搞 AI 建模预测都在用 Python,其实入门用 SPL 也不错
Posted java李杨勇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搞 AI 建模预测都在用 Python,其实入门用 SPL 也不错相关的知识,希望对你有一定的参考价值。
可以用来做人工智能建模预测的工具非常多,比如Python, R, SAS,SPSS等,其中Python由于简单易学、丰富的数据科学库、开源免费等特点备受欢迎。但是对于不太熟悉数据建模算法的程序员来说,使用Python建模还是比较复杂,很多时候拿到数据并不清楚该做怎样的处理,选择什么样的算法。其实,在做数据分析和数据建模时,SPL也是不错的选择,它比Python更简单易用,计算速度也快,交互式的界面对数据分析十分友好,同时还提供自动数据建模功能和一些数据处理以及统计学函数,用起来也很方便。
下面就以一份用户贷款违约预测的数据为例,使用SPL手把手的进行数据建模预测。
1. 确定目标,准备数据
建模预测就是从历史数据中挖掘出规律,然后使用规律对未来可能发生的事情做出预测。这个规律就是一般所说的模型。
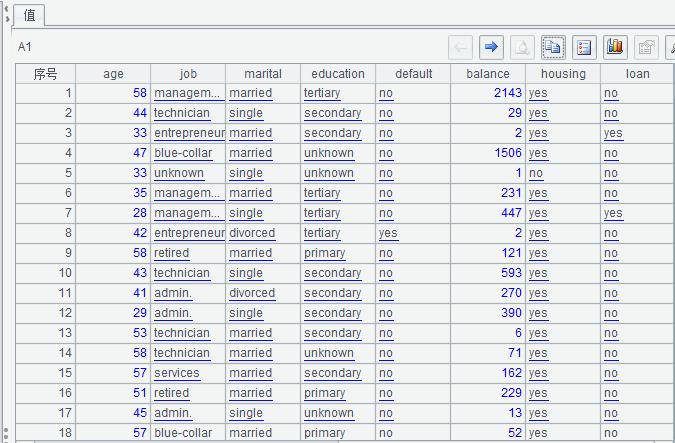
历史数据通常是一张我们俗称的宽表,比如在用户贷款违约预测的例子中历史数据是如下图这样的Excel表格: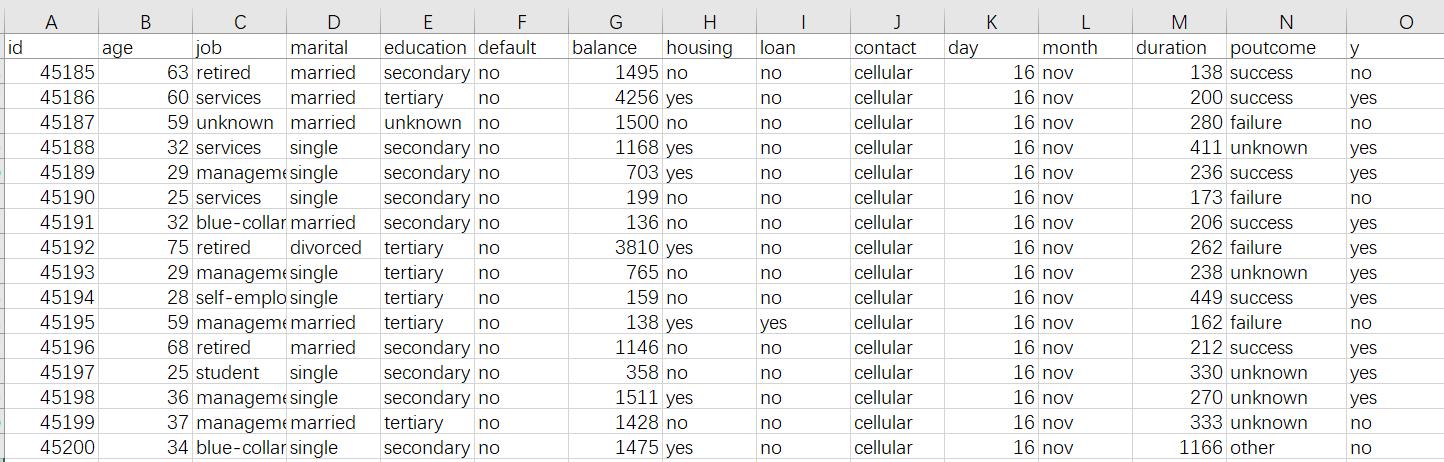
首先,宽表中一定要包括我们想预测的事情,通常称作预测目标,上图中的预测目标就是历史用户的违约行为,也就是图中y那一列,yes表示违约,no表示不违约。预测目标还可以是一个数值,比如产品的销量、售价……,或者是预测属于什么种类,比如预测产品质量是优、良、合格还是差。有时目标在原始数据里就有,可以直接使用,有时目标还需要人工标注。
除了预测目标外,这里还需要很多信息,如表中的用户年龄、工作,房产,贷款情况……,这里的每一列称为变量,也就是和贷款人将来是否违约可能会相关的信息,原则上能收集到的变量越多越好。例如预测客户是否会购买产品,可以搜集客户的行为信息,购物偏好,以及产品的特征信息,促销力度等;预测汽车保险理赔风险,需要保单数据,车辆信息、车主交通习惯以及历史理赔情况等等,如果是预测健康险还需要一些被保人的生活习惯,身体状况,就医看病的信息;预测商场超市的销售情况,需要历史的销售订单,客户信息,商品信息;预测不良产品,需要生产的工艺参数,环境,原料情况等数据。总之,收集到的相关信息越多,预测效果也会越好。
采集数据时,通常会截取某一段时期的历史数据来制作宽表,比如我们想预测7月份用户的违约情况,可以采集1-6月份的数据来训练建立模型。数据采集的时间范围并不是固定的,可以灵活操作,例如也可以是近1年或者近3个月等等。
