Spark SQL中的broadcast join分析
Posted dabokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL中的broadcast join分析相关的知识,希望对你有一定的参考价值。
在Spark-1.6.2中,执行相同join查询语句,broadcast join模式下,DAG和执行时间如下图所示:
1、broadcast join
(1)DAG
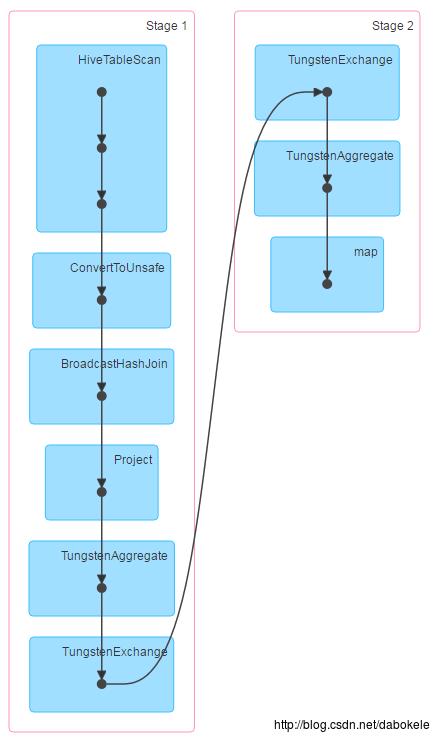
(2)执行时间
122 rows selected (22.709 seconds)
2、非broadcast join
(1)DAG
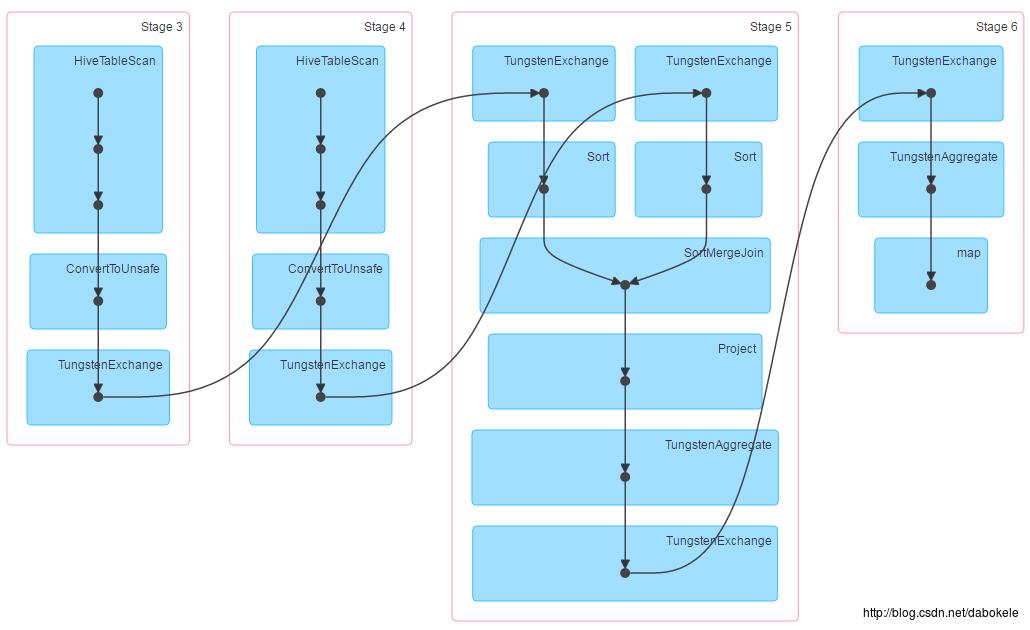
(2)执行时间
122 rows selected (55.512 seconds) 对于broadcast join模式,会将小于spark.sql.autoBroadcastJoinThreshold值(默认为10M)的表广播到其他计算节点,不走shuffle过程,所以会更加高效。
一、Spark源码解析
源码中的基本流程如下所示:
1、org.apache.spark.sql.execution.SparkStrategies类
决定是否使用broadcast join的逻辑在SparkStrategies类中,
/**
* Matches a plan whose output should be small enough to be used in broadcast join.
