测试环境不稳定&复杂的必然性及其对策
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了测试环境不稳定&复杂的必然性及其对策相关的知识,希望对你有一定的参考价值。

这篇文章想要讲的,的确是两件事情:
- 为什么测试环境的不稳定是必然的,怎么让它尽量稳定一点?
- 为什么测试环境比生产环境更复杂,怎么让它尽量简单一点?
此外,还会谈一谈对测试环境和生产环境的区别的理解。
这里是本文的主要观点:
- 测试环境与生产环境是两个不同的场景,测试环境的不稳定是必然的,在没有实现TiP(Test in Production)之前,当前我们能做的是尽量让它稳定一点;
- 测试环境比生产环境更为复杂,最核心的是要解决共振问题,即做好隔离能力,Mesh 是解决隔离问题的一个未来方向;
在 DevOps 领域,测试环境其实是介于 Dev 和 Ops 中间重叠的部分,一提到测试环境,打开就会说测试环境不够用、测试环境不稳定,尤其是在微服务化了之后,对测试环境的诉求与挑战也愈发明显。

从软件研发过程的角度来说(如上图),从左往右呈现一个漏斗模型,随着研发的阶段推进,复杂度和稳定性都在逐步收敛:
- 在开发和集成阶段,代码等变更是非常频繁的,在这个阶段里研发人员在不断的迭代、联调、验证等,从本质上来说,高复杂度和低稳定性是必然的,对于依赖的中间件等基础设施的不稳定,这是偶然的;
- 到了预发、灰度和发布阶段,变更已经趋于稳定,经过了前面阶段的洗礼,复杂度是相对低的,稳定性也能得到保证;

另一方面,如上图所示,生产环境只有一套,链路和应用间的调用关系比较清晰,但在测试环境中,因为涉及到多个项目的自测、联调、验证等,相当于千军万马过独木桥,很容易产生共振效应,影响所有人的研发,在这方面来讲,测试环境比生产环境要复杂很多,亟需解决隔离、低成本以及稳定的依赖这几个重要的问题。
测试环境不稳定的必然性
测试环境和生产环境的区别是什么?有的人说线下的容量没有线上大,有的人说线下没有真实用户,有的人说线下缺少生产的真实数据,等等,各种答案都有。在我看来,测试环境和生产环境的本质区别是:它们是两个不同的场景。对于生产环境,准确与稳定性最重要;对于测试环境,隔离、低成本和稳定的依赖最重要。
在日常的研发中,会面临诸多场景,涉及的测试环境总结如下:
- 开发环境(dev):开发或测试同学自己的电脑或服务器,非 Aone 管理的应用服务器
- 项目环境(project):关联到某个变更的环境,仅部署该变更对应的分支
- 单应用测试
- 多应用联调
- 性能测试:对该变更对应的分支做性能测试
- 日常集成环境(daily):我们最熟悉的 daily 环境,可部署多个变更对应分支的合并代码
- 主干环境(testing-trunk):部署最新正式环境发布分支,即正式环境镜像 mirror of production
- 自动化测试环境(auto-testing):跑自动化测试用例的环境
- ... ...
大家经常吐槽测试环境的稳定性,提起不稳定的原因,经常会听到如下解释:
- 测试环境都是过保的机器而且超卖了,为了节省成本
- 生产有的配置,在测试环境没有,导致启动失败了
- 监控、告警等能力在测试环境没有配套
- 投入不够,不重视,对问题的响应不及时,流程机制等没建立起来
- ... ...
