Spark学习笔记——数据读取和保存
Posted tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark学习笔记——数据读取和保存相关的知识,希望对你有一定的参考价值。
spark所支持的文件格式

1.文本文件
在 Spark 中读写文本文件很容易。
当我们将一个文本文件读取为 RDD 时,输入的每一行 都会成为 RDD 的 一个元素。
也可以将多个完整的文本文件一次性读取为一个 pair RDD, 其中键是文件名,值是文件内容。
在 Scala 中读取一个文本文件
val inputFile = "file:///home/common/coding/coding/Scala/word-count/test.segmented" val textFile = sc.textFile(inputFile)
在 Scala 中读取给定目录中的所有文件
val input = sc.wholeTextFiles("file:///home/common/coding/coding/Scala/word-count")
保存文本文件,Spark 将传入的路径作为目录对待,会在那个目录下输出多个文件
textFile.saveAsTextFile("file:///home/common/coding/coding/Scala/word-count/writeback")
//textFile.repartition(1).saveAsTextFile 就能保存成一个文件
对于dataFrame文件,先使用.toJavaRDD 转换成RDD,然后再使用 coalesce(1).saveAsTextFile
2.JSON
JSON 是一种使用较广的半结构化数据格式。
读取JSON,书中代码有问题所以找了另外的一段读取JSON的代码
build.sbt
"org.json4s" %% "json4s-jackson" % "3.2.11"
代码
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.json4s._
import org.json4s.jackson.JsonMethods._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.{read, write}
/**
* Created by common on 17-4-3.
*/
case class Person(firstName: String, lastName: String, address: List[Address]) {
override def toString = s"Person(firstName=$firstName, lastName=$lastName, address=$address)"
}
case class Address(line1: String, city: String, state: String, zip: String) {
override def toString = s"Address(line1=$line1, city=$city, state=$state, zip=$zip)"
}
object WordCount {
def main(args: Array[String]) {
val inputJsonFile = "file:///home/common/coding/coding/Scala/word-count/test.json"
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val input5 = sc.textFile(inputJsonFile)
val dataObjsRDD = input5.map { myrecord =>
implicit val formats = DefaultFormats
// Workaround as DefaultFormats is not serializable
val jsonObj = parse(myrecord)
//val addresses = jsonObj \\ "address"
//println((addresses(0) \\ "city").extract[String])
jsonObj.extract[Person]
}
dataObjsRDD.saveAsTextFile("file:///home/common/coding/coding/Scala/word-count/test1.json")
}
}
读取的JSON文件
{"firstName":"John","lastName":"Smith","address":[{"line1":"1 main street","city":"San Francisco","state":"CA","zip":"94101"},{"line1":"1 main street","city":"sunnyvale","state":"CA","zip":"94000"}]}
{"firstName":"Tim","lastName":"Williams","address":[{"line1":"1 main street","city":"Mountain View","state":"CA","zip":"94300"},{"line1":"1 main street","city":"San Jose","state":"CA","zip":"92000"}]}
输出的文件
Person(firstName=John, lastName=Smith, address=List(Address(line1=1 main street, city=San Francisco, state=CA, zip=94101), Address(line1=1 main street, city=sunnyvale, state=CA, zip=94000))) Person(firstName=Tim, lastName=Williams, address=List(Address(line1=1 main street, city=Mountain View, state=CA, zip=94300), Address(line1=1 main street, city=San Jose, state=CA, zip=92000)))
3.逗号分割值与制表符分隔值
逗号分隔值(CSV)文件每行都有固定数目的字段,字段间用逗号隔开(在制表符分隔值文件,即 TSV 文 件中用制表符隔开)。
如果恰好CSV 的所有数据字段均没有包含换行符,你也可以使用 textFile() 读取并解析数据,
build.sbt
"au.com.bytecode" % "opencsv" % "2.4"
3.1 读取CSV文件
import java.io.StringReader
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.json4s._
import org.json4s.jackson.JsonMethods._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.{read, write}
import au.com.bytecode.opencsv.CSVReader
/**
* Created by common on 17-4-3.