准备好的宽表可以是Excel格式或csv格式,第一行是标题,后面每一行都是一条历史记录。
如果企业有建设好的信息系统,那可以找IT部门要这些数据,很多企业的BI系统中可以直接导出这种数据。
2. 下载软件,配置建模外部库
SPL 在易明建模外部库的配合下可以提供全自动化的建模预测功能。
(1)下载安装集算器(SPL)和易明建模软件
集算器下载:
“http://c.raqsoft.com.cn/article/1595816810031”
易明建模下载: “http://www.raqsoft.com.cn/download/download-ymodel”
安装集算器和建模软件,并记录安装目录,比如:C:\\Program Files\\raqsoft\\ymodel
(2)在SPL中配置外部库
(a)复制外部库所需要的文件
在易明建模的安装目录下找 YModelCil 和 lib 文件夹
然后去这两个文件夹里找到建模外部库所需要的文件,复制到集算器目录(【安装根目录】\\esProc\\extlib\\YModelCil),比如C:\\Program Files\\raqsoft\\esProc\\extlib\\YModelCli。
建模外部库所需的文件有:
1>易明建模目录的YModelCil中含有以下jar和xml
ant-1.8.2.jar
commons-beanutils.jar
commons-lang-2.6.jar
ezmorph-1.0.2.jar
json-lib-1.1-jdk13.jar
raq-ymodel-cli-2.10.jar
userconfig.xml
2>易明建模的lib中含有以下jar
commons-io-2.4.jar
esproc-ext-20211104.jar
fastjson-1.2.58.jar
gson-2.8.0.jar
jackson-annotations-2.9.6.jar
jackson-core-2.9.6.jar
jackson-databind-2.9.6.jar
jackson-databind-2.9.6-sources.jar
jackson-dataformat-msgpack-0.8.14.jar
mining.jar
msgpack-0.6.12.jar
msgpack-core-0.8.16.jar
(b)设置userconfig.xml文件参数
在集算器目录esProc\\extlib\\YModelCil下的userconfig.xml文件中设置参数
| 名称 | 参数说明 |
| sAppHome | 易明建模的安装目录 |
