Heterogeneous Storages in HDFS
Posted tokendeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Heterogeneous Storages in HDFS相关的知识,希望对你有一定的参考价值。
Reference:
《Archival Storage, SSD & Memory》
《Heterogeneous Storages in HDFS》
Hadoop has traditionally been used for batch processing data at large scale. Batch processing applications care more about raw sequential throughput than low-latency and hence the existing HDFS model where all attached storages are assumed to be spinning disks has worked well.
There is an increasing interest in using Hadoop for interactive query processing e.g. via Hive. Another class of applications makes use of random IO patterns e.g. HBase. Either class of application benefits from lower latency storage media. Perhaps the most interesting of the lower latency storage media are Solid State Disks (SSDs).
The high cost per Gigabyte for SSD storage relative to spinning disks makes it prohibitive to build a large scale cluster with pure SSD storage. It is desirable to have a variety of storage types and let each application choose the one that best fits its performance or cost requirements. Administrators will need mechanisms to manage a fair distribution of scarce storage resources across users. These are the scenarios that we aim to address by adding support for Heterogeneous Storages in HDFS.
Background
Let’s take a quick sidebar to review the performance characteristics of a few common storage types. If you are familiar with this topic you may skip to the next section.
Storages can be chiefly evaluated on three classes of performance metrics:
- Cost per Megabyte.
- Durability. This is the measure of the permanence of data once it has been successfully written to the medium. Modern hard disks are highly durable, however given a large enough collection of disks, regular disk failures are a statistical certainty. Annual Failure Rates of disks vary between 2 – 8% for 1 – 2 year old disks as observed in a large scale study of disk failure rates [1].
- Performance. There are two key measures of storage performance:
- Throughput: This is the maximum raw read/write rate that the storage can support and is typically measured in MegaBytes/second (MBps). This is the primary metric that batch processing applications care about.
- IO operations per second: The number of IO operations per second is affected by the workload and IO size. The rotational latency of spinning disks limits the maximum IOPS for a random IO workload which can limit the performance of interactive query applications. e.g. a 7200 RPM hard disk (typical for commodity hardware) will be limited to a theoretical maximum of 240 IOPS for a purely random IO workload.
The following table summarizes the characteristics of a few common storage types based on the above metrics.
| Storage Type | Throughput | Random IOPS | Data Durability | Typical Cost |
| HDD | High | Low | Moderate, failures can occur at any time. | 4c/GB |
| SSD | High | High | Moderate, failures can occur at any time. | 50c/GB for internal SATA SSD. roughly costs 10x or more of HDD |
| NAS (Network attached storage) | High | Varies | May employ RAID for high durability | Varies based on features, typically falls between HDD and SSD. |
| RAM | Very high | Very high | No durability, data is lost on process restart | >$10/GB roughly costs 100x or more of HDD |
Design Philosophy
We approached the design with the following goals:
- HDFS will not know about the performance characteristics of individual storage types. HDFS just provides a mechanism to expose storage types to applications. The only exception we make is DISK i.e. hard disk drives. This is the default fallback storage type. Even this may be made configurable in the future. As a corollary we avoid using the terms Tiered Storage or Hierarchical Storage.
- Pursuant to (1), we do not plan to provide any APIs to enumerate or choose storage types based on their characteristics. Storage types will be explicitly enumerated.
- Administrators must be able to limit the usage of individual storage types by user.
Changes to HDFS Storage Architecture
The NameNode and HDFS clients have historically viewed each DataNode as a single storage unit. The NameNode has not been aware of the number of storage volumes on a given DataNode and their individual storage types and capacities.
