使用缓存保护MySQL
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用缓存保护MySQL相关的知识,希望对你有一定的参考价值。
1 更新缓存最佳实践
Redis的执行器非常薄,所以Redis只支持有限API,几乎没聚合查询能力,也不支持SQL。存储引擎也简单,直接在内存中用最简单数据结构保存数据。
如Redis的LIST在存储引擎的内存中的数据结构就是双向链表。内存是易失性存储,使用内存保存数据的Redis不保证数据可靠存储。Redis牺牲数据可靠性,换取高性能,适合做mysql前置缓存。
虽Redis支持数据持久化,还支持主从复制,但仍是不可靠存储,天然不保证数据可靠性,所以做缓存,很少作为唯一的数据存储。
即使只是把Redis作为缓存来使用,也要考虑这“数据不可靠性”,程序使用Redis时,要兼容Redis丢数据情况,做到即使Redis丢数据,也不影响系统数据准确性。
缓存MySQL的一张表时,通常直接选用主键作为Redis中的Key,如缓存订单表,用订单表主键订单号作为Redis key。
如果Redis实例不是给订单表专用,还要给订单的Key加统一前缀,如“orders:888888”。Value用来保存序列化后的整条订单记录,可选择可读性较好的JSON序列化方式,也可选择性能更好且更节省内存的二进制序列化方式。
缓存中的数据要怎么更新。
查询订单数据时,先去缓存查询:
- 命中缓存,直接返回订单数据
- 没命中,去DB查询,得到查询结果后,把订单数据写入缓存,然后返回
更新订单数据时,先更新DB中的订单表,若更新成功,再更新缓存中的数据。
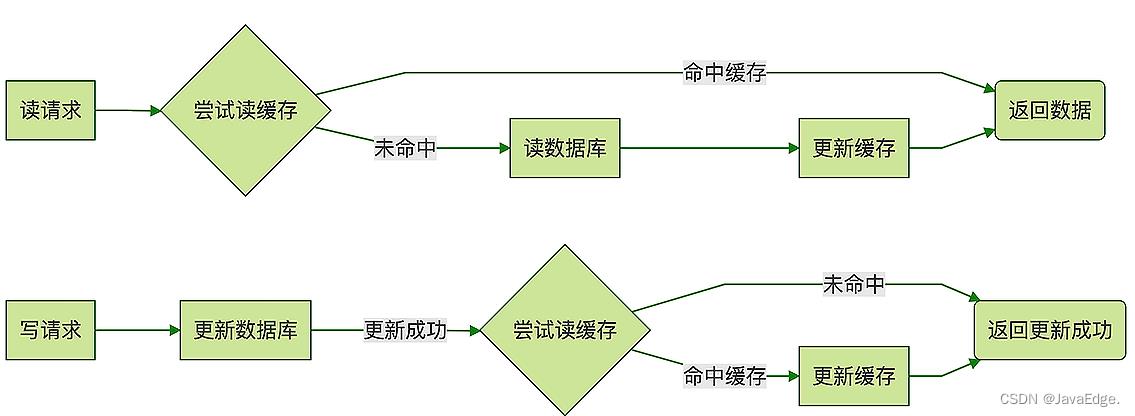
该缓存更新策略: Read/Write Through,绝大多数情况下可能都没问题。但并发下有概率出现“脏数据”,缓存中的数据可能被错误更新成旧数据。
如对同一条订单记录,同时产生一个读请求、一个写请求,被分配到两个不同线程并行执行:
- 读线程R1尝试读缓存,没命中,去DB读到订单数据
- 这时可能另一读线程R2抢先更新了缓存,在处理写请求线程W1中,先后更新DB、缓存。然后,拿订单旧数据的第一个读线程R1又把缓存更新成旧数据
这是一种case,还有如两线程对同一条订单数据并发写,也可能导致缓存“脏数据”,具体流程类似ABA。你不要觉得这种情况概率较小,出现“脏数据”概率和系统数据量及并发数量正相关,当系统数据量够大且并发够多,这种脏数据必现。
Cache Aside很好解决这问题,大多数情况是缓存最佳方式。Cache Aside模式和Read/Write Through很像,处理读请求逻辑一样,唯一差别:Cache Aside更新数据时,并非更新缓存,而是删除缓存。

订单服务收到更新数据请求后,先更新DB,若更新成功,再尝试删除缓存中订单:
- 若缓存中存在这条订单就删除它
- 若不存在就什么都不做
然后返回更新成功。这条更新后的订单数据将在下次被访问时,加载到缓存。Cache Aside更新缓存有效避免并发读写导致的脏数据问题。
