(*) as 次数 from CLASS1 group by address;
#以address分组,查询表数据内容,以别名"次数"显示
6.2利用as,将查询的数据导入到另一个表内
此处as起到的作用
- 创建了一个新表,并定义表结构,插入表数据
- 但是"约束"没有完全复制过来,但是如果原表设置了主键,那么附表的:default字段会默认设置了一个0
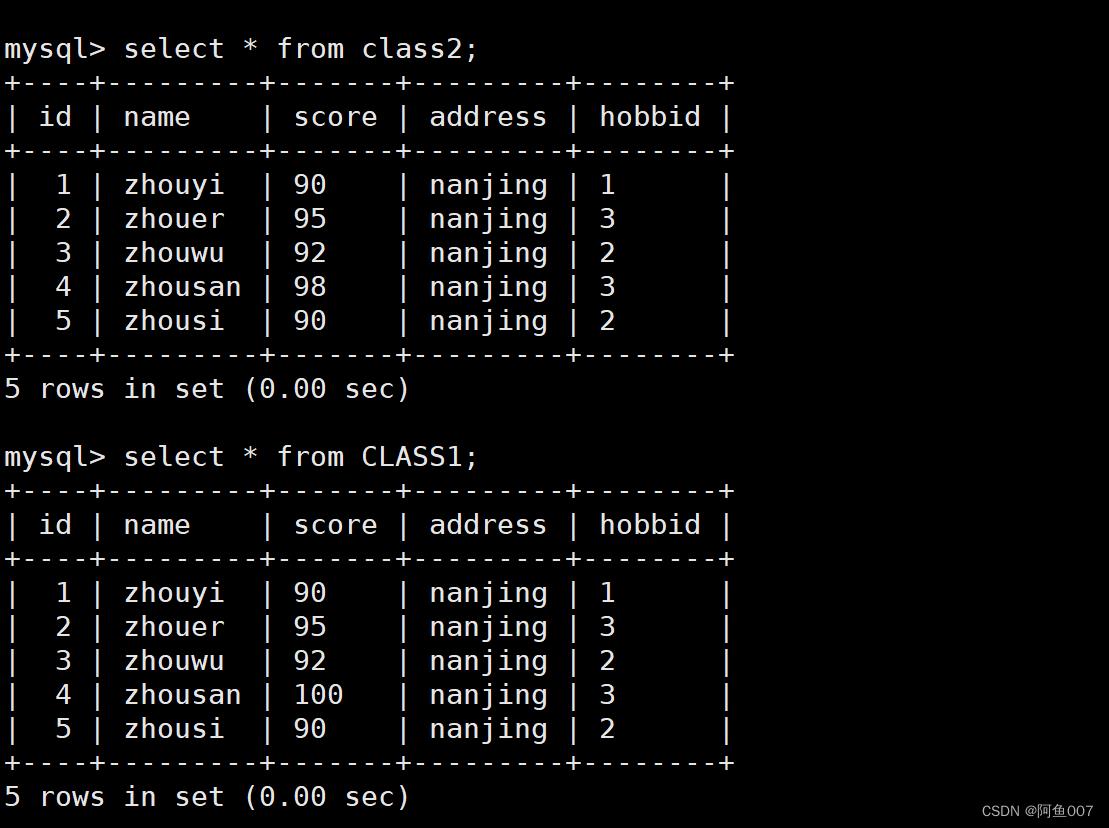
create table class2 as select * from CLASS1;
#将表info的内容导入到class1中
select * from CLASS1;
select * from class2;


7.通配符
- 通配符主要用于替换字符串的部分字符,通过部分字符的匹配将相关结构查询出来
- 通常通配符都是跟like一起使用的,并协同where
- 子句共同来完成查询任务,常用的通配符有两个,分别是:“%“和”_”
%:百分号表hi0个、1个或多个字符
_:下划线表示单个字符
select * from CLASS1 where name like 'z%';
#查询name以z开头的记录
