Little Explanations#2-为递归神经网络编码文本
Posted 数据科学家联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Little Explanations#2-为递归神经网络编码文本相关的知识,希望对你有一定的参考价值。
本文为数盟原创译文,转载时请务必注明出处为“数盟社区”,并将原文链接置于文首。最近我对文本的生成感起了兴趣。随着微软在推特上新开发的人工智能又成为热门(尽管不是什么好消息),我发现解释一个基本的递归神经网络是如何接受输入指令并产生输出倒是一件很有意思的事。我将会解释在这种递归神经网络中文本是如何进行输入和分析,而不会过多的阐释它的细节。
首先,能够理解和分析机器学习的文本是最基本的目标。这样我们就可以了解为什么创造一个人们可以直接交流的乌托邦式梦想式的人工智能是如此的重要。因此我认为这有助于去寻找一个新方法去这样做。
假设我打算把“爸爸早餐吃了无花果”这句话输入机器,一个方法就是我们可以把这句话分解成一连串的单词。如果我们有一个包含给定文本语料库里的所有单词的词典,一个句子就可以用这些单词出现的次数来代表,这就叫做计数矢量化。那么通常被定义为由给定单词组成文本的文献,现在就可以通过单词频率来进行定义。这样就变成了一个词频词典,Scikit学习就提供了一个这样的例子。
但这也存在一些局限。其中之一就是临时数据不能被接收。计算机不能知道单词的顺序,这之中可能就会隐藏某些含义。然而其惊人的强大的基本情绪分析的能力通常会使它权衡得当,因此大量的文献和文章得以毫不费力的在Hadoop集群中传播。
递归神经网络可以通过提供一个根据时间特性和单词顺序来进行编码的方法来打开这个问题的缺口。与其说递归神经网络是接受一系列的特征然后拟合权重到一个近似的目标值,不如说它是接受一堆的特征。这是它与卷积神经网络的一个共性,因为卷积神经网络也要接受一堆诸如三个颜色通道的RGB图像之类的特性。然而通常情况下,MLP不需要这些。
递归神经网络经常被运用在时间序列分析上。例如通过分析过去十年的数据点来预测下一年的数据点。我们可以把这个例子外推到文本生成和识别。
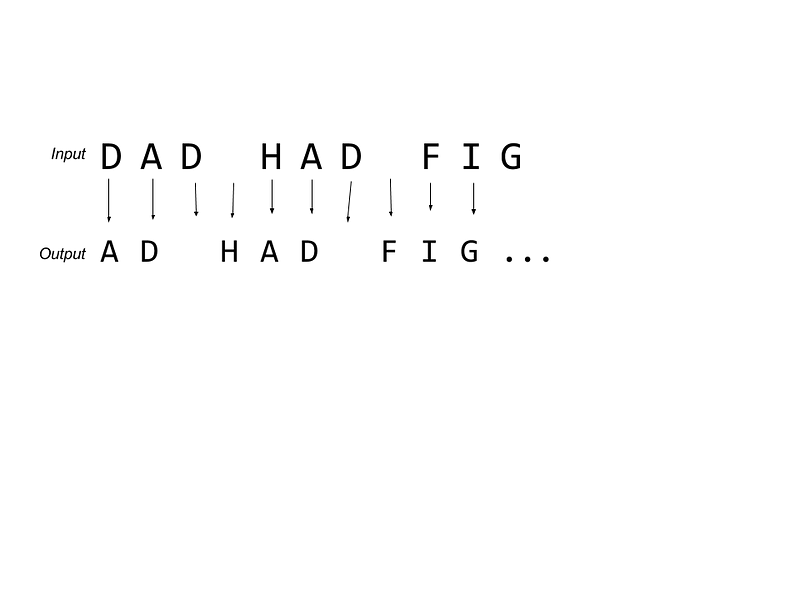
上面我画的这个例子就说明了这一点。对于“父亲吃了无花果”这个短语,这个网络试图通过前面的字母推测下一个字母,所以它会有这次预测为A下次就偏重成D的情况。目前它还不是一个完美的系统。例如,一篇文章采用第二种D,这意味着这里的权重不能太绝对。在预测时,网络将为每个字母输出一组概率。从本质上讲, 递归神经网络是利用字母的概率。
因此,在为网络准备文本时,我们需要找到一种可以将字母形式的数据转化为数字形式的数据的方法,让我们的网络可以理解它。为此,我们重新格式化数据如下图所示。

每个字母通过特性或列的方式表现出来。虽然很难解释,但上面的图有助于说明这一点。上面这个例子自然是简化了的(你会发现我为什么选择了一个荒谬的句子“父亲吃无花果”,为的是我可以轻易地把每一个字母放入列)。在实践中,它不仅对每个字母编码也为标点符号、新行和空格编码。
人们研究这些系统并通过试图模仿唐纳德·特朗普和《圣经》的方式去生产机器人,这很有趣,但是你可以看到这个非常简单的系统的极限。语法几乎是没有意义的,标点也必须通过人工干预。我的例子是基于Keras github提供的。
我一直在做类似的事情,我很快就会写出来。我有一些有趣的文字去分享“合著”电脑。在此之前,在twitter上关注我和媒介!
“堆栈”这个词不是技术,但是我发现它能帮助我查看数据被输入系统。
以上是关于Little Explanations#2-为递归神经网络编码文本的主要内容,如果未能解决你的问题,请参考以下文章
赠书福利《The Little Schemer:递归与函数式的奥妙》
今日好书丨《The Little Schemer:递归与函数式的奥妙》
机器学习黑盒?SHAP(SHapley Additive exPlanations)使用 XGBoost 的可解释机器学习
论文笔记 Interpreting Black-Box Classifiers Using Instance-Level Visual Explanations