*/
object CanBroadcast {
def unapply(plan: LogicalPlan): Option[LogicalPlan] = plan match {
case BroadcastHint(p) => Some(p)
case p if sqlContext. conf.autoBroadcastJoinThreshold > 0 &&
p.statistics.sizeInBytes <= sqlContext.conf.autoBroadcastJoinThreshold => Some(p)
case _ => None
}
} 这里面sqlContext.conf.autoBroadcastJoinThreshold由参数spark.sql.autoBroadcastJoinThreshold来设置,默认为10 * 1024 * 1024Bytes(10M)。上面这段逻辑是说,如果该参数值大于0,并且p.statistics.sizeInBytes的值比该参数值小时,就会认为该表比较小,在做join时会broadcast到各个executor上,从而避免了shuffle过程。
2、org.apache.spark.sql.hive.HiveMetastoreCatalog类
p.statistics.sizeInBytes的值,查看HiveMetastoreCatalog类文件,如下所示
@transient override lazy val statistics: Statistics = Statistics(
sizeInBytes = {
val totalSize = hiveQlTable.getParameters.get(StatsSetupConst.TOTAL_SIZE)
val rawDataSize = hiveQlTable .getParameters.get(StatsSetupConst.RAW_DATA_SIZE)
// TODO: check if this estimate is valid for tables after partition pruning.
// NOTE: getting `totalSize` directly from params is kind of hacky, but this should be
// relatively cheap if parameters for the table are populated into the metastore. An
// alternative would be going through Hadoop's FileSystem API, which can be expensive if a lot
// of RPCs are involved. Besides `totalSize`, there are also `numFiles`, `numRows`,
// `rawDataSize` keys (see StatsSetupConst in Hive) that we can look at in the future.
BigInt(
// When table is external,`totalSize` is always zero, which will influence join strategy
// so when `totalSize` is zero, use `rawDataSize` instead
// if the size is still less than zero, we use default size
Option (totalSize).map(_.toLong).filter(_ > 0)
.getOrElse(Option (rawDataSize).map(_.toLong).filter(_ > 0)
.getOrElse(sqlContext.conf.defaultSizeInBytes)))
}
) 会从hive的tblproperties属性中优先取出totalSize的数值,如果该值不大于0,则取rawDataSize的值,如果该值也不大于0,那么就取sqlContext.conf.defaultSizeInBytes。
3、org.apache.spark.sql.SQLConf类
那么sqlContext.conf.defaultSizeInBytes又是多少呢?这个值配置在SQLConf类中,如下所示。
private[spark] def defaultSizeInBytes: Long =
getConf(DEFAULT_SIZE_IN_BYTES , autoBroadcastJoinThreshold + 1L ) 取DEFAUTL_SIZE_IN_BYTES的值,这个值一般需要设置的比spark.sql.autoBroadcastJoinThreshold大,以避免其他表被broadcast出去了。可以看到,默认值为autoBroadcastJoinThreshold值加1。
上面这一段的意思是,按顺序取hive的表统计信息中的totalSize属性和rawDataSize属性,直到取到一个大于零的值为止。如果这两个值都不大于零,那么就默认该表不能被broadcast出去。
二、问题
从上面的过程可以看出,确定是否广播小表的决定性因素是hive的表统计信息一定要准确。并且,由于视图是没有表统计信息的,所以所有的视图在join时都不会被广播。
假如遇到这种需求:有一张全量快照分区表A,需要有一张表B永远指向表A的最新分区,但是又不能影响表B的broadcast join功能。
1、问题1:直接insert会慢
最直接的做法是使用insert overwrite table B select * from A where partition='20170322'来进行,在插入数据到B表后,会更新该表的totalSize和rawDataSize属性。
但是每次进行insert是一个很耗时的过程。
2、问题2:set location不更新表统计信息
如果想要避免这一过程的话,是不是可以用alter table B set location 'PATH_TO_TABLE_A/partition=20170322'的形式呢?可以这样做,但是这样又不会每次更新totalSize和rawDataSize属性了。