select * from CLASS1 where name like 'z__u%';
#查询名称以x开头,z u之间两个任意字符,__代表两个字符
select * from CLASS1 where name like '%e%';
#查询name包含字符e的数据
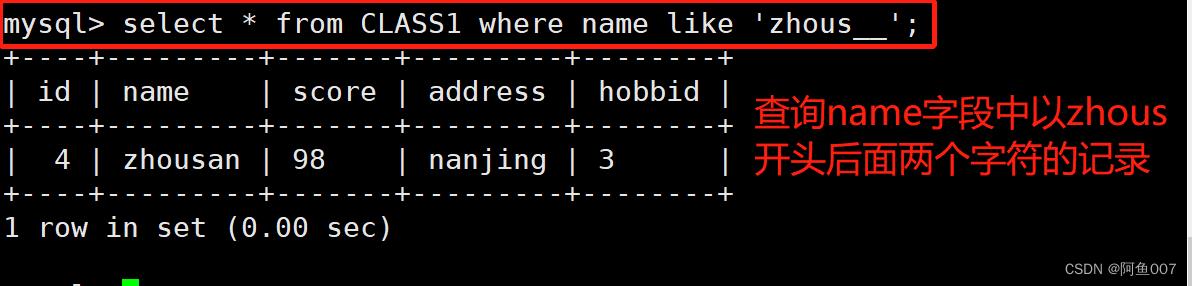
select * from CLASS1 where name like 'zhous__';
#查询zhous后面带2个字符的名字记录



二、子查询
- 子查询也被称作内查询(内连)或嵌套查询,是指在一个查询语句里面还嵌套这另一个查询语句
- 子查询语句是先于著查询语句被执行,且结果作为外层的条件返回给主查询进行下一步的查询
- 在查询中可以与主语句相同的表,也可以是不同的表
1.select 查询
子语句可以与主语句所查询的表相同,也可以是不同的表
语法:
select 字段1,字段2 from 表名1 where 字段 in (select 字段 from 表名 where 条件);
#主语句:select 字段1,字段2 from 表名1 where 字段;
#in:将主表和子表关联/连接的语法
