Spark SQL有关broadcast join的不生效问题2
Posted javartisan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL有关broadcast join的不生效问题2相关的知识,希望对你有一定的参考价值。
今天同事反应他的广播不生效,看了一下代码,它的代码样子如下:
def main(args: Array[String]): Unit =
val spark = SparkSession.builder().appName("BroadCastJoinLLocalDebug").master("local[*]").getOrCreate()
val sc = spark.sparkContext
val smallTable = spark.sql("small table sql")
val bigTable = spark.sql("big table sql")
val smallTableBroadCastValue = sc.broadcast(smallTable).value
val result = bigTable.join(smallTableBroadCastValue, "joinkey")
// action
println(result.count())
spark.stop()
当时在猜想问题可能有两个:
1、sparkContext广播,当spark sql执行join时候无法拿到join的优化信息。
2、广播的是dataFrame这个变量,而不是里面的素有数据。
解决问题优先,解决方案:让他修改为使用spark sql broadcast function进行广播join,便生效解决问题!代码大概如下:
def main(args: Array[String]): Unit =
val spark = SparkSession.builder().appName("BroadCastJoinLLocalDebug").master("local[*]").getOrCreate()
val smallTable = spark.sql("small table sql")
val bigTable = spark.sql("big table sql")
val result = bigTable.join(org.apache.spark.sql.functions.broadcast(smallTable), "joinkey")
// action
println(result.count())
spark.stop()
问题解决之后进行简单的本地debug看一下原因,打断点跟进了一下广播dataFrame的逻辑,重点看的是如何序列化dataFrame到内存的,org.apache.spark.broadcast.TorrentBroadcast#writeBlocks方法便是完成序列化,在此方法中调用org.apache.spark.storage.BlockManager#putSingle:
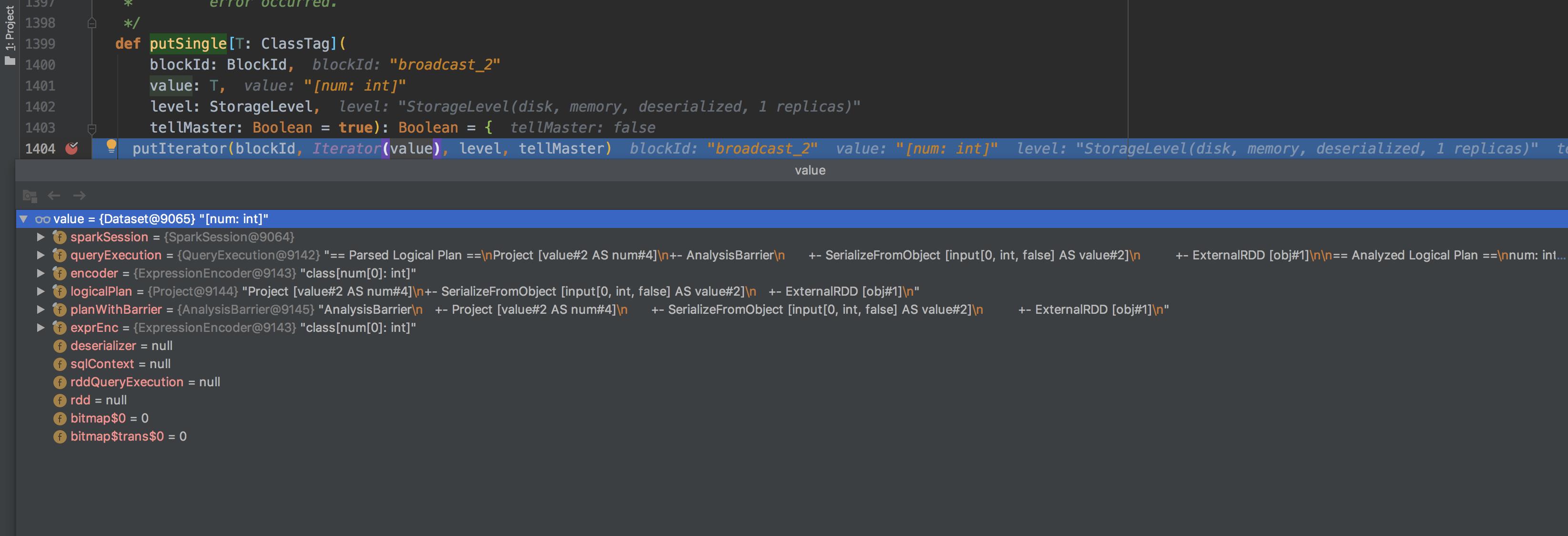
本地debug跟踪代码断点信息可以看到最终序列化的是dataFrame的实例数据(更多信息就不截图了,跟一下代码很直观就可以发现),而不是dataFrame所表示的数据集。也就是猜想的第二条。第一条还有待验证。所以当我们在使用join的时候跟普通的join是一样的。
以上是关于Spark SQL有关broadcast join的不生效问题2的主要内容,如果未能解决你的问题,请参考以下文章