数据湖及湖仓一体化项目学习框架
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖及湖仓一体化项目学习框架相关的知识,希望对你有一定的参考价值。

文章目录
数据湖及湖仓一体化项目学习框架
前言
利用框架的力量,看懂游戏规则,才是入行的前提
大多数人不懂,不会,不做,才是你的机会,你得行动,不能畏首畏尾
选择才是拉差距关键,风向,比你流的汗水重要一万倍,逆风划船要累死人的
上面这些看似没用,但又很重要,这里我就不在详述作用,有兴趣的同学可以看看我的大数据学习探讨话题:
这个栏目为初学者全面整理数据湖必学知识,内容是按照体系划分的,带你从基础知识到项目实战,想学会就得自律加坚持,赶快行动吧。
一、数据湖基础知识介绍
1、数据湖技术Hudi
大多数大数据企业在构建数仓时采用Lambda架构,一条离线数仓链路,一条实时数仓链路。一些实时业务多的公司构建数仓时采用Kappa架构,但是也避免不了离线处理一些数据,所以一些公司也采用Kappa架构+Lambda架构方式构建数仓。以上不同的架构都有各自的优点及缺点,这里不再赘述。批数据处理与流式数据处理的不同效率决定了针对两类数据采用不同的架构进行分析处理,未来数据仓库的发展也终将走向批数据和流数据使用同一套架构处理,同时也要求批数据及流数据存储上也需要统一,这就所说的批流一体,那么使用什么技术可以既能满足批数据海量存储分析又能满足实时数据存储的效率高、支持数据更新删除?数据湖技术应运而生。Hudi 就是典型的数据湖技术,支持批数据和流式数据的存储,同时还支持高效的OLAP分析查询。