#子语句(集合):select 字段 from 表名 where 条件;
1.1相同表查询
select name,score from CLASS1 where id in (select id from CLASS1 where score > 95);
#先查询子语句中info表中的分数大于95的id,然后得出的id的集合作为主语句的条件

1.2多表查询
select name,score from CLASS1 where id in (select id from class2 where score <95);
#查询class2表中分数低于95的id,然后得出的id的集合作为查询CLASS1表的查询条件

1.3not取反,将子查询的结果,进行取反操作
select name,score from CLASS1 where id not in (select id from class2 where score <95);
#查询class2表中分数低于95的id,然后得出的id的集合取反作为查询CLASS1表的查询条件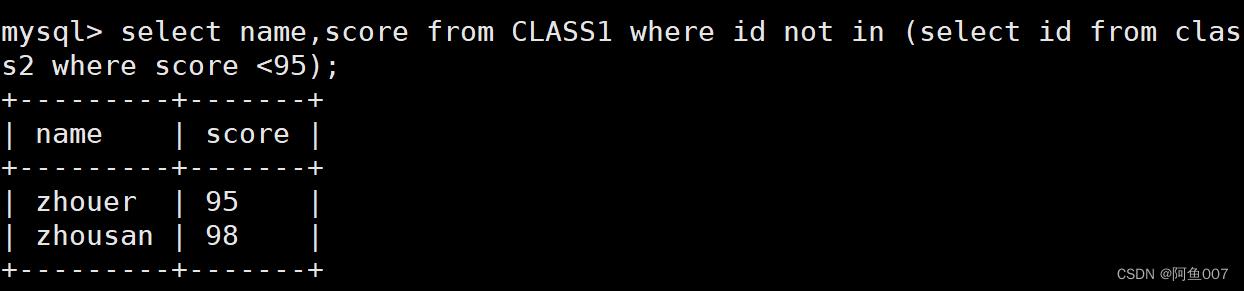
1.4结合as别名进行子查询