| sPythonHome | 易明建模目录的Python路径 Windows: raqsoft\\ymodel\\Python37 Linux: raqsoft/ymodel/Python37/bin/python3.7 |
| iPythonServerPort | Python服务网络端口 |
| iPythonProcessNumber | Python进程数 |
| bAutoDecideImpute | 是否智能补缺 |
| iResampleMultiple | 重抽样次数 |
其中必须要配置的参数为sAppHome和sPythonHome,其他参数可以采用默认值,有需要再进行修改。比如可以配置参数如下,加粗部分是必须要配置的,根据自己的安装路径。
<?xml version="1.0" encoding="UTF-8"?>
<Config Version="1">
<Options>
<Option Name="sAppHome" Value="C:\\Program Files\\raqsoft\\ymodel"/>
<Option Name="sPythonHome" Value="C:\\Program Files\\raqsoft\\ymodel\\Python37\\python.exe"/>
<Option Name="iPythonServerPort" Value="8510"/>
<Option Name="iPythonProcessNumber" Value="2"/>
<Option Name="bAutoDecideImpute" Value="true"/>
<Option Name="iResampleMultiple" Value="150"/>
</Options>
</Config>
其实,从这里可以看出,易明建模也是基于Python写的,但它将Python算法做了封装后,程序员就不必再理解算法的数学原理和运行细节了。
(c)SPL环境配置
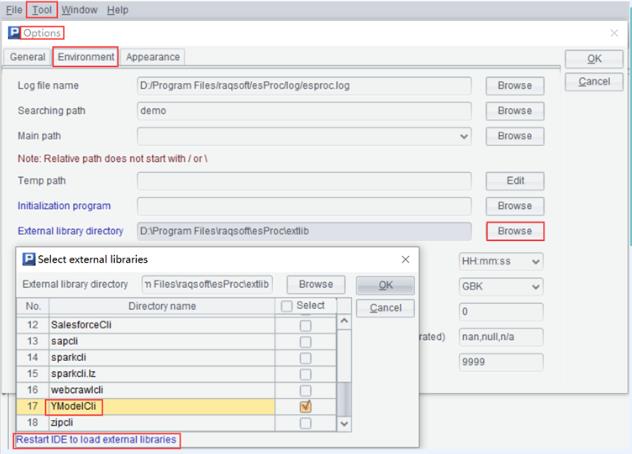
1>. 配置外部库
打开SPL,在选项菜单里,外部库选择里勾选YModelCli,使其生效。外部库的路径为第(1)步骤中集算器YModelCli的安装路径。
在无图形界面的服务器中去集算器的安装目录下esProc\\config\\raqsoftConfig.xml文件中进行配置外部库路径和名称。
<extLibsPath>外部库路径
<importLibs>外部库名称(可多个)
2>. 线程数设置
如果有并发预测,还需要在SPL设置“最大并行数”,也就是线程数。设置多少用户根据需求和机器情况自行设定。
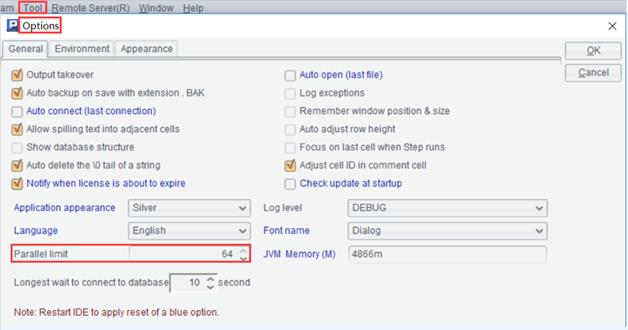
在无图形界面的服务器中去集算器的安装目录下esProc\\config\\raqsoftConfig.xml文件中进行配置。