在本栏目中将会带领大家学习为什么要用数据湖技术、Hudi Timeline、Hudi文件格式及索引、Hudi表类型、Hudi与Spark、Flink框架整合等知识,如果你在学习、工作中针对批流一体数据处理场景正不知选择何种技术,在工作中使用到数据湖技术,那么选择这个栏目绝对没错,将带领大家学习最热的批流一体、湖仓一体前沿技术,给自己学习、工作增加“魅力”分值。
主要知识点:
1.数据湖概念详解
2.数据湖与数据仓库区别
3.数据湖技术Hudi原理剖析
4.数据湖技术Hudi Timeline详解
5.数据湖技术Hudi 文件格式及索引详解
6.数据湖技术Hudi COW表类型详解
7.数据湖技术Hudi MOR表类型详解
8.数据湖技术Hudi 查询类型详解
9.数据湖技术Hudi与Spark框架整合
10.数据湖技术Hudi增删改查实战操作
11.数据湖技术Hudi覆盖分区和表数据
12.数据湖技术Hudi与Hive框架深度整合
13.数据湖技术Hudi与Flink框架深度整合
2、数据湖技术Iceberg
这里不再赘述,Iceberg就是典型的数据湖技术,支持批数据和流式数据的存储,同时还支持高效的OLAP分析查询。
主要知识点:
1.什么是数据湖
2.大数据为什么需要数据湖
3.Iceberg概念及特点
4.Iceberg数据存储格式
5.Iceberg术语
6.表格式Table Format
7.Iceberg特点详述
8.Iceberg分区与隐藏分区(Hidden Partition)
9.Iceberg表演化(Table Evolution)
10.模式演化(Schema Evolution)
11.分区演化(partition Evolution)
12.列顺序演化(Sort Order Evolution)
13.Iceberg数据类型
14.开启Hive支持Iceberg