当我们将一个查询的结果集作为一个新表再进行查询时,直接使用会进行报错,我们需要是用到别名
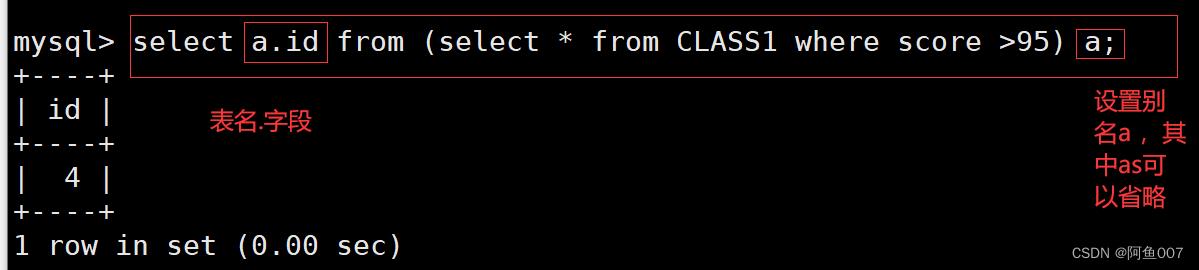
如果直接使用select id from (select id,name from info);此时会报错,因为select * from表名,此格式为标准格式,而以上的查询的语句,"表名"的位置其实是一个完整结果集,mysql并不能直接识别,而此时给与结果集设置一个别名
所以可以使用select a.id from (select id,name from CLASS1) a;
select id from (select * from CLASS1);
#此条报错
select id from (select * from CLASS1) a;
#设置了别名,然后再作为表
select a.id from (select * from CLASS1 where score >95) a;
#将查询结果设置别名,然后将结果集作为表进行查询

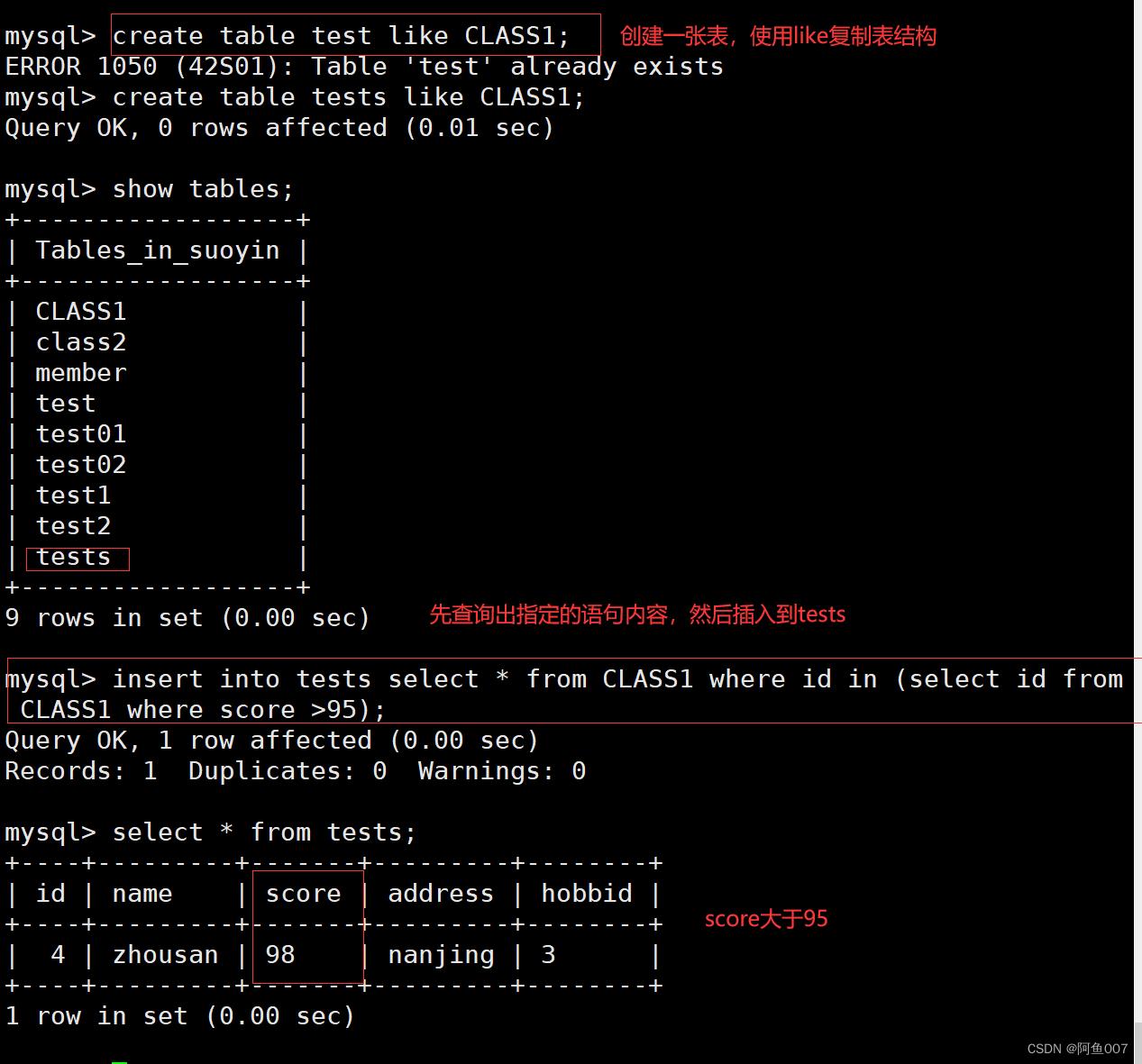
2.insert插入
子查询还可以用在insert语句中,子查询的结果集可以通过insert语句插入到其他表中