<parallelNum>最大并行数
到此,环境配置完成。
3. 建模和预测
(1)加载数据
SPL能支持csv,excel或数据库中的数据用于建模,这里以csv为例,其它数据源类似。
设有一个贷款违约数据表如下,需要建模来预测新用户是否会发生违约行为。
文件命名为bank-full.csv;
| A | |
| 1 | =file("bank-full.csv").import@tc() |
| 2 | =ym_env() |
| 3 | =ym_model(A2,A1) |
A1 导入建模数据,读成序表
A2 初始化环境,执行A2后会在易明建模的安装目录下生成store目录及子目录用以保存数据及结果文件。
A3 加载建模文件,生成md对象
(2)目标变量设置和变量统计
数据加载进来后要设置目标变量
| A | |
| … | … |
| 4 | =ym_target(A3,"y") |
| 5 | =ym_statistics(A3,"age") |
| 6 | =A1.fname().(ym_statistics(A3,~)) |
A4 表示将字段“y”设置为目标变量,目标变量可以是二值变量或数值型变量。
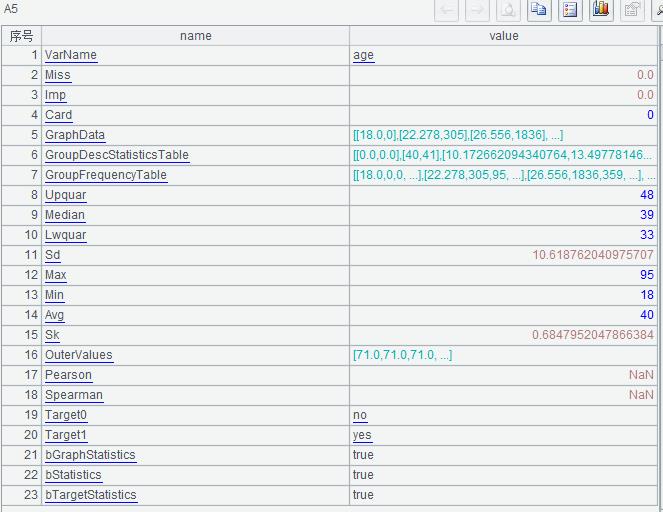
A5 查看某个变量的统计指标,比如 “age”,返回值中可以看到缺失率,最大最小值,异常值,数据分布图等参数。
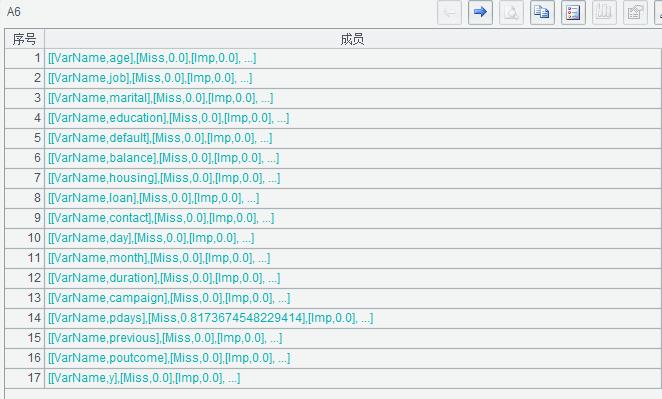
A6 循环变量名查看所有字段的统计信息,返回包含所有字段的统计信息二级序列。
(3)建立模型和模型表现
| A | |
| … | … |
| 7 | =ym_build_model(A3) |
| 8 | =ym_present(A7) |
| 9 | =ym_performance(A7) |
| 10 | =ym_importance(A7).sort@z(Importance) |
A7 使用建模函数建立模型,执行后在后台会进行全自动化数据预处理和建模过程,此过程会耗费一些时间,时间长短取决于数据量。结果返回pd模型对象。
模型建好后,可以调用pd模型对象查看模型信息、模型质量和重要度。
A8 返回模型AUC值及参数
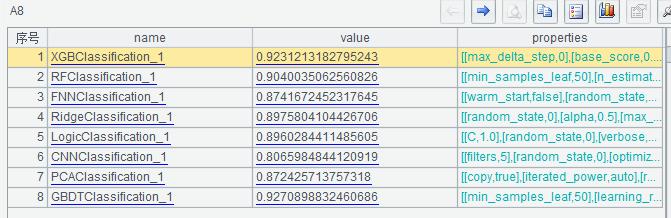
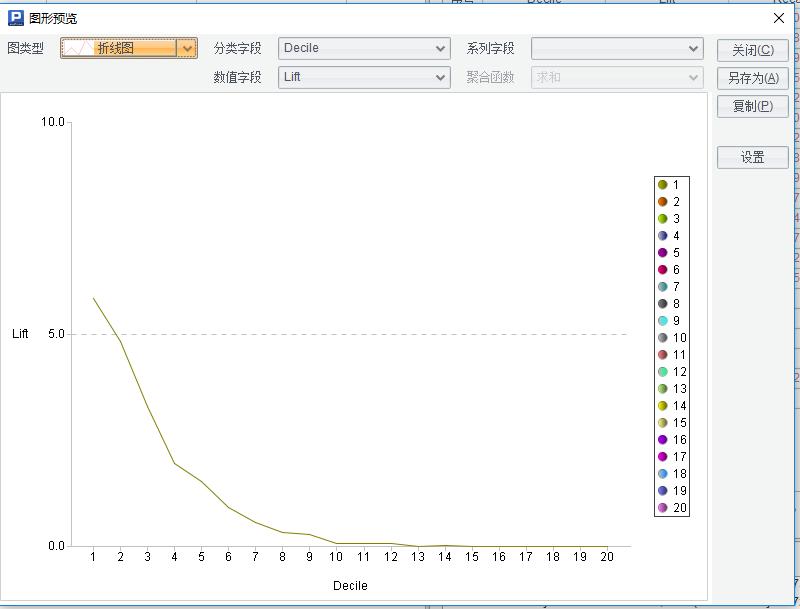
A9 返回多种模型指标和图形,诸如AUC,ROC, Lift……

比如点击A9的第6条记录的Value,然后点击右上角“图形浏览”图标,数值字段选择“Lift”,就可以查看Lift曲线
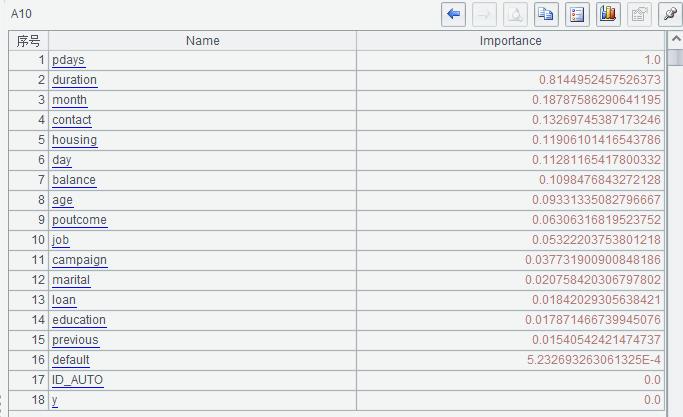