如果需要更新表统计信息的话,测试过了alter table B set tblproperties('totalSize'='123')语句,也不能生效。
如下所示,在更新前后,不仅totalSize没有变化,反而将rawDataSize给置为了-1。并且多了一些之前没有的默认值
0: jdbc:hive2://client:10000> show tblproperties shop_info;
numFiles 1
COLUMN_STATS_ACCURATE true
transient_lastDdlTime 1490283932
totalSize 102030
numRows 2000
rawDataSize 100030
0: jdbc:hive2://client:10000> alter table shop_info set tblproperties('totalSize'='1234');
0: jdbc:hive2://client:10000> show tblproperties shop_info;
numFiles 1
last_modified_by hadoop
last_modified_time 1490284040
transient_lastDdlTime 1490284040
COLUMN_STATS_ACCURATE false
totalSize 102030
numRows -1
rawDataSize -1 只能执行analyze table B compute statistics语句来跑map-reduce任务来统计了,这一过程也会比较耗时。
3、问题3:external table set location后会清除表统计信息
并且最好将表B建成external table形式,避免删除表B时将表A的数据删除掉。
在实践中发现,每次对external tale进行set location操作后,即使重新统计过表信息,它的totalSize和rawDataSize仍然会被清除掉。
# 首先按照shop_info表格式创建一个外部表,
0: jdbc:hive2://client:10000> create external table test_broadcast like shop_info;
# 查看表信息
0: jdbc:hive2://client:10000> show tblproperties test_broadcast;
EXTERNAL TRUE
transient_lastDdlTime 1490284194
# 重定向location
0: jdbc:hive2://client:10000> alter table test_broadcast set location 'hdfs://m000/user/hive/warehouse/tianchi.db/user_pay_train';
# 查看表信息
0: jdbc:hive2://client:10000> show tblproperties test_broadcast;
numFiles 0
EXTERNAL TRUE
last_modified_by hadoop
last_modified_time 1490284413
COLUMN_STATS_ACCURATE false
transient_lastDdlTime 1490284413
numRows -1
totalSize 0
rawDataSize -1
# 统计表信息
0: jdbc:hive2://client:10000> analyze table test_broadcast compute statistics;
# 查看表信息
0: jdbc:hive2://client:10000>show tblproperties test_broadcast;
numFiles 0
EXTERNAL TRUE
last_modified_by hadoop
last_modified_time 1490284413
transient_lastDdlTime 1490284751
COLUMN_STATS_ACCURATE true
numRows 65649782
totalSize 0
rawDataSize 2098020423
# 再次重定向
0: jdbc:hive2://client:10000> alter table test_broadcast set location 'hdfs://m000/user/hive/warehouse/tianchi.db/user_pay';
# 查看表信息
0: jdbc:hive2://client:10000>show tblproperties test_broadcast;
numFiles 0
EXTERNAL TRUE
last_modified_by hadoop
last_modified_time 1490284790
transient_lastDdlTime 1490284790
COLUMN_STATS_ACCURATE false
numRows -1
totalSize 0
rawDataSize -1三、解决办法
遇到这个问题有没有觉得很棘手。
1、问题分析
其实方法已经在上面展示过了。我们来看一下org.apache.spark.sql.hive.HiveMetastoreCatalog类中关于statistics的注释:
// NOTE: getting
totalSizedirectly from params is kind of hacky, but this should be
// relatively cheap if parameters for the table are populated into the metastore. An
// alternative would be going through Hadoop’s FileSystem API, which can be expensive if a lot
// of RPCs are involved. BesidestotalSize, there are alsonumFiles,numRows,
//rawDataSizekeys (see StatsSetupConst in Hive) that we can look at in the future.