其实这些原因中大部分都不是本质问题。换句话说,即便狠狠的砸钱、砸人,即使机器不用过保机、硬件不超卖、工具建设好把配置监控自愈等和生产环境保持对齐、问题响应机制建立起来,测试环境也还是会不稳定的。
因为测试环境不稳定的根源在于:
- 测试环境里面有不稳定的代码
- 测试环境不稳定带来的影响小
测试环境比生产环境更复杂
如上文所说,生产环境只有一套,链路和应用间的调用关系比较清晰,服务也相对比较稳定,但在测试环境中,因为涉及到并行研发,服务间的依赖会变得很复杂,比如 A 对 B 强依赖,那么 A 的功能是否成功取决于 B,而且 B 变化了之后,也要保证不影响 A。
首先是环境创建,此处的“环境创建”指的并不只是通过 yaml 创建出一台 pod 部署应用这么简单,而是创建出一套“可测”的环境,“可测”的准则包括:服务可用、链路联通(包括上下游的服务)、请求隔离等。
随着分布式系统的演进,微服务的数量也呈指数级增长,整个系统的复杂度也会随之升级。这些“微服务”可能单个服务很简单,但是交互建立起的系统将成为复杂性的瓶颈,很有可能成为一个复杂的地狱。
我们以一个简单的样例来说明:
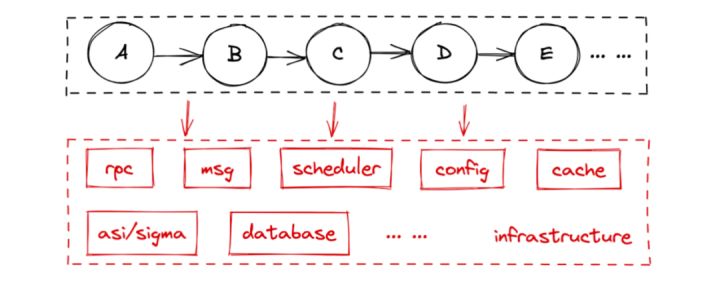
一条链路上有上百的应用数,其中两个应用 A 与 B 有变更,我们想一想,如果只创建了包含两个单应用的环境,那么能不能满足“可测”条件?我们会面临如下诸多问题:
- 需要将链路上所有的应用都创建一套环境才能将链路跑通,谁能清楚整条链路上的应用?
- 多个项目/变更,每次都将整条链路上的应用重新创建一套环境?维护和排查成本如何?
- 多套环境,势必会带来并行干扰的问题,如何将请求准确的路由到期望的服务上?
- 同一套中间件、数据库等基础设施如何软隔离?
表面上我们只是为某个应用创建了项目环境,实际上背后涉及了一整套环境复用与隔离方案,水静流深。
而对于这种场景,生产环境(预发、正式等)之间首先是物理隔离(预发与正式是两套独立的中间件),其次是只需要一套环境即可满足,不存在并行的问题。
怎么让测试环境尽量稳定和简单一点
“测试环境的复杂度”,归根到底,无外乎来自于三个地方:
- 环境的复用
- 环境的隔离
- 环境的稳定性(主干环境)
我们先来梳理两个业务视角:
- 上层业务平台视角:对于上层业务而言,他们的痛点及诉求是希望是底层的中台能更加稳定
- 中台视角:对于中台而言,除了给上层业务提供服务外,自身还有集成诉求
环境复用
站在一个项目中的开发同学的角度,他通常只需要为有变更的应用创建环境即可,其余的应用都复用一套兜底的环境,如下图所示,这就是项目环境+主干环境模式:
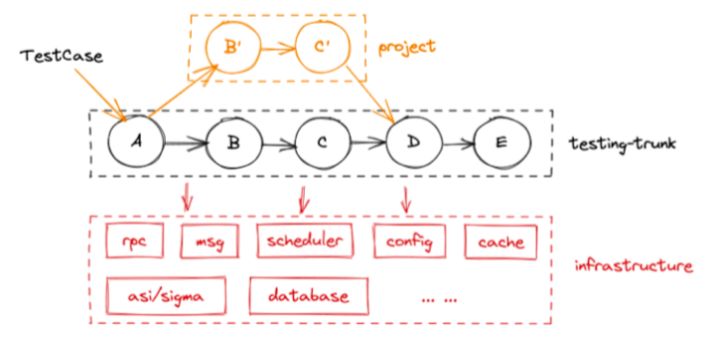
- 有一个主干环境,主干环境之上“挂着”若干个项目环境
- “主干环境”,跑的是和正式环境的版本相同的代码,每次生产环境发布后,主干环境也会同步更新
- “项目环境”,每个项目有自己的项目环境,部署的是项目的分支代码,这个项目上的同学就在这个项目环境里做测试联调(集成)
- 项目环境不是全量的,例如,交易链路一共有一百个左右的应用,它的主干环境是全量的,但项目环境只包含这个项目涉及的应用,测试发起的流量会被路由机制从主干环境的应用路由到项目环境的应用
除了项目环境+主干环境模式,还有一种日常集成环境模式,如下图所示:
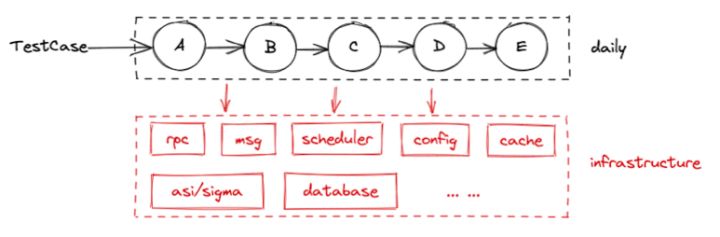
对不变的服务或基础设施进行复用后,搭建环境无论是从资源成本还是从复杂度上都得到了极大的降低。
环境隔离
当对环境复用之后,势必会带来并行干扰的问题,就需要对环境进行隔离来解决,将请求准确的路由到期望的服务。
隔离大致分为以下几类:
- 服务隔离(RPC)
- 中间件隔离(消息、配置、缓存等)
- 数据库隔离
- HTTP 流量隔离(无线端 + PC 端)
以服务隔离为例,如下图,当多个项目并行研发时,对于不同的环境如何做到之间互相不干扰时需要解决的问题:
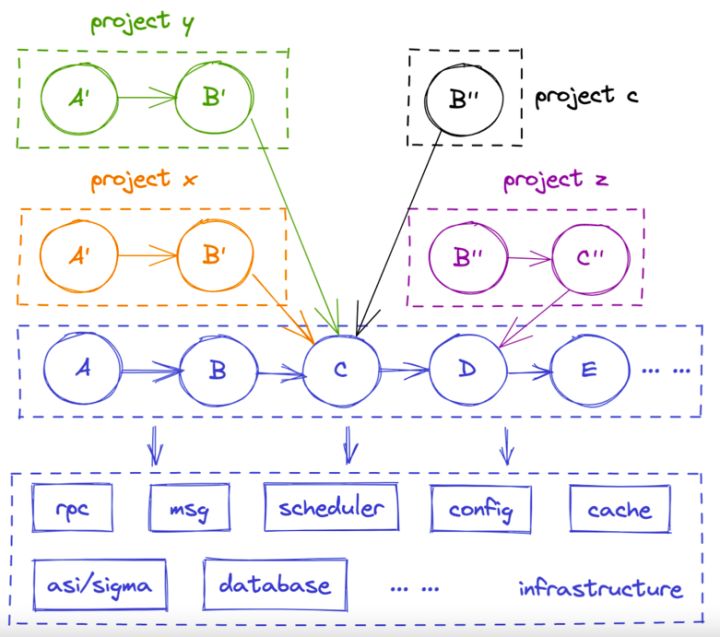
未来的方向:通过 Service Mesh 实现隔离
Service Mesh 的权威定义如下:
“A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.”
