Spark学习笔记——读写MySQL
Posted tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark学习笔记——读写MySQL相关的知识,希望对你有一定的参考价值。
1.使用Spark读取MySQL中某个表中的信息
build.sbt文件
name := "spark-hbase" version := "1.0" scalaVersion := "2.11.8" libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % "2.1.0", "mysql" % "mysql-connector-java" % "5.1.31", "org.apache.spark" %% "spark-sql" % "2.1.0" )
Mysql.scala文件
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{SQLContext, SaveMode}
import java.util.Properties
/**
* Created by mi on 17-4-11.
*/
case class resultset(name: String,
info: String,
summary: String)
object MysqlOpt {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
//定义数据库和表信息
val url = "jdbc:mysql://localhost:3306/baidubaike?useUnicode=true&characterEncoding=UTF-8"
val table = "baike_pages"
//读MySQL的方法1
val reader = sqlContext.read.format("jdbc")
reader.option("url", url)
reader.option("dbtable", table)
reader.option("driver", "com.mysql.jdbc.Driver")
reader.option("user", "root")
reader.option("password", "XXX")
val df = reader.load()
df.show()
//读MySQL的方法2
// val jdbcDF = sqlContext.read.format("jdbc").options(
// Map("url"->"jdbc:mysql://localhost:3306/baidubaike?useUnicode=true&characterEncoding=UTF-8",
// "dbtable"->"(select name,info,summary from baike_pages) as some_alias",
// "driver"->"com.mysql.jdbc.Driver",
// "user"-> "root",
// //"partitionColumn"->"day_id",
// "lowerBound"->"0",
// "upperBound"-> "1000",
// //"numPartitions"->"2",
// "fetchSize"->"100",
// "password"->"XXX")).load()
// jdbcDF.show()
}
}
输出
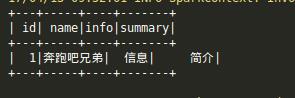
2.使用Spark写MySQL中某个表中的信息
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{SQLContext, SaveMode}
import java.util.Properties
/**
* Created by mi on 17-4-11.
*/
case class resultset(name: String,
info: String,
summary: String)
object MysqlOpt {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
//定义数据库和表信息
val url = "jdbc:mysql://localhost:3306/baidubaike?useUnicode=true&characterEncoding=UTF-8"
val table = "baike_pages"
//写MySQL的方法1
val list = List(
resultset("名字1", "标题1", "简介1"),
resultset("名字2", "标题2", "简介2"),
resultset("名字3", "标题3", "简介3"),
resultset("名字4", "标题4", "简介4")
)
val jdbcDF = sqlContext.createDataFrame(list)
jdbcDF.collect().take(20).foreach(println)
// jdbcDF.rdd.saveAsTextFile("/home/mi/coding/coding/Scala/spark-hbase/output")
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "123456")
//jdbcDF.write.mode(SaveMode.Overwrite).jdbc(url,"baike_pages",prop)
jdbcDF.write.mode(SaveMode.Append).jdbc(url, "baike_pages", prop)
}
}
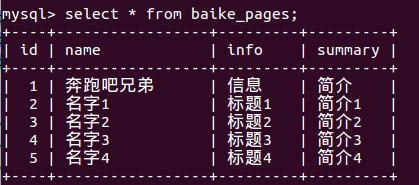
以上是关于Spark学习笔记——读写MySQL的主要内容,如果未能解决你的问题,请参考以下文章
Spark基础学习笔记27:Spark SQL数据源 - Hive表
spring学习笔记(19)mysql读写分离后端AOP控制实例