3.update 修改
update语句也可以使用子查询,uodate内的子查询,在set更新内容时,可是单独一列,也可以是多列


4.delete 删除
#操作不同的表
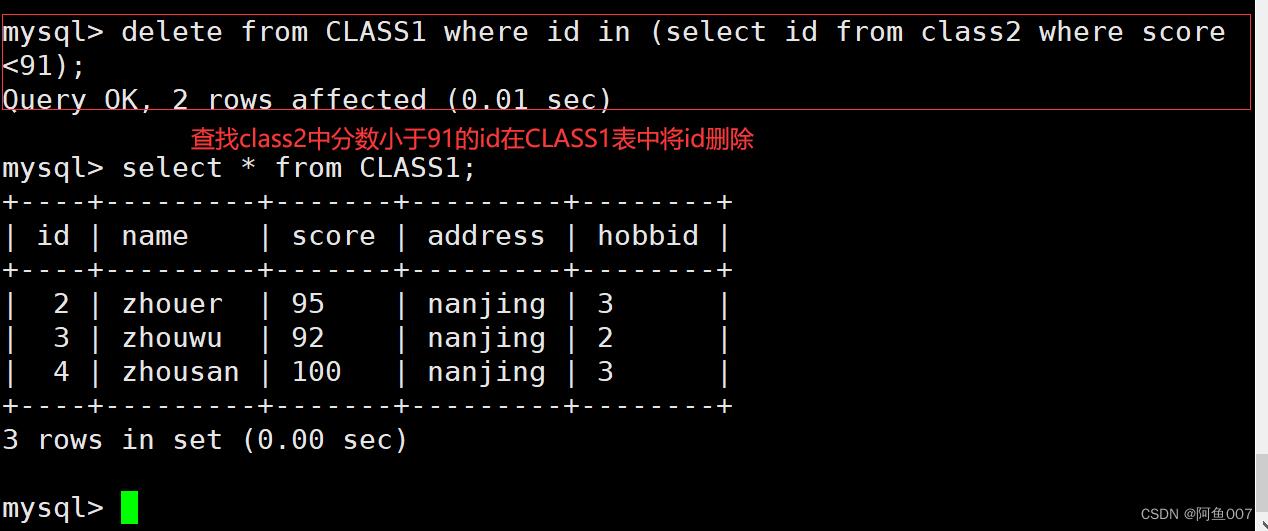
delete from CLASS1 where id in (select id from class2 where score <91);
#查询info1表中分数小于91的id,作为info表中删除的对象id
#操作相同的表
delete from CLASS1 where id in (select id where score <94);
#查询info表中分数小于94的id,然后删除对应的id
5.exists布尔输出
exists关键字在子查询时,主要用于判断子查询的结果集是否为空,如果不为空,则返回true,反之返回false
注意:在使用exists时,当子查询有结果时,不关心子查询的结果,执行主查询操作时,当子查询没有结果时,则不执行主查询操作,子查询只是作为布尔值的输出
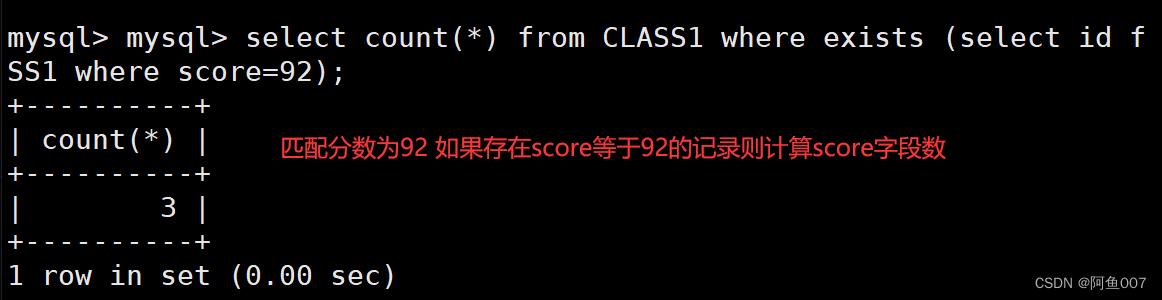