用一句话来总结就是,Service Mesh 是一组用来处理服务间通讯的网络代理,如下图:
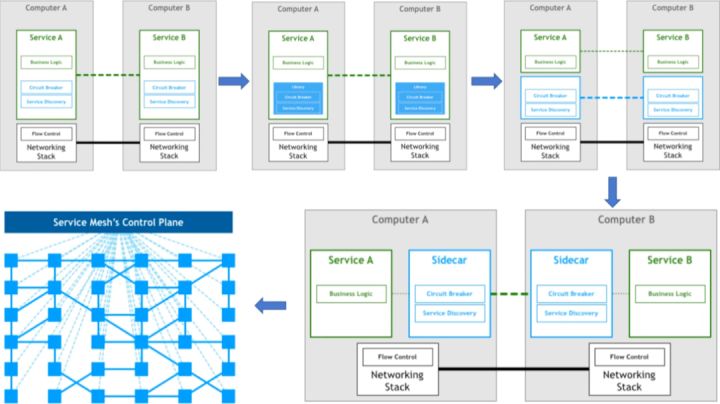
从上图可以看到,Sidecar 接管了网络的控制权,在隔离的场景下,所有的事情都可以在 Sidecar 内完成。
使用 Service Mesh 实现隔离有如下优点:
- 对应用本身无侵入
- 适配多种协议(web socket、rpc 等)、多种中间件(消息、配置、DB 等)
- 屏蔽了技术栈的差异
- 升级对应用本身无影响
环境稳定性
环境的稳定性对应着如下的金字塔模型,越往下层,稳定性越需要保障,以一个经典的案例为例,如果每一层的稳定性只有 99%,那么 0.99 ^ 4 = 0.96,随着影响因素的增多,整体稳定性就会被放大,如 0.99 ^ 365 = 0.03,所以每一层的稳定性都很重要,都必须 100%,或者至少应该是“五个9”,这样整体的稳定性才有可能提高。
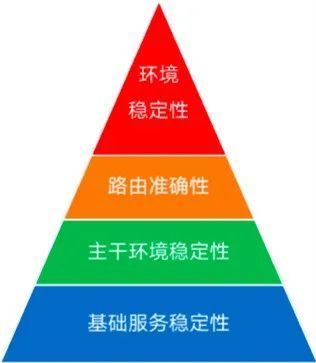
基础服务稳定性
这个的基础服务包括基础设施、中间件和数据库,虽然是测试环境的基础服务,但需要按照生产级的标准进行保障,因为基础服务抖一抖,对于上层服务来说可以说是地震。
测试环境可以说没什么可用的基础平台,由于生产环境与测试环境的不同,导致很多生产的监控、排查工具、运维平台在测试环境都没有运行,因此需要建设可以被使用的工具来保障基础服务的稳定性。
首先对于基础服务而言,需要建立系统 SLI/SLO 监控指标,稳定性必须达到 100%,或者至少应该是“五个9”。其次需要建立快恢机制,及时止血,做到 “1-5-10”,即 1 分钟发现,5 分钟定位,10 分钟恢复。
主干环境稳定性
今天我们研发同学的心智是:当一个同学在测试遇到错误的时候,他的第一反应是“一定是环境问题”。也就是说,他的第一反应是“别人的问题”,只有当“别人的问题”都排出后他才会认真的去看是不是他自己的问题(包括项目的问题)。
主干环境的稳定性治理,最终就是在做一道证明题:拿出数据来,证明主干环境是稳定的。所以,如果有问题,请先排查你的项目。
证明主干环境是稳定的数据分两类,单应用和链路:
- 单应用就是像健康检查和 RPC 检查这类,它验证的是单个应用是可用的,不管业务逻辑对不对,不管配置对不对,至少这个应用、这个服务、这个微服务是正常启动且运行的。单应用稳定性必须达到100%,或者至少应该是“五个9”。这个要求是合理的,因为单应用的稳定性是链路稳定性的基础。如果单应用都没有正常启动且运行,链路功能的可用和正确性就根本无从谈起;

