大数据(9h)FlinkSQL双流JOIN
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(9h)FlinkSQL双流JOIN相关的知识,希望对你有一定的参考价值。
文章目录
重点是Lookup Join和Processing Time Temporal Join,其它随意
1、环境
WIN10+IDEA2021+JDK1.8+本地mysql8
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.13.6</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>2.0.3</slf4j.version>
<log4j.version>2.17.2</log4j.version>
<fastjson.version>2.0.19</fastjson.version>
<lombok.version>1.18.24</lombok.version>
</properties>
<!-- https://mvnrepository.com/ -->
<dependencies>
<!-- Flink -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<!-- FlinkSQL -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>$flink.version</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>$slf4j.version</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>$slf4j.version</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>$log4j.version</version>
</dependency>
<!-- JSON解析 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>$fastjson.version</version>
</dependency>
<!-- 简化JavaBean书写 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>$lombok.version</version>
</dependency>
</dependencies>
2、Temporal Joins
2.1、基于处理时间(重点)
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class Hi
public static void main(String[] args)
//创建流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//创建流式表执行环境
StreamTableEnvironment tbEnv = StreamTableEnvironment.create(env);
//双流
DataStreamSource<Tuple2<String, Integer>> d1 = env.fromElements(
Tuple2.of("a", 2),
Tuple2.of("b", 3));
DataStreamSource<P> d2 = env.fromElements(
new P("a", 4000L),
new P("b", 5000L));
//创建临时视图
tbEnv.createTemporaryView("v1", d1);
tbEnv.createTemporaryView("v2", d2);
//双流JOIN
tbEnv.sqlQuery("SELECT * FROM v1 LEFT JOIN v2 ON v1.f0=v2.pid").execute().print();
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class P
private String pid;
private Long timestamp;
结果
+----+-------+-------+-------------+-------------+
| op | f0 | f1 | pid | timestamp |
+----+-------+-------+-------------+-------------+
| +I | a | 2 | (NULL) | (NULL) |
| -D | a | 2 | (NULL) | (NULL) |
| +I | a | 2 | a | 4000 |
| +I | b | 3 | (NULL) | (NULL) |
| -D | b | 3 | (NULL) | (NULL) |
| +I | b | 3 | b | 5000 |
+----+-------+-------+-------------+-------------+
2.1.1、设置状态保留时间
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import java.util.Scanner;
public class Hi
public static void main(String[] args)
//创建流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//创建流式表执行环境
