大数据(9f)Flink双流JOIN
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(9f)Flink双流JOIN相关的知识,希望对你有一定的参考价值。
文章目录
概述
Flink双流JOIN可用算子或SQL实现,FlinkSQL的JOIN在另一篇讲
算子JOIN中较常用的是intervalJoin
开发环境
WIN10+IDEA
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.14.6</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>2.0.3</slf4j.version>
<log4j.version>2.17.2</log4j.version>
<lombok.version>1.18.24</lombok.version>
</properties>
<dependencies>
<!-- Flink -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>$slf4j.version</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>$slf4j.version</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>$log4j.version</version>
</dependency>
<!-- 简化JavaBean书写 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>$lombok.version</version>
</dependency>
</dependencies>
使用状态列表实现 INNER JOIN(双流connect后CoProcessFunction)

import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;
public class Hello
public static void main(String[] args) throws Exception
//创建执行环境,设置并行度
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//创建双流
DataStreamSource<Tuple2<String, Long>> d1 = env.fromElements(
Tuple2.of("a", 2L),
Tuple2.of("a", 3L),
Tuple2.of("b", 5L)
);
DataStreamSource<Tuple2<String, String>> d2 = env.fromElements(
Tuple2.of("a", "A"),
Tuple2.of("b", "B"),
Tuple2.of("c", "C")
);
//双流KeyBy
KeyedStream<Tuple2<String, Long>, String> kd1 = d1.keyBy(t -> t.f0);
KeyedStream<Tuple2<String, String>, String> kd2 = d2.keyBy(t -> t.f0);
//connect
ConnectedStreams<Tuple2<String, Long>, Tuple2<String, String>> c = kd1.connect(kd2);
//CoProcessFunction<IN1, IN2, OUT>
c.process(new CoProcessFunction<Tuple2<String, Long>, Tuple2<String, String>, String>()
ListState<Tuple2<String, Long>> l1;
ListState<Tuple2<String, String>> l2;
@Override
public void open(Configuration parameters)
RuntimeContext r = getRuntimeContext();
l1 = r.getListState(new ListStateDescriptor<>("L1", Types.TUPLE(Types.STRING, Types.LONG)));
l2 = r.getListState(new ListStateDescriptor<>("L2", Types.TUPLE(Types.STRING, Types.STRING)));
@Override
public void processElement1(Tuple2<String, Long> value, Context ctx, Collector<String> out) throws Exception
l1.add(value);
for (Tuple2<String, String> value2 : l2.get())
out.collect(value + "==>" + value2);
@Override
public void processElement2(Tuple2<String, String> value, Context ctx, Collector<String> out) throws Exception
l2.add(value);
for (Tuple2<String, Long> value1 : l1.get())
out.collect(value1 + "==>" + value);
).print();
//流环境执行
env.execute();
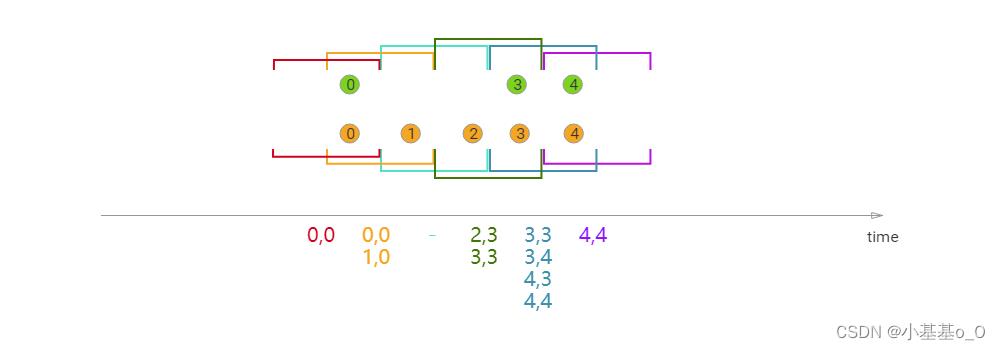
基于间隔的JOIN(Interval Join)