- 链路的稳定性,说白了就是跑脚本、跑测试用例。频率是分钟级也可以,小时级也可以。验证链路的脚本是需要不断的补充丰富的,当发生了一个主干环境的问题但是验证脚本没有发现,就要把这个问题的场景补充到链路验证脚本(测试用例)里面去。也可以借用测试用例充分度的度量手段(例如,行覆盖率、业务覆盖率等等),主动的补充链路验证脚本。很多其他测试用例自动生成的技术也可以用上来;
最后,达到的效果就是:用数据说话。用很有说服力的数据说话:主干环境的单应用都是好的,链路也都是能跑通的,这时候出现了问题,就应该先怀疑是项目环境的问题。
路由准确性
对于隔离而言,一旦路由调飞,一方面用户想验证的功能没有验证到,另一方面排查成本也是极其高的,每次排查至少需要半小时起步。
路由准确性的治理,最终也是在做一道证明题:拿出数据来,证明路由逻辑是准确的,包括隔离插件、隔离配置等。所以,如果有问题,请先排查你的服务。
证明路由是准确的数据分两类,隔离插件覆盖和隔离数据同步:
- 隔离插件覆盖就是保证所有需要隔离的机器上都安装了隔离插件,如 HSF 隔离插件、MetaQ 隔离插件等,不管路由逻辑对不对,如果没有安装隔离插件,必然是会调飞的(随机调用)。隔离插件的覆盖率必须达到100%,或者至少应该是“五个9”。这个要求是合理的,因为隔离插件是隔离的基础。如果隔离插件都没有正常安装,隔离的可用和正确性就根本无从谈起;
- 隔离数据同步就是保证隔离数据的正确性以及同步的效率,如 服务上是否打上了隔离标签、消息是否带上了隔离标签,当环境创建或者变更完成后,隔离数据是否会立即生效,隔离数据同步的效率必须是秒级,同步的成功率必须达到100%,或者至少应该是“五个9”。隔离数据同样是隔离的基础,隔离插件以及整个隔离体系的逻辑都是围绕着隔离数据展开的;
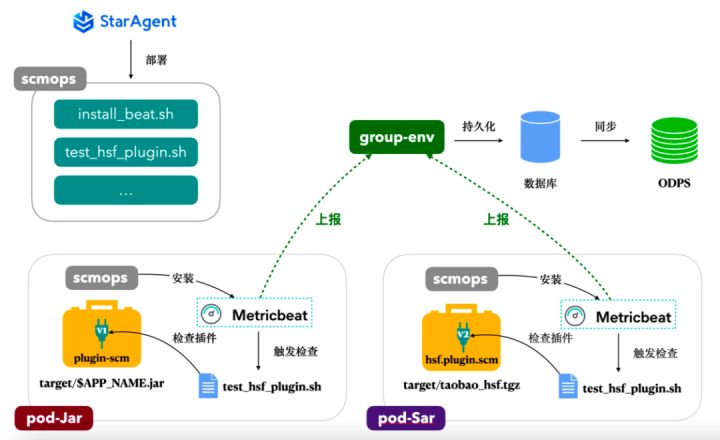
我们通过 StarAgent 在测试环境的每台机器上部署 Metricbeat 采集代理,采集插件安装情况、服务健康检查情况等,分钟级上报 5w+ 机器的巡检数据,并在出现问题后及时自愈:
结语
关于本文的结论,总结如下:
- 测试环境与生产环境是两个不同的场景,测试环境的不稳定是必然的,在没有实现TiP(Test in Production)之前,当前我们能做的是尽量让它稳定一点;
- 测试环境比生产环境更为复杂,最核心的是要解决共振问题,即做好隔离能力,Mesh 是解决隔离问题的一个未来方向;
聊现在谈未来:
我们希望将环境一站式/沉浸式的产品体验,覆盖整个联调验证的生命周期,提供从环境搭建到回归验证的全方位服务,局部的试点优化及改进能形成全局计划,总结出的方法论与工具能逐步覆盖到全局,使得联调问题往正向循环发展,最终全面解决联调效能问题。
参考:
1. 《Pattern: Service Mesh》
2. 《What Is a Service Mesh