StreamTableEnvironment tbEnv = StreamTableEnvironment.create(env);
//设置状态保留时间
tbEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5L));
//双流
DataStreamSource<Tuple2<String, Long>> d1 = env.addSource(new AutomatedSource());
DataStreamSource<String> d2 = env.addSource(new ManualSource());
//创建临时视图
tbEnv.createTemporaryView("v1", d1);
tbEnv.createTemporaryView("v2", d2);
//双流JOIN
tbEnv.sqlQuery("SELECT * FROM v1 INNER JOIN v2 ON v1.f0=v2.f0").execute().print();
/** 手动输入的数据源(请输入a或b进行测试) */
public static class ManualSource implements SourceFunction<String>
public ManualSource()
@Override
public void run(SourceFunction.SourceContext<String> sc)
Scanner scanner = new Scanner(System.in);
while (true)
String str = scanner.nextLine().trim();
if (str.equals("STOP")) break;
if (!str.equals("")) sc.collect(str);
scanner.close();
@Override
public void cancel()
/** 自动输入的数据源 */
public static class AutomatedSource implements SourceFunction<Tuple2<String, Long>>
public AutomatedSource()
@Override
public void run(SourceFunction.SourceContext<Tuple2<String, Long>> sc) throws InterruptedException
for (long i = 0L; i < 999L; i++)
Thread.sleep(1000L);
sc.collect(Tuple2.of("a", i));
sc.collect(Tuple2.of("b", i));
@Override
public void cancel()
测试结果
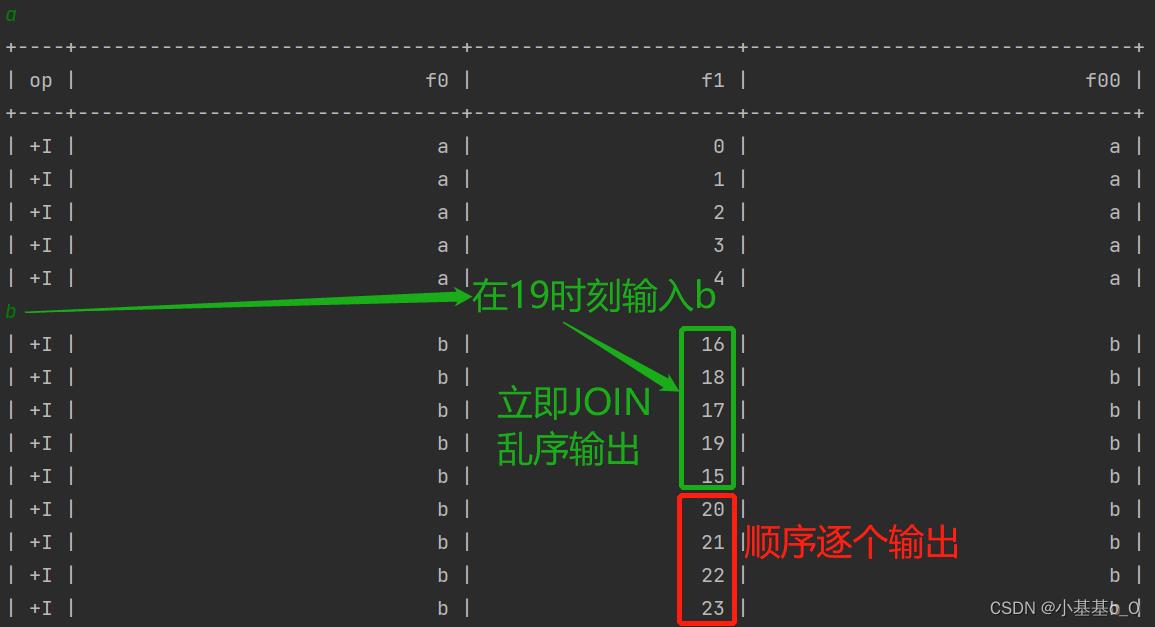
2.2、基于事件时间

import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class Hello
public static void main(String[] args)
//创建流和表的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
StreamTableEnvironment tbEnv = StreamTableEnvironment.create(env);
//创建数据流,设定水位线
tbEnv.executeSql("CREATE TABLE v1 (" +
" x STRING PRIMARY KEY," +
" y BIGINT," +
" ts AS to_timestamp(from_unixtime(y,'yyyy-MM-dd HH:mm:ss'))," +
" watermark FOR ts AS ts - INTERVAL '2' SECOND" +
") WITH (" +
" 'connector'='filesystem'," +
" 'path'='src/main/resources/a.csv'," +
" 'format'='csv'" +
")");
tbEnv.executeSql("CREATE TABLE v2 (" +
" x STRING PRIMARY KEY," +
" y BIGINT," +
" ts AS to_timestamp(from_unixtime(y,'yyyy-MM-dd HH:mm:ss'))," +
" watermark FOR ts AS ts - INTERVAL '2' SECOND" +
") WITH (" +
" 'connector'='filesystem'," +
" 'path'='src/main/resources/b.csv'," +
" 'format'='csv'" +
")");
//执行查询
tbEnv.sqlQuery("SELECT * " +
"FROM v1 " +
"LEFT JOIN v2 FOR SYSTEM_TIME AS OF v1.ts " +
"ON v1.x = v2.x"
).execute().print();
打印结果
+----+---+------------+-------------------------+--------+------------+------------------------大数据(9f)Flink双流JOIN
2021年大数据Flink(四十五):扩展阅读 双流Join