15.Hive中操作Iceberg格式表
16.Iceberg表数据组织与查询
17.Iceberg底层数据存储
18.Spark3.1.2与Iceberg0.12.1整合
19.SparkSQL设置catalog配置
20.使用Hive Catalog管理Iceberg表
21.使用Hadoop Catalog管理Iceberg表
22.Spark与Iceberg整合DDL操作
23.DataFrame API加载Iceberg中的数据
24.Spark整合Iceberg之查询表快照
25.Spark整合Iceberg之查询表历史
26.Spark整合Iceberg之查询表data files
27.Spark整合Iceberg之查询Manifests
28.Spark整合Iceberg之查询指定快照数据
29.Spark整合Iceberg之根据时间戳查询数据
30.Spark整合Iceberg之回滚快照
31.Spark整合Iceberg之合并Iceberg表的数据文件
32.Spark整合Iceberg之 删除历史快照
33.spark整合Iceberg之 INSERT INTO
34.spark整合Iceberg之 MERGE INTO
35.spark整合Iceberg之 INSERT OVERWRITE
36.spark整合Iceberg之 DELETE FROM
37.spark整合Iceberg之 UPDATE
38.DataFrame API 写入Iceberg表
39.Structured Streaming实时写入Iceberg
40.Flink DataStream API 操作Iceberg
41.Flink DataStream API 实时写入Iceberg表