2 缓存穿透导致的雪崩
缓存命中率低,就会出现大量“缓存穿透”
少量缓存穿透正常,需预防短时间内大量请求无法命中缓存,请求穿透到DB,导致DB忙,请求超时。大量请求超时会引发更多重试请求,更多重试请求让DB更忙,恶性循环导致雪崩。
系统初始化时,如系统升级重启或缓存刚上线,这时缓存空,若大量请求直接打过来,易引发大量缓存穿透,导致雪崩。为避免这种情况,可采用灰度发布,先接入少量请求,再逐步增加系统请求数量,直到全部请求都切换完成。
若不采用灰度发布,就在系统启动时对缓存预热:在系统初始化阶段,接收外部请求之前,先把最经常访问的数据填充到缓存,这样大量请求打过来,就不会出现大量缓存穿透。
缓存穿透时,若从DB读取数据时间较长,也易DB雪崩
如缓存数据是个复杂的DB联查结果,若在DB执行该查询需10s,那当缓存中这条数据过期后,最少10s内,缓存都不会有数据。
若这10s内有大量请求都要读取这缓存数据,这些请求都会穿透缓存,打到DB,易导致DB忙,当请求量较大,就会雪崩。
所以,若构建缓存数据需要的查询时间太长或并发量特别大,Cache Aside或Read/Write Through都可能出现大量缓存穿透。
对此无方法能应对所有场景,要针对业务场景选择合适解决方案。如牺牲缓存时效性和利用率,缓存所有数据,放弃Read Through策略所有的请求,只读缓存不读DB,用后台线程定时更新缓存数据。
3 总结
使用Redis作为MySQL的前置缓存,可以非常有效地提升系统的并发上限,降低请求响应时延。绝大多数情况下,使用Cache Aside模式来更新缓存都是最佳的选择,相比Read/Write Through模式更简单,还能大幅降低脏数据的可能性。
使用Redis的时候,还需要特别注意大量缓存穿透引起雪崩的问题,在系统初始化阶段,需要使用灰度发布或者其他方式来对缓存进行预热。如果说构建缓存数据需要的查询时间过长,或者并发量特别大,这两种情况下使用Cache Aside模式更新缓存,会出现大量缓存穿透,有可能会引发雪崩。
顺便说一句,我们今天这节课中讲到的这些缓存策略,都是非常经典的理论,早在互联网大规模应用之前,这些缓存策略就已经非常成熟了,在操作系统中,CPU Cache的缓存、磁盘文件的内存缓存,它们也都应用了我们今天讲到的这些策略。
所以无论技术发展的多快,计算机的很多基础的理论的知识都是相通的,你绞尽脑汁想出的解决工程问题的方法,很可能早都写在几十年前出版的书里。学习算法、数据结构、设计模式等等这些基础的知识,并不只是为了应付面试。
FAQ
分布式数据库Hive执行器和存储引擎,Hive不是个数据库,只是个执行器,存储引擎就是HDFS+Map-Reduce。在Hive中,一条SQL执行过程和MySQL差不多,Hive会解析SQL,生成并优化逻辑执行计划,然后它就会把逻辑执行计划交给Map-Reduce去执行了,后续生成并优化物理执行计划,在HDFS上执行查询这些事儿,都是Map-Reduce去干的。顺便说一下,Hive的执行引擎(物理执行引擎)可替换,所以就有Hive on Spark。
Cache Aside更新缓存会产生脏数据?