select count(*) from CLASS1 where exists (select id from CLASS1 where score=90);
#子语句执行失败,输出为false,那么主语句不会进行执行,默认输出0
select count(*) from CLASS1 where exists (select id from CLASS1 where score=100);
#子语句执行成功,输出为true,那么主语句会执行,输出内容

三、MySQL视图
1.什么是视图?
视图:优化操作+安全方案
数据库中的虚拟表,这张虚拟表不包含真实数据。只是做了真实数据的映射
视图可以理解为镜花水月/倒影。动态保存结果集(数据)
作用场景:针对不同的人(不同权限),提供不同的结果集的"表"(以表格的形式展示)
功能
- 简化查询结果集,灵活查询,可以针对不同用户呈现不同的结果集,相对有更高的安全性
- 本质而言,视图是另一种select(结果集的呈现)
注意
- 视图适合于多表连接浏览时使用,不适合增、删、改
- 而存储过程适合于私用比较频繁的sql语句,这样可以提高执行效率
2.视图和表的区别与联系
区别
视图是已编译好的sql语句,而表不是
视图没有实际的物理空间,而表有
表是只用物理空间,而视图不占物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,mysql5.7通过更改视图也可以直接更改表数据
视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些sql语句的集合。从安全角度来说,视图可以不给用户接触数据表,从而不知道结构
表属于全局模式中的表,是实表,视图属于局部模式的表,是虚表
联系
- 视图是在基本表之上建立的表,它的结构(所定义的列)和内容(即所有的数据行)都来自基本表,它依据基本表存在而存在。一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和在逻辑意义上建立的新关系
3.单表创建视图
格式:
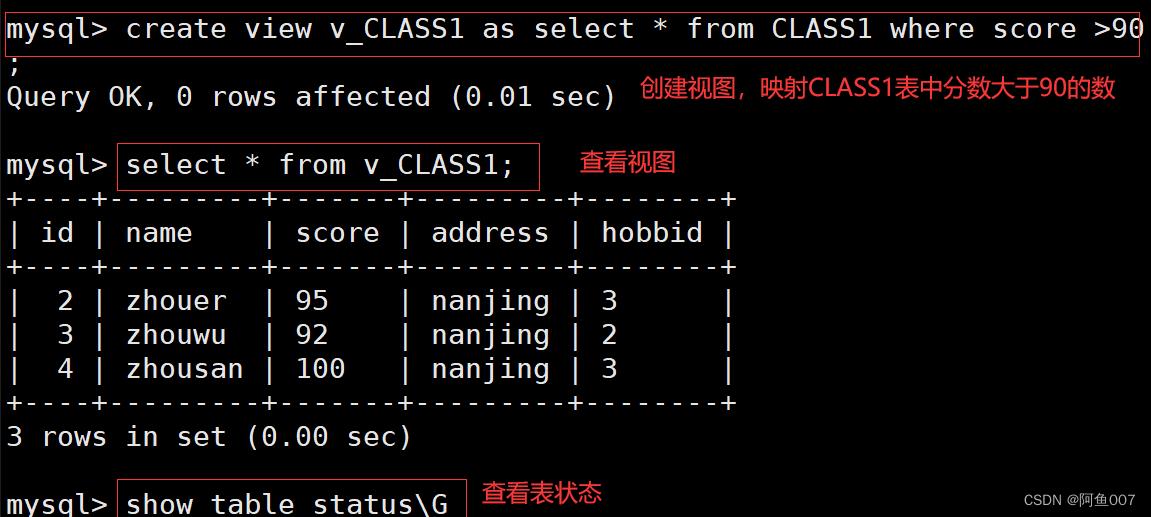
create view 视图表名 as select * from 表名 where 条件;
create view v_CLASS1 as select * from CLASS1 where score >90;
#创建一个视图,视图内容为CLASS1表中分数大于90的记录(动态监控主表)