42.Flink DataStream API 批量/实时读取Iceberg表
43.Flink 指定基于快照实时增量读取数据
44.Flink 合并data files
45.Flink SQL API 与Iceberg整合
46.Flink SQL API 批量查询Iceberg表数据
47.Flink SQL API 实时查询Iceberg表数据
48.Flink SQL API指定基于快照实时增量读取数据
49.Flink SQL API 读取Kafka数据实时写入Iceberg表
50.Flink兼容Iceberg目前不足
51.数据湖技术Iceberg与Hudi对比
二、湖仓一体化项目
目前很多互联网公司处理公司海量数据都采用湖仓一体的架构技术设计方案,比如阿里、腾讯、百度、小米等,在数据智能时代,湖仓一体成为企业构建大数据栈的必选项,湖仓一体架构设计方案替换传统独立的数据仓库设计方案已经成为不可逆转的趋势。在数据分析领域,湖仓一体是未来,可以很好的应对当下时代数据离线和实时分析的需求,更适合数据量规模大的公司现状。
湖仓一体电商数据分析平台从Lambda架构、Kappa架构数仓的发展为出发点,详细阐述了目前湖仓一体构建数据分析平台方案设计优点与落地方案。本项目是基于某宝商城电商项目的电商数据分析平台,在技术方面涉及大数据技术组件搭建,湖仓一体分层数仓设计、实时到离线数据指标分析及数据大屏可视化,项目所用到的技术组件都从基础搭建开始,目的在于湖仓一体架构中数据仓库与数据湖融合打通,实现企业级项目离线与实时数据指标分析。在业务方面涉及到会员主题与商品主题,分析指标有用户实时登录信息分析、实时浏览pv/uv分析、实时商品浏览信息分析、用户积分指标分析等内容,其中技术涉及到Iceberg数据湖、Maxwell、Flink、Phoenix、ClickHouse等技术内容点。在项目中还会给大家讲解湖仓一体设计方式以及湖仓设计中的优化点,给各从业小伙伴打下坚实的基础。