数据加版本号,写库时自动增一。更新缓存时,只允许高版本数据覆盖低版本数据。
Cache Aside应该是先删缓存后更新数据库吧?先更新数据库的话一旦缓存删除失败了,就会产生脏数据
严格来说,在并发情况下,二种方式都有可能产生脏数据。Cache Aside Pattern建议,先操作数据库,再操作缓存。
# Cache Aside
应用程序直接与DB、缓存交互,并负责对缓存的维护。
读数据时,先访问缓存,命中则直接返回。
如果不命中,则先查询DB,并将数据写到缓存,最后返回数据。
写数据时,同时更新DB和缓存。
# Read-Through
应用程序只与缓存交互,而对DB的读取由缓存来代理。
读数据时,先访问缓存,命中则直接返回。
如果不命中,则由缓存查询DB,并将数据写到缓存,最后返回数据。
# Write-Through
应用程序只与缓存交互,而对DB的写由缓存来代理。
写数据时,访问缓存,由缓存将数据写到DB,并将数据缓存起来。
例如使用Redis来缓存MySQL的数据,一般都是通过应用程序来直接与Redis、MySQL交互,我的理解是Cache Aside,包"是/否"删除Cache在内。
而Read-Through,像Guava LoadingCache,在load里面定义好访问DB的代码,后续的读操作都是直接与Cache交互了。
https://www.ehcache.org/documentation/3.8/caching-patterns.html
https://docs.oracle.com/cd/E15357_01/coh.360/e15723/cache_rtwtwbra.htm#COHDG5178
https://dzone.com/articles/using-read-through-amp-write-through-in-distribute
https://docs.microsoft.com/en-us/azure/architecture/patterns/cache-aside
1.为什么先更新mysql再更新(删除)redis比反过来好?
降低了脏数据出现的概率,前者产生脏数据是由于并发,后者几乎是必然,只要先写再读的请求发生,都会造成脏数据:先把redis中的缓存清了,然后读请求读不到去数据库中找到并更新在redis中。
2.为什么aside cache比read/write through好?
也是降低了脏数据出现的概率。前者只有读写先后访问数据库,又调转顺序访问redis时redis中出现脏数据,这个概率很小,而并发写时相当于不操作redis;而后者在并发写的情况下也容易脏。
用锁来解决并发问题。在读线程上写锁(说独占锁比较合适),是否跟MVCC相违背,MVCC不就是为了用来解决高并发带来的读写阻塞问题吗?我这边有两种解决思路不知可否:第一用版本控制,类似MVCC,第二种用Read/Write Through,写写并发在MVCC模式下依然是阻塞的,不算违背,所以只要把更新数据库与更新缓存放入统一事务中就行。读写并发不阻塞,是因为mysql用了快照读原因,那我们可以继续写线程更新缓存,读线程采用redis的setnx方式解决覆盖
mvcc可以很好的解决读写冲突,但是对于写写冲突,要么加锁,要么引入冲突检测机制,否则就会导致写倾斜的问题。这个在23中有详细的说明。
经常看到说用布隆过滤来解决缓存穿透问题,这个方案有实际的案例吗?
如果是真的可以那么怎么去操作呢?
先初始化所有可能存到缓存里面数据的key到一个足够大的布隆过滤器,然后如果有新增数据就就继续往过滤器中放,删除就从过滤器里面删(又看到说不用bit的话支持累加删除)
如果发现不在过滤器中就表示一定不存在,就无需查询了。如果在过滤器中也有可能不存在,这个时候在配合null值?
首先这是个经典的方案,靠谱是没问题的。它可以解决问题是,不用真正去查询数据集,就可以判断,请求的数据是不是,不在数据集内。如果不在就不用去查询数据集了。
不少数据库都内置了布隆过滤器来提升查询效率,比如HBase。
布隆过滤器的缺点就是有点复杂,实现难度还是挺大的。
如果缓存时有大量命中为null如何处理?如果命中null 也进行缓存,会导致缓存增长太快,容易被攻击
如果不缓存,又容易引起大量穿透?
没有完美解决方案。
首先,避免短时间大量人为的空值攻击,这个事儿应该在上层安全或者风控层面去解决。(即使无法判断是否空值攻击,至少要拦截住短时间大量的不正常访问请求)
剩余下来的就是业务上正常的查询返回空的情况,这种可能要从业务上来设计一下,尽量避免大量可能的空值查询。
以上2点做了之后,空值查询就会少多了,这个时候可以根据实际情况选择缓存空值,或者让空值穿透。
以上是关于使用缓存保护MySQL的主要内容,如果未能解决你的问题,请参考以下文章