*/
object WordCount {
def main(args: Array[String]) {
val input = sc.textFile("/home/common/coding/coding/Scala/word-count/sample_map.csv")
val result6 = input.map{ line =>
val reader = new CSVReader(new StringReader(line));
reader.readNext();
}
for(result <- result6){
for(re <- result){
println(re)
}
}
}
}
CSV文件内容
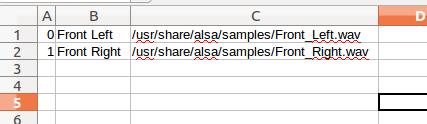
输出
0 Front Left /usr/share/alsa/samples/Front_Left.wav 1 Front Right /usr/share/alsa/samples/Front_Right.wav
如果在字段中嵌有换行符,就需要完整读入每个文件,然后解析各段。如果每个文件都很大,读取和解析的过程可能会很不幸地成为性能瓶颈。
代码
import java.io.StringReader
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.json4s._
import org.json4s.jackson.JsonMethods._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.{read, write}
import scala.collection.JavaConversions._
import au.com.bytecode.opencsv.CSVReader
/**
* Created by common on 17-4-3.
*/
case class Data(index: String, title: String, content: String)
object WordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val input = sc.wholeTextFiles("/home/common/coding/coding/Scala/word-count/sample_map.csv")
val result = input.flatMap { case (_, txt) =>
val reader = new CSVReader(new StringReader(txt));
reader.readAll().map(x => Data(x(0), x(1), x(2)))
}
for(res <- result){
println(res)
}
}
}
输出
Data(0,Front Left,/usr/share/alsa/samples/Front_Left.wav) Data(1,Front Right,/usr/share/alsa/samples/Front_Right.wav)
或者
import java.io.StringReader
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.json4s._
import org.json4s.jackson.JsonMethods._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.{read, write}
import scala.collection.JavaConversions._
import au.com.bytecode.opencsv.CSVReader
/**
* Created by common on 17-4-3.
*/
case class Data(index: String, title: String, content: String)
object WordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val input = sc.wholeTextFiles("/home/common/coding/coding/Scala/word-count/sample_map.csv")
//wholeTextFiles读出来是一个RDD(String,String)
val result = input.flatMap { case (_, txt) =>
val reader = new CSVReader(new StringReader(txt));
//reader.readAll().map(x => Data(x(0), x(1), x(2)))
reader.readAll()
}
result.collect().foreach(x => {
x.foreach(println); println("======")
})
}
}
输出
0 Front Left /usr/share/alsa/samples/Front_Left.wav ====== 1 Front Right /usr/share/alsa/samples/Front_Right.wav ======
3.2 保存CSV
import java.io.{StringReader, StringWriter}
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.json4s._
import org.json4s.jackson.JsonMethods._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.{read, write}
import scala.collection.JavaConversions._
import au.com.bytecode.opencsv.{CSVReader, CSVWriter}
/**
* Created by common on 17-4-3.
*/
case class Data(index: String, title: String, content: String)
object WordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val inputRDD = sc.parallelize(List(Data("index", "title", "content")))
inputRDD.map(data => List(data.index, data.title, data.content).toArray)
.mapPartitions { data =>
val stringWriter = new StringWriter();
val csvWriter = new CSVWriter(stringWriter);
csvWriter.writeAll(data.toList)
Iterator(stringWriter.toString)
}.saveAsTextFile("/home/common/coding/coding/Scala/word-count/sample_map_out")
}
}
输出
"index","title","content"
4.SequenceFile 是由没有相对关系结构的键值对文件组成的常用 Hadoop 格式。
SequenceFile 文件有同步标记, Spark 可 以用它来定位到文件中的某个点,然后再与记录的边界对齐。这可以让 Spark 使 用多个节点高效地并行读取 SequenceFile 文件。SequenceFile 也是Hadoop MapReduce 作 业中常用的输入输出格式,所以如果你在使用一个已有的 Hadoop 系统,数据很有可能是以 S equenceFile 的格式供你使用的。

import org.apache.hadoop.io.{IntWritable, Text}
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
/**
* Created by common on 17-4-6.