A10 会返回每个变量对目标变量的影响程度并且按照重要度降序排列。数值越大对目标变量的影响程度越大。降序排列分析起来更加直观。
(4)保存模型
| A | |
| … | … |
| 11 | =ym_save_pcf(A7,"bankfull.pcf") |
| 12 | =ym_json(A7) |
| 13 | >ym_close(A2) |
A11 将模型保存为”bankfull.pcf”,默认保存路径为[sAppHome]/store/predict。
A12 将模型信息以json串形式返回。json内容详解可参考在线文档《json参数说明》
A13 关闭环境,释放资源。
(5)预测
预测之前需要有pcf模型文件和预测数据集
| A | |
| 1 | =ym_env() |
| 2 | =ym_load_pcf("bankfull.pcf") |
| 3 | =file("bank-full2.csv").import@tc() |
| 4 | =ym_predict(A2,A3) |
| 5 | =ym_result(A3) |
| 6 | =file("bank-full_result.csv").export@tc(A4) |
| 7 | >ym_close(A1) |
A1 初始化环境
A2 导入pcf模型文件,生成pd模型对象。
A3 导入预测数据集,读成序表
A4 对序表数据执行预测。除序表外,还支持游标、csv文件和mtx文件,比如A4也可以直接写成ym_predict(A2,“bankfull2.csv”)
A5 获取预测结果
A6 将预测结果导出,在本例中预测结果为用户发生违约行为的概率。

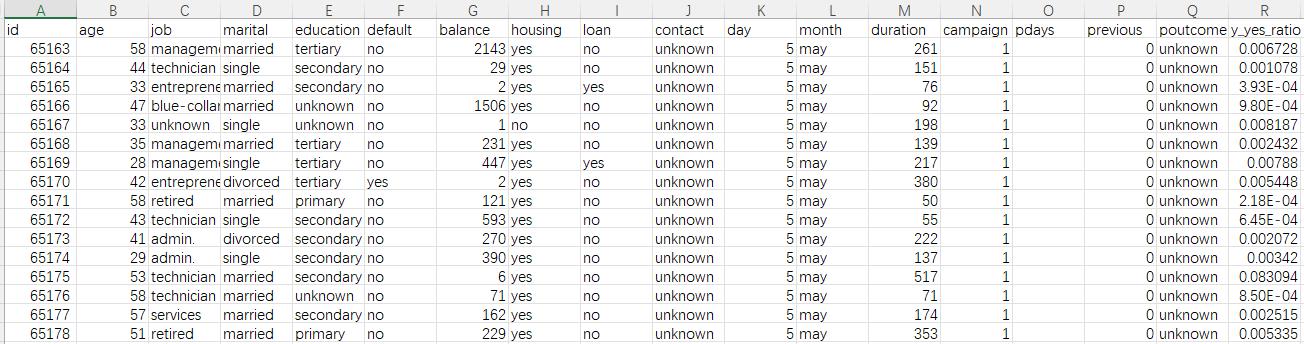
A7 关闭环境,释放资源
4. 集成调用
SPL还可以被上层应用集成调用,比如SPL可以嵌入到Java应用,详情请参考:http://c.raqsoft.com.cn/article/1615765346560
总结
使用SPL配合易明建模来实现数据建模预测非常简单,程序员不需要理解深奥的数学原理,只要准备好训练数据,简单几步就可以完成数据建模任务了。而且还可以轻松地把这个功能嵌入到应用程序中,高深的人工智能不再是少量数据科学家的专利。
SPL本来就超强的数据处理能力,能更方便地完成人工智能算法之前的数据准备工作,同时也提供了丰富的数学函数: SPL Math 例程,有些数学基础想自己实现建模过程的同学也可以进一步研究。
以上是关于搞 AI 建模预测都在用 Python,其实入门用 SPL 也不错的主要内容,如果未能解决你的问题,请参考以下文章
AI转行搞医学:用自然语言处理算法预测病毒的免疫逃逸 | Science