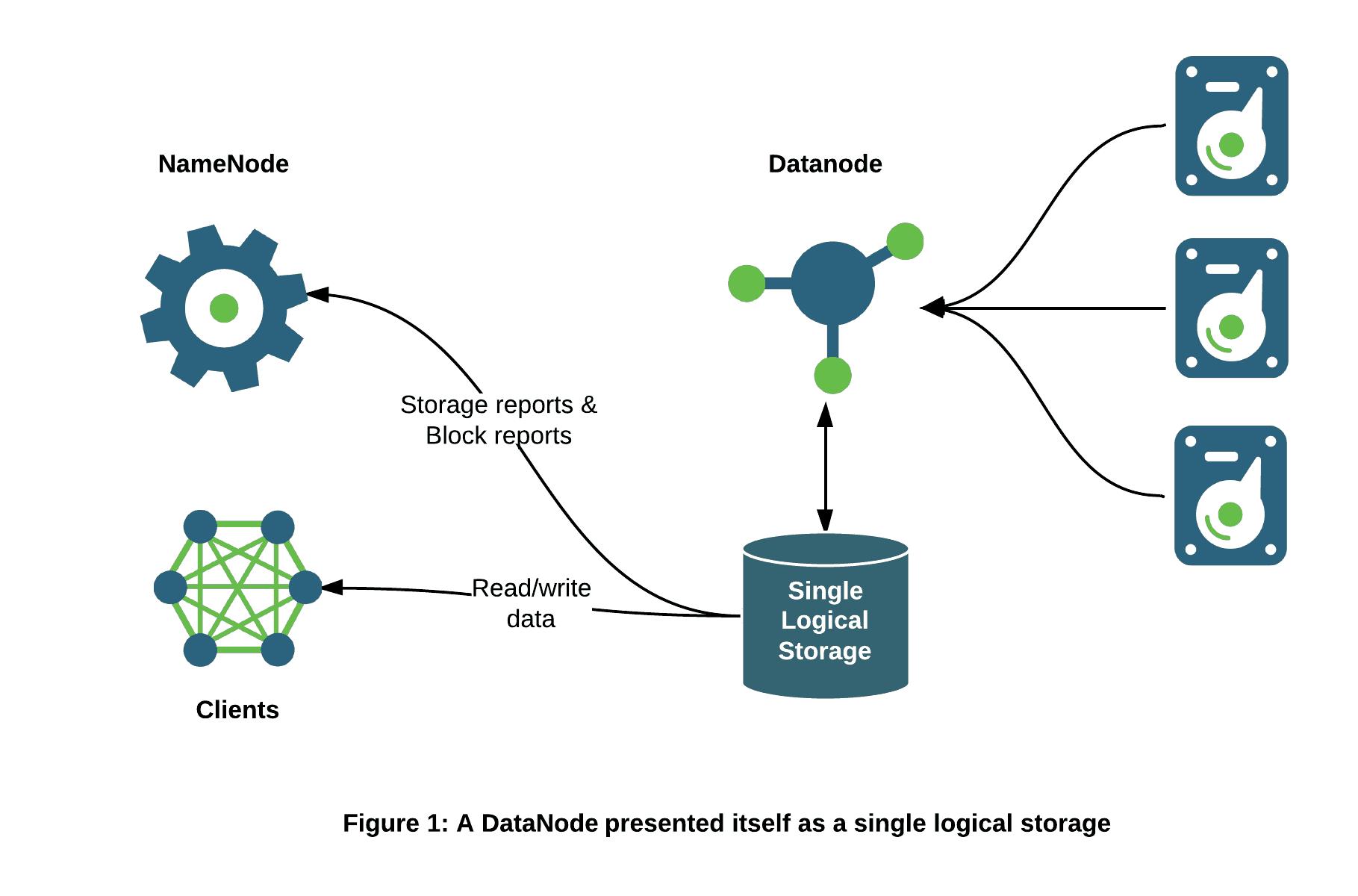
DataNodes communicate their storage state through the following types of messages:
- Storage Report. A storage report contains summary information about the state of a storage including capacity and usage details. The Storage Report is contained within a Heartbeat which is sent once every few seconds by default.
- Block Report. A block report is a detailed report of the individual block replicas on a given DataNode. Block reports are split into two types: a. Incremental block report sent periodically that lists the newly received and deleted blocks i.e. delta since the last incremental report; and b. Full block report sent less frequently that has a complete list of all block replicas currently on the DataNode.
Currently each DataNode sends a single storage report and a single block report containing aggregate information about all attached storages.