import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class Hello
public static void main(String[] args) throws Exception
//创建执行环境,设置并行度
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//创建双流和时间时间水位线策略
SingleOutputStreamOperator<U> d1 = env.fromElements(
new U("a", 3 * 1000L),
new U("b", 8 * 1000L),
new U("c", 13 * 1000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<U>forMonotonousTimestamps().withTimestampAssigner(
(SerializableTimestampAssigner<U>) (element, recordTimestamp) -> element.timestamp));
SingleOutputStreamOperator<U> d2 = env.fromElements(
new U("a", 4 * 1000L),
new U("b", 6 * 1000L),
new U("b", 7 * 1000L),
new U("c", 10 * 1000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<U>forMonotonousTimestamps().withTimestampAssigner(
(SerializableTimestampAssigner<U>) (element, recordTimestamp) -> element.timestamp));
//键控流
KeyedStream<U, String> k1 = d1.keyBy(u -> u.id);
KeyedStream<U, String> k2 = d2.keyBy(u -> u.id);
//基于间隔进行联合
k1.intervalJoin(k2).between(Time.seconds(-2L), Time.seconds(1L)).process(
new ProcessJoinFunction<U, U, String>()
@Override
public void processElement(U left, U right, Context ctx, Collector<String> out)
out.collect(left + " ==> " + right);
).print();
//流环境执行
env.execute();
@Data
@AllArgsConstructor
public static class U
String id;
Long timestamp;
结果
Hello.U(id=a, timestamp=3000) ==> Hello.U(id=a, timestamp=4000)
Hello.U(id=b, timestamp=8000) ==> Hello.U(id=b, timestamp=6000)
Hello.U(id=b, timestamp=8000) ==> Hello.U(id=b, timestamp=7000)
双流JOIN是双向的,下面两种写法是等价的
k1.intervalJoin(k2).between(Time.seconds(-2L), Time.seconds(1L))
k2.intervalJoin(k1).between(Time.seconds(-1L), Time.seconds(2L))
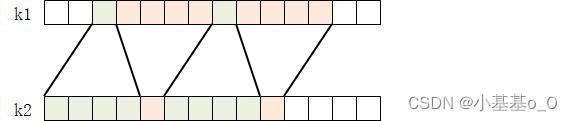
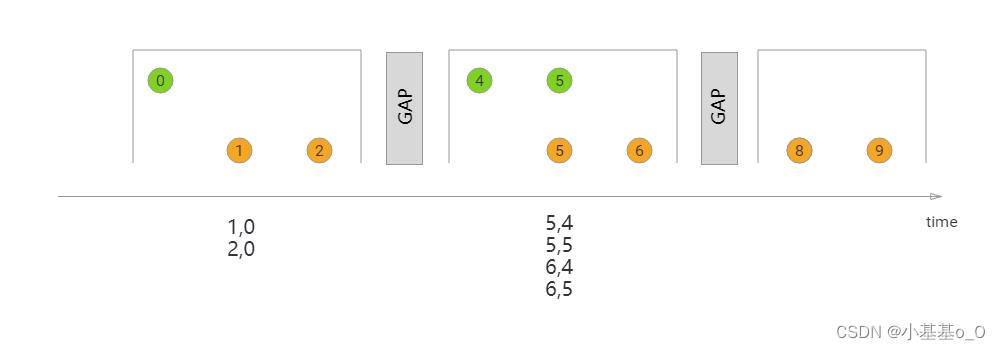
基于窗口的JOIN(Window Join)
窗口JOIN包括滚动窗口、滑动窗口、会话窗口
滚动窗口JOIN

滑动窗口JOIN
会话窗口JOIN
语法
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
下面只展示滚动窗口JOIN
import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.以上是关于大数据(9f)Flink双流JOIN的主要内容,如果未能解决你的问题,请参考以下文章