这里说,直接获取totalSize并不是一个友好的办法,直接从这里获取totalSize只是相对比较快而已。其实可以通过HDFS的FileSystem API来获取该表在HDFS上的文件大小的。
看到这里,应该已经有了一个基本方法了。那就是将表B建为external table,并且每次遇到external table,直接去取hdfs上的文件大小。每次set location即可。这里唯一需要注意的是,通过HDFS FileSystem API获取文件大小是否耗时。这个可以通过下面的代码测试一下。
2、性能测试
测一下HDFS FileSystem API获取文件大小的耗时。
object HDFSFilesystemTest {
def main(args: Array[String ]) {
val conf = new Configuration()
conf.set("fs.default.name" , "hdfs://m000:8020")
val hiveWarehouse = "/user/hive/warehouse"
val path = new Path(hiveWarehouse)
val fs: FileSystem = path.getFileSystem(conf)
val begin = System.currentTimeMillis()
val size = fs.getContentSummary(path).getLength
println( s"$hiveWarehouse size is: $size Bytes")
val end = System.currentTimeMillis()
println( s"time consume ${end - begin} ms")
}
}输出结果如下,统计hive warehouse路径大小,耗时132毫秒。
/user/hive/warehouse size is: 4927963752 Bytes
time consume 132 ms3、源码修改
那么接下来修改一下org.apache.spark.sql.hive.HiveMetastoreCatalog中获取表大小的逻辑就可以了。
由于外部表会被重定向路径,或者指向路径的文件可以直接被put上来,所以统计的totalSize或者rawDataSize一般不准确。因此如果是外部表,直接获取hdfs文件大小。如果是非外部表,则按顺序取totalSize,rawDataSize的值,如果都不大于0,则通过HDFS FileSystem API获取hdfs文件大小了。
@transient override lazy val statistics: Statistics = Statistics(
sizeInBytes = {
BigInt (if ( hiveQlTable.getParameters.get("EXTERNAL" ) == "TRUE") {
try {
val hadoopConf = sqlContext.sparkContext.hadoopConfiguration
val fs: FileSystem = hiveQlTable.getPath.getFileSystem(hadoopConf)
fs.getContentSummary(hiveQlTable.getPath).getLength
} catch {
case e: IOException =>
logWarning("Failed to get table size from hdfs." , e)
sqlContext.conf.defaultSizeInBytes
}
} else {
val totalSize = hiveQlTable .getParameters.get(StatsSetupConst. TOTAL_SIZE)
val rawDataSize = hiveQlTable .getParameters.get(StatsSetupConst. RAW_DATA_SIZE)
// TODO: check if this estimate is valid for tables after partition pruning.
// NOTE: getting `totalSize` directly from params is kind of hacky, but this should be
// relatively cheap if parameters for the table are populated into the metastore. An
// alternative would be going through Hadoop's FileSystem API, which can be expensive if a lot
// of RPCs are involved. Besides `totalSize`, there are also `numFiles`, `numRows`,
// `rawDataSize` keys (see StatsSetupConst in Hive) that we can look at in the future.
if (totalSize != null && totalSize.toLong > 0L) {
totalSize.toLong
} else if (rawDataSize != null && rawDataSize.toLong > 0L) {
rawDataSize.toLong
} else {
try {
val hadoopConf = sqlContext.sparkContext.hadoopConfiguration
val fs: FileSystem = hiveQlTable.getPath.getFileSystem(hadoopConf)
fs.getContentSummary(hiveQlTable.getPath).getLength
} catch {
case e: IOException =>
logWarning("Failed to get table size from hdfs." , e)
sqlContext.conf.defaultSizeInBytes
}
}
})
}
) 改为之后,看了一下Spark-2中的源码,发现在org.apache.spark.sql.hive.MetastoreRelation中已经对此次进行了修改,如下所示:
@transient override lazy val statistics: Statistics = {
catalogTable.stats.getOrElse(Statistics(
sizeInBytes = {
val totalSize = hiveQlTable.getParameters.get(StatsSetupConst.TOTAL_SIZE)
val rawDataSize = hiveQlTable.getParameters.get(StatsSetupConst.RAW_DATA_SIZE)
// TODO: check if this estimate is valid for tables after partition pruning.
// NOTE: getting `totalSize` directly from params is kind of hacky, but this should be
// relatively cheap if parameters for the table are populated into the metastore.
// Besides `totalSize`, there are also `numFiles`, `numRows`, `rawDataSize` keys
// (see StatsSetupConst in Hive) that we can look at in the future.
BigInt(
// When table is external,`totalSize` is always zero, which will influence join strategy
// so when `totalSize` is zero, use `rawDataSize` instead
// when `rawDataSize` is also zero, use `HiveExternalCatalog.STATISTICS_TOTAL_SIZE`,
// which is generated by analyze command.