*/
object SparkRDD {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
//写sequenceFile,
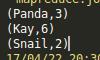
val rdd = sc.parallelize(List(("Panda", 3), ("Kay", 6), ("Snail", 2)))
rdd.saveAsSequenceFile("output")
//读sequenceFile
val output = sc.sequenceFile("output", classOf[Text], classOf[IntWritable]).
map{case (x, y) => (x.toString, y.get())}
output.foreach(println)
}
}
5.对象文件
对象文件看起来就像是对 SequenceFile 的简单封装,它允许存储只包含值的 RDD。和 SequenceFile 不一样的是,对象文件是使用 Java 序列化写出的。
如果你修改了你的类——比如增减了几个字段——已经生成的对象文件就不再可读了。
读取文件——用 SparkContext 中的 objectFile() 函数接收一个路径,返回对应的 RDD。
写入文件——要 保存对象文件, 只需在 RDD 上调用 saveAsObjectFile
6.Hadoop输入输出格式
除了 Spark 封装的格式之外,也可以与任何 Hadoop 支持的格式交互。Spark 支持新旧两套Hadoop 文件 API,提供了很大的灵活性。
旧的API:hadoopFile,使用旧的 API 实现的 Hadoop 输入格式
新的API:newAPIHadoopFile
接收一个路径以及三个类。第一个类是“格式”类,代表输入格式。第二个类是键的类,最后一个类是值的类。如果需要设定额外的 H adoop 配置属性,也可以传入一个 conf 对象。
KeyValueTextInputFormat 是最简单的 Hadoop 输入格式之一,可以用于从文本文件中读取键值对数据。每一行都会被独立处理,键和值之间用制表符隔开。
import org.apache.hadoop.io.{IntWritable, LongWritable, MapWritable, Text}
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark._
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
import org.apache.spark.rdd._
/**
* Created by common on 17-4-6.
*/
object SparkRDD {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
//使用老式 API 读取 KeyValueTextInputFormat(),以JSON文件为例子
//注意引用的包是org.apache.hadoop.mapred.KeyValueTextInputFormat
// val input = sc.hadoopFile[Text, Text, KeyValueTextInputFormat]("input/test.json").map {
// case (x, y) => (x.toString, y.toString)
// }
// input.foreach(println)
// 读取文件,使用新的API,注意引用的包是org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat
val job = new Job()
val data = sc.newAPIHadoopFile("input/test.json" ,
classOf[KeyValueTextInputFormat],
classOf[Text],
classOf[Text],
job.getConfiguration)
data.foreach(println)
//保存文件,注意引用的包是org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
data.saveAsNewAPIHadoopFile(
"input/test1.json",
classOf[Text],
classOf[Text],
classOf[TextOutputFormat[Text,Text]],
job.getConfiguration)
}
}

Hadoop 的非文件系统数据源
除 了 hadoopFile() 和 saveAsHadoopFile() 这 一 大 类 函 数, 还 可 以 使 用 hadoopDataset/saveAsHadoopDataSet 和 newAPIHadoopDataset/ saveAsNewAPIHadoopDataset 来访问 Hadoop 所支持的非文件系统的存储格式。例如,许多像 HBase 和 MongoDB 这样的键值对存储都提供了用来直接读取 Hadoop 输入格式的接口。我们可以在 Spark 中很方便地使用这些格式。
7.文件压缩
Spark 原生的输入方式( textFile 和 sequenceFile)可以自动处理一些类型的压缩。在读取压缩后的数据时,一些压缩编解码器可以推测压缩类型。
这些压缩选项只适用于支持压缩的 Hadoop 格式,也就是那些写出到文件系统的格式。写入数据库的 Hadoop 格式一般没有实现压缩支持。如果数据库中有压缩过的记录,那应该是数据库自己配置的。

8.读取har文件
val df = spark.read.text("har:///har/xxx/test/2019-06-30.har")
查看
scala> df.show() +--------------------+----------+----+ | value| dt|hour| +--------------------+----------+----+ |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| |/home/logs/sc...|2019-06-30| 17| +--------------------+----------+----+ only showing top 20 rows
以上是关于Spark学习笔记——数据读取和保存的主要内容,如果未能解决你的问题,请参考以下文章
Spark基础学习笔记28:Spark SQL数据源 - JDBC
Spark基础学习笔记25:Spark SQL数据源 - Parquet文件
Spark StreamingSpark Day10:Spark Streaming 学习笔记
Spark基础学习笔记26:Spark SQL数据源 - JSON数据集