如果你目前正打算学习大数据,不了解湖仓一体架构设计方式或者目前正在从事大数据开发对湖仓一体架构设计方式无从下手,那么来学习本栏目,全方位无死角的学习湖仓一体架构在企业真正落地实战,旨在帮助更多同学快速掌握湖仓一体架构设计方案。在此项目中我会带领大家敲出每个业务代码,同时教大家如何在湖仓一体架构中针对实时场景、离线场景进行分析,项目执行过程中优化处理、如何进行数据发布及数据可视化等重点内容。
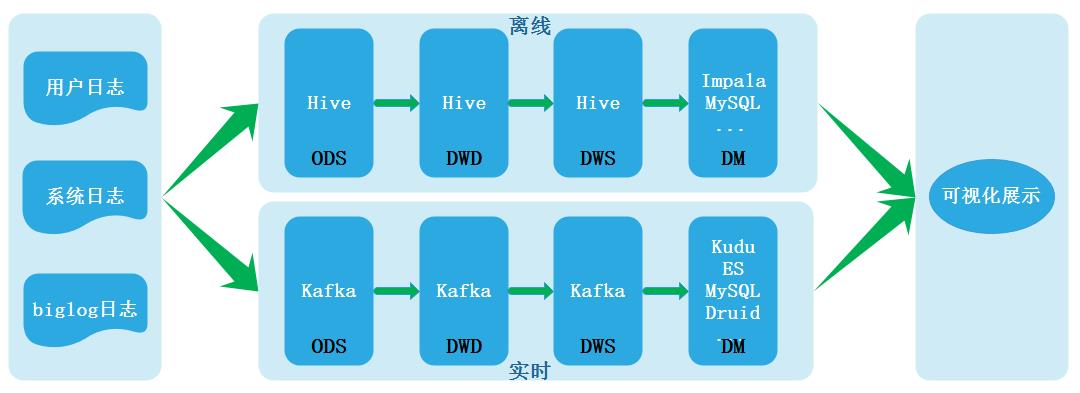
Lambda实时数仓架构:
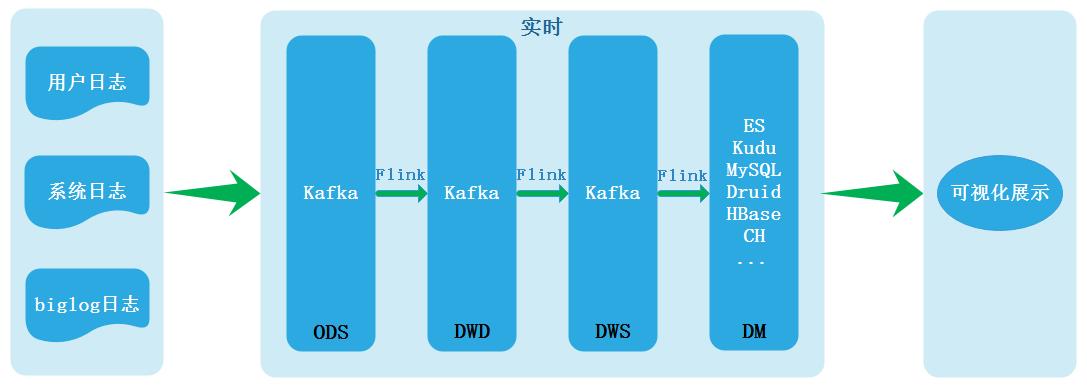
Kappa实时数仓架构:
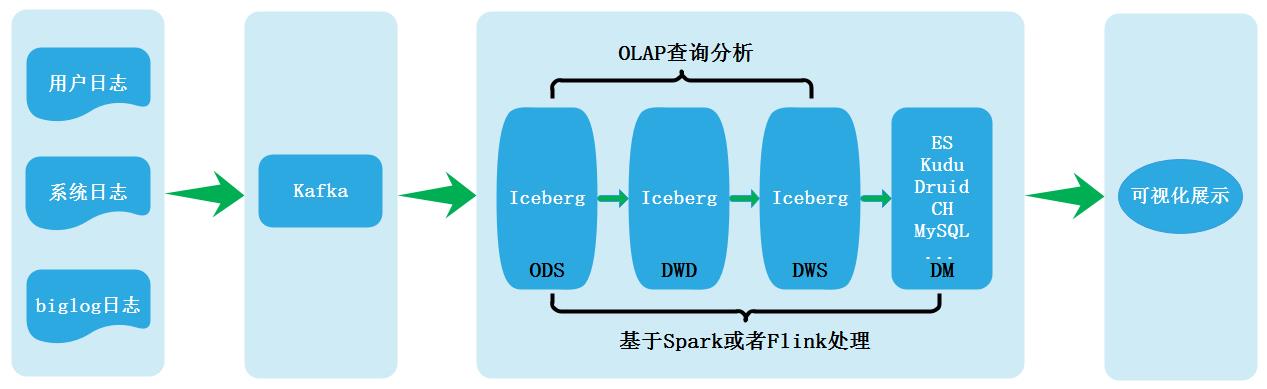
批流一体实时数仓架构:
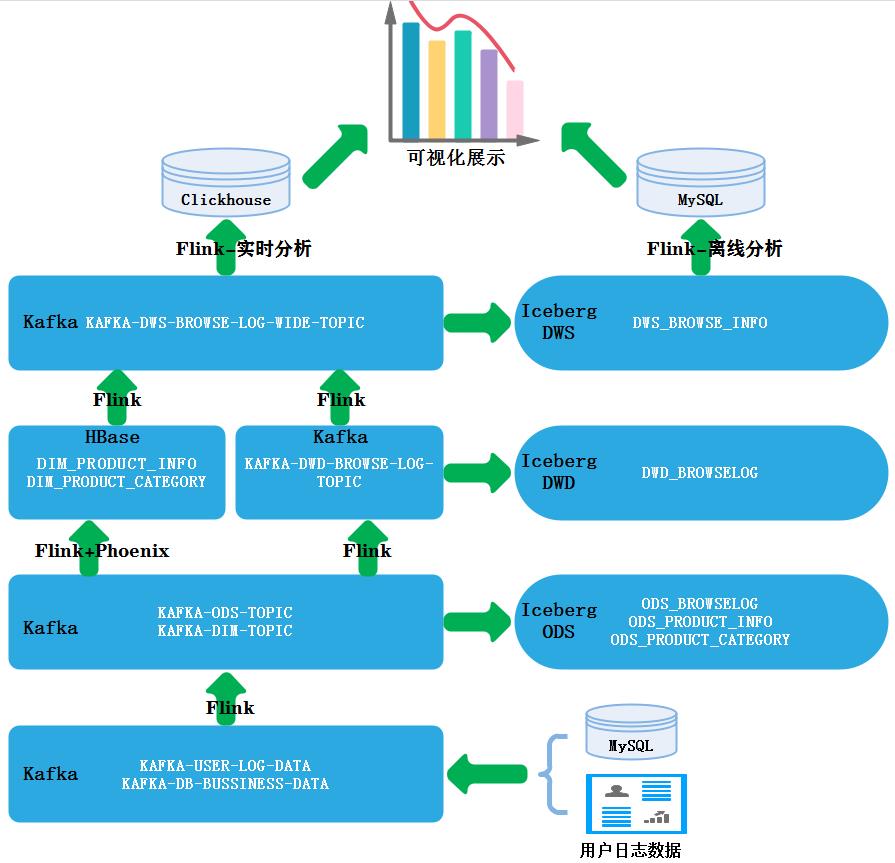
湖仓一体项目分层架构设计:

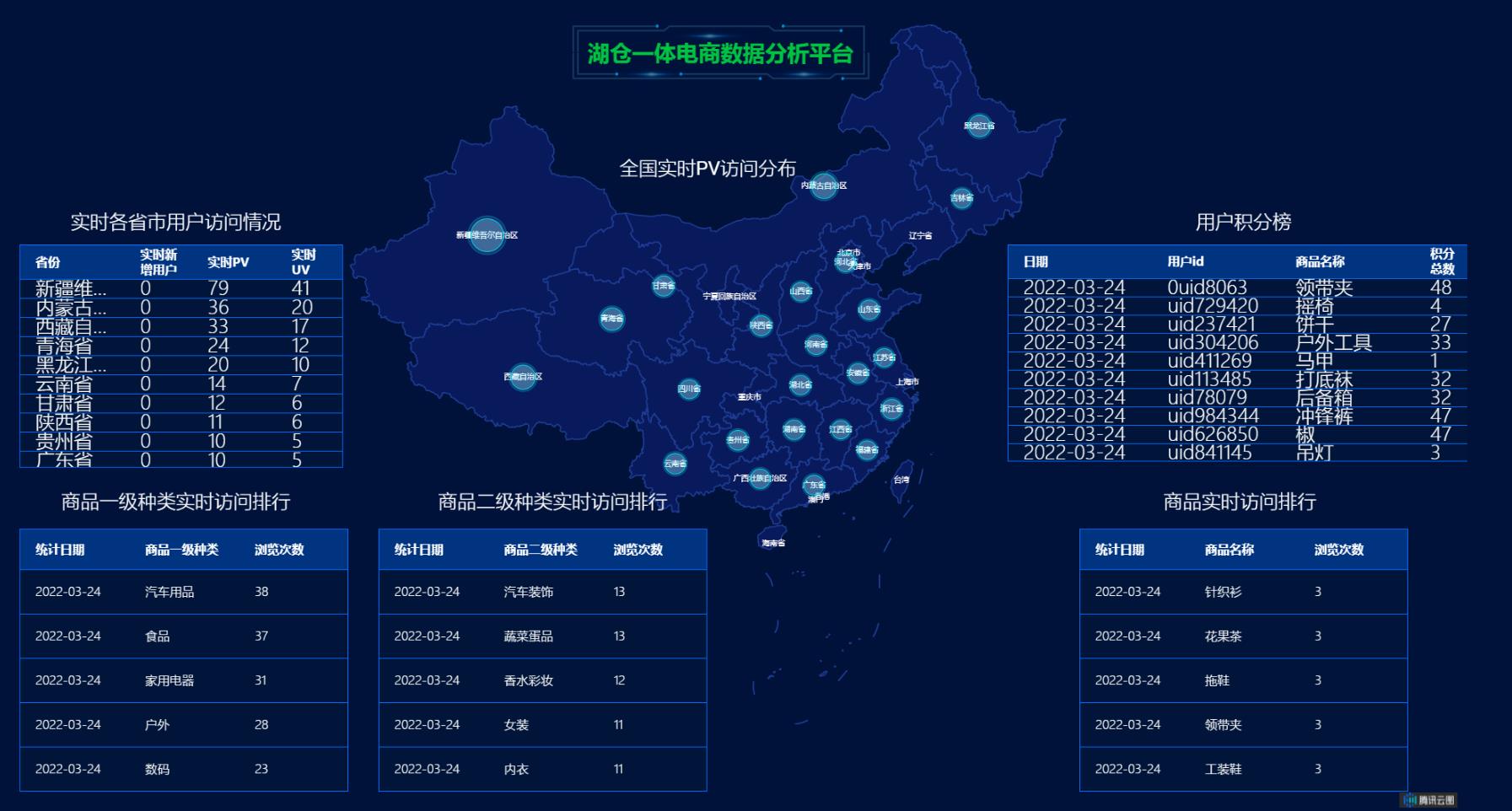
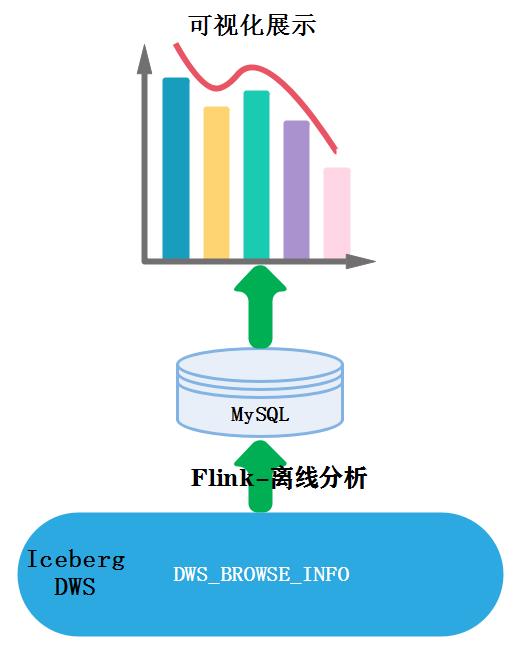
项目最终效果展示:
项目部分业务分层设计实现:

- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于数据湖及湖仓一体化项目学习框架的主要内容,如果未能解决你的问题,请参考以下文章
B站基于Iceberg+Alluxio助力湖仓一体项目落地实践