if (totalSize != null && totalSize.toLong > 0L) {
totalSize.toLong
} else if (rawDataSize != null && rawDataSize.toLong > 0) {
rawDataSize.toLong
} else if (sparkSession.sessionState.conf.fallBackToHdfsForStatsEnabled) {
try {
val hadoopConf = sparkSession.sessionState.newHadoopConf()
val fs: FileSystem = hiveQlTable.getPath.getFileSystem(hadoopConf)
fs.getContentSummary(hiveQlTable.getPath).getLength
} catch {
case e: IOException =>
logWarning("Failed to get table size from hdfs.", e)
sparkSession.sessionState.conf.defaultSizeInBytes
}
} else {
sparkSession.sessionState.conf.defaultSizeInBytes
})
}
))
}4、效果展示
对一张文件大小小于spark.sql.autoBroadcastJoinThreshold的external table进行表信息统计,将totalSize和rawDataSize置为不大于0的值后。分别在改源码前后进行测试。
(1)改动前
执行join语句,DAG执行计划如下图所示:
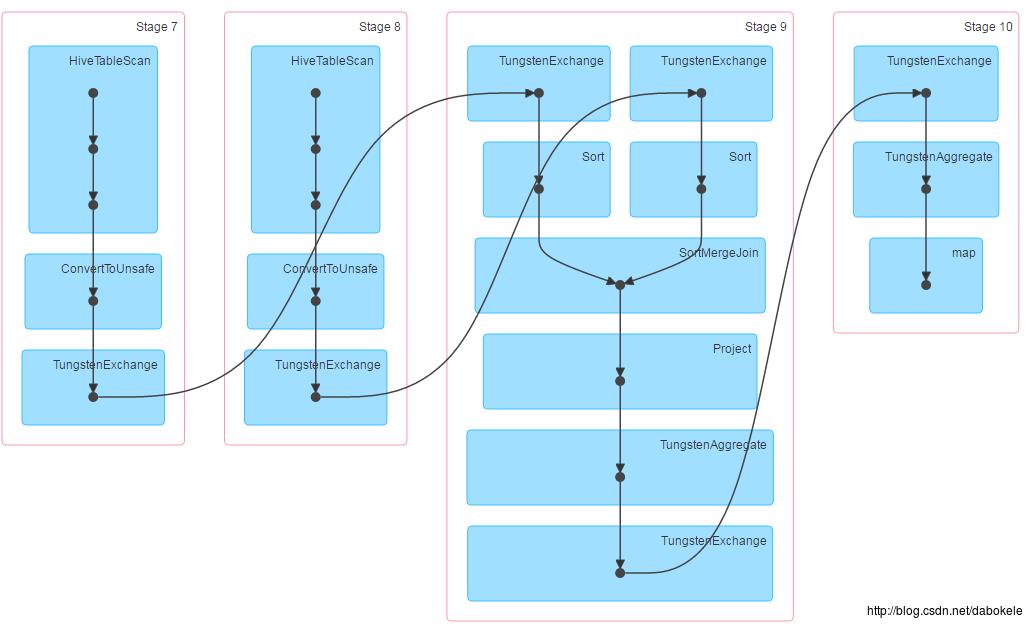
执行时间如下所示:
122 rows selected (58.862 seconds)(2)改动后
执行join语句,DAG执行计划如下图所示:
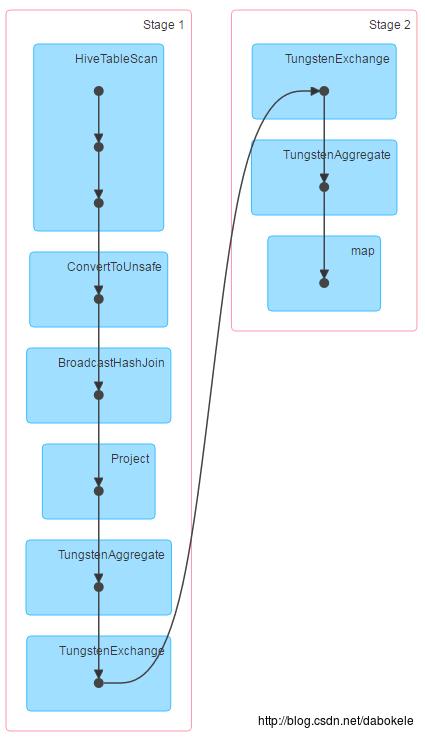
执行时间如下图所示:
122 rows selected (27.484 seconds)可以看到,改动源码后,走了broadcast join,并且执行时间明显缩短。
以上是关于Spark SQL中的broadcast join分析的主要内容,如果未能解决你的问题,请参考以下文章
Spark SQL有关broadcast join的不生效问题
Spark SQL有关broadcast join的不生效问题2
2-Spark-1-性能调优-数据倾斜2-Join/Broadcast的使用场景
ERROR: Timeout on the Spark engine during the broadcast join