With Heterogeneous Storage we have changed this picture so that the DataNode exposes the types and usage statistics for each individual storage to the NameNode. This is a fundamental change to the internals of HDFS and allows the NameNode to choose not just a target DataNode when placing replicas, but also the specific storage type on each target DataNode.

Separating the DataNode storages in this manner will also allow scaling the DataNode to larger capacity by reducing the size of individual block reports which can be processed faster by the NameNode.
How Applications will use Heterogeneous Storages
We plan to introduce the idea of Storage Preferences for files. A Storage Preference is a hint to HDFS specifying how the application would like block replicas for the given file to be placed. Initially the Storage Preference will include: a. The desired number of file replicas (also called the replication factor) and; b. The target storage type for the replicas.
HDFS will attempt to satisfy the Storage Preference based the following factors:
- Availability of quota.
- Availability of storage space. Based on availability of space, some or all block replicas of the given file may be placed on the requested storage.
If the target storage type e.g. SSD is not available, then HDFS will attempt to place replicas on the fallback storage medium (Hard disk drives).
An applications can optionally specify a Storage Preference when creating a file, or it may choose to modify the Storage Preference on an existing file.
The following FileSystem API changes will be exposed to allow applications to manipulate Storage Preferences:
FileSystem#createwill optionally accept Storage Preference for the new file.FileSystem#setStoragePreferenceto change the Storage Preference of a single file. Replaces any existing Storage Preference on the file.FileSystem#getStoragePreferenceto query the Storage Preference for a given file.
Changing the Storage Preference of an existing file will initiate the migration of all existing file blocks to the new target storage. The call will return success or failure depending on the quota availability (more on quotas in the next section). The actual migration may take a long time depending on the size of the file. An application can query the current distribution of the block replicas of the file using DFSClient#getBlockLocations.
The API will be documented in detail on HDFS-5682.
Quota Management Improvements
Quota is a hard limit on the disk space that may be consumed by all the files under a given directory tree. Quotas can be set by the administrator to restrict the space consumption of specific users by applying limits on their home directory or on specific directories shared by users. Disk space quota is deducted based on the number of replicas. Thus if a 1GB file is configured to have three block replicas, the total quota consumed by the file will be 3GB.
Disk space quota is assumed to be unlimited when not configured for a given directory. Quotas are checked recursively starting at a given directory and walking up to the root. The effective quota of any directory is the minimum of (Directory quota, Parent quota, Grandparent quota, … , Root quota). An interesting property of disk space quota is that it can be reduced by the administrator to be something less than the combined disk usage under the directory tree. This leaves the directory in an indefinite Quota Violation state unless one or more replicas are deleted.
We will extend the existing Quota scheme to add a per storage-type quota for each directory. For a given directory, if its parent does not specify any per-type quota, then the per-type quota of the directory applies. However if the parent does specify a per-type quota, then the minimum of the (parent, subdirectory) applies. If the parent explicitly specifies a per-type quota of zero, then the children cannot use anything. This property can be used by the administrator to prevent creating files on SSD under /tmp, for example.
Implementation Status
Given the scope of the changes we have chosen to implement the feature in two principal phases. The first phase adds support for exposing the DataNode as a collection of storages. This support is currently available in trunk and is planned to be merged into the Apache branch-2 so that it will be available in the Apache Hadoop 2.4 release.
The second phase will add API support for applications to make use of Storage Types and is planned to align with the 2.5 release time frame.
References
- Eduardo Pinheiro et. al. 2007. Failure Trends in a Large Disk Drive Population.
- Design document – ‘Heterogeneous Storage for HDFS‘.
- HDFS-2832. Enable support for heterogeneous storages in HDFS.
- HDFS-5682. Heterogeneous Storage phase 2 – APIs to expose Storage Types.
Categorized by :
HDFS
以上是关于Heterogeneous Storages in HDFS的主要内容,如果未能解决你的问题,请参考以下文章
HGsuspector: Scalable Collective Fraud Detection in Heterogeneous Graphs
论文阅读|Info2vec: An aggregative representation method in multi-layer and heterogeneous networks
What is Heterogeneous Computing?