select * from v_CLASS1;
#查看视图表
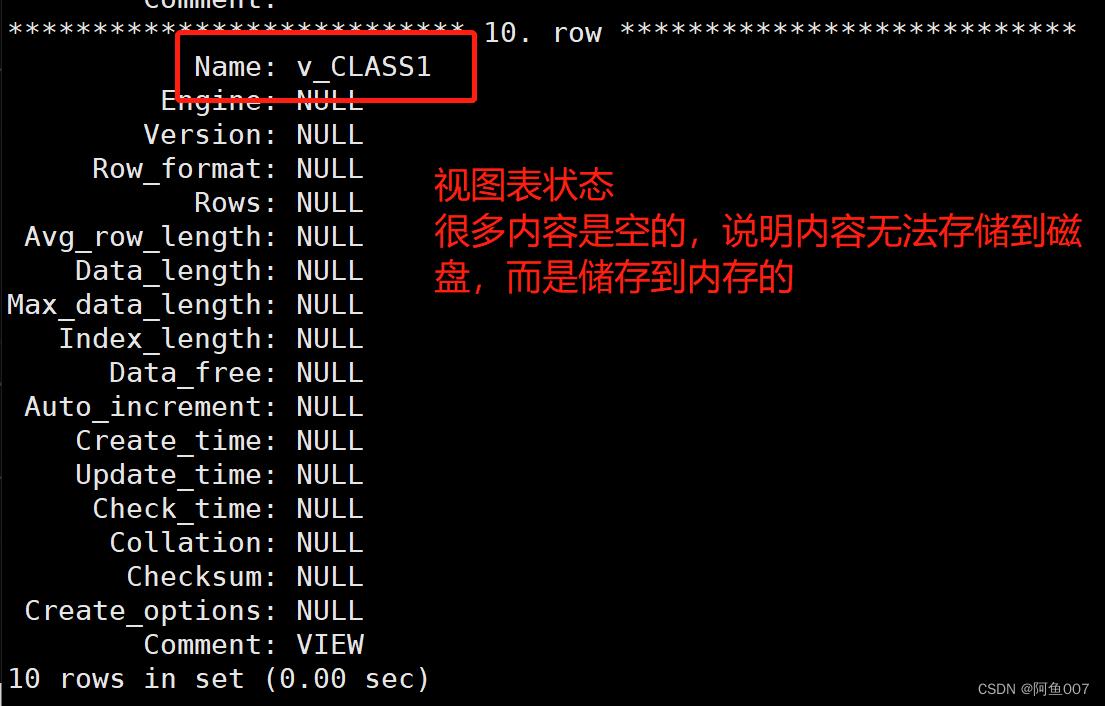
show table status\\G
#查看表状态
desc v_CLASS1;
#查看表结构
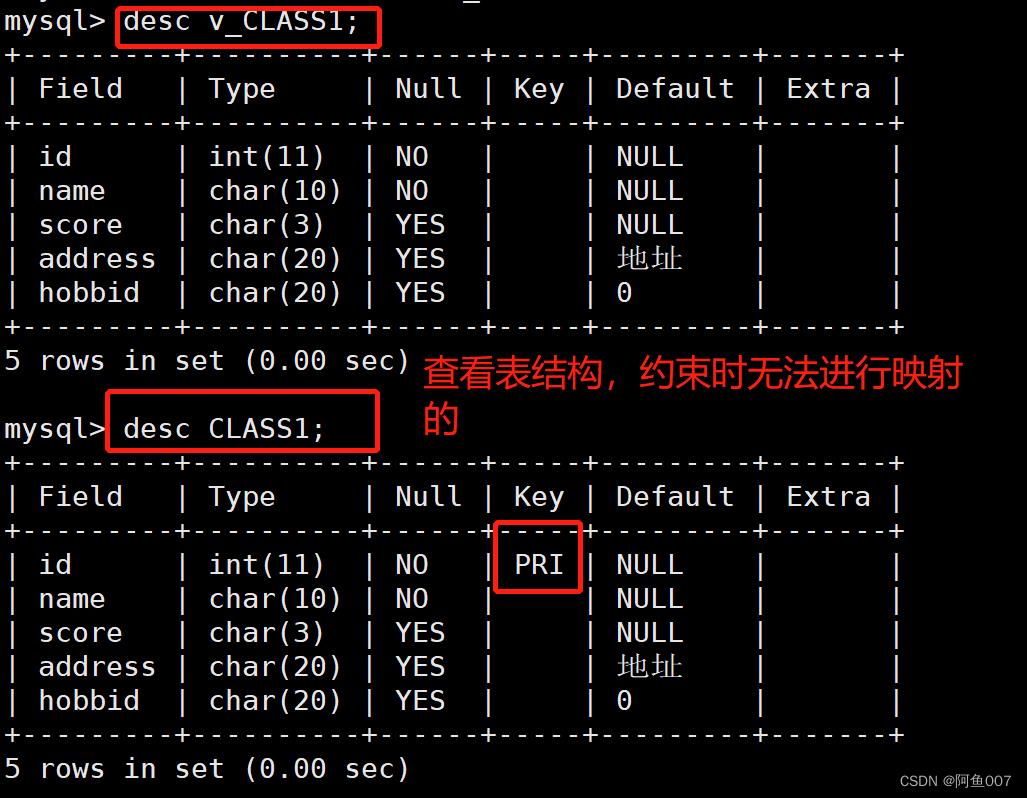
4.多表创建视图
现在有两个表,需要频繁查看其中的数据,那就可以使用视图的方式将要看的内容生成一个视图,要查看时,直接查看视图内容即可
create view v_CLASS11(id,name,score,address) as select CLASS1.id,CLASS1.name,class2.address,CLASS1.score from CLASS1,class2 where CLASS1.name=class2.name;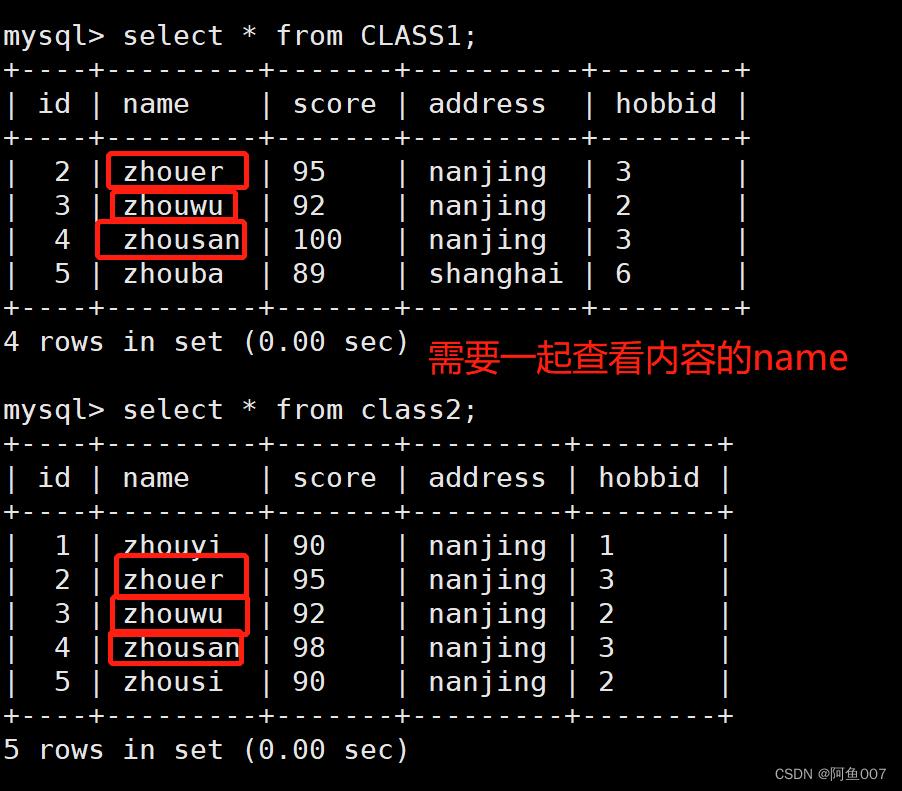
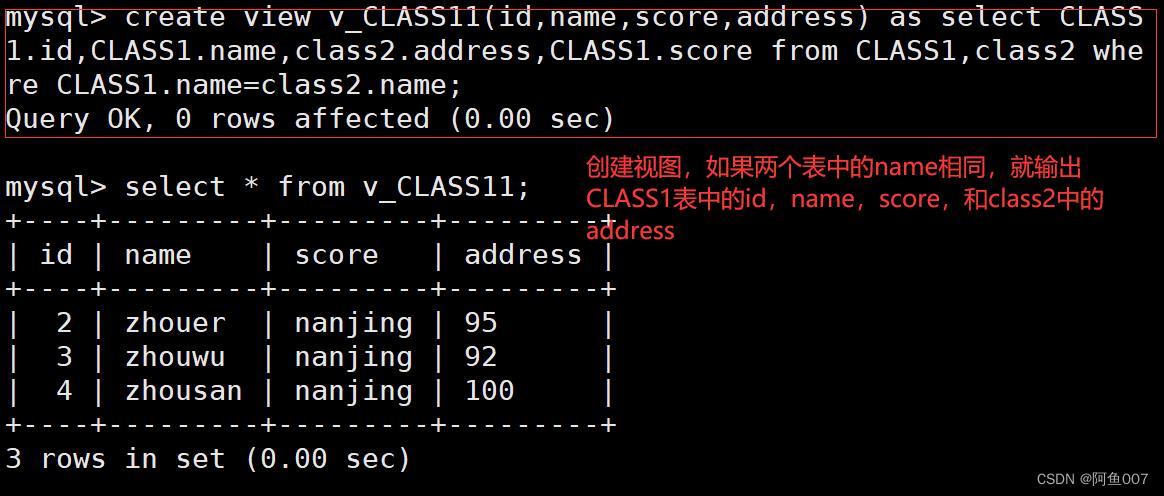
5.修改视图或原表内容
5.1修改原表的内容
以上是关于mysql数据库,排序的语句的主要内容,如果未能解决你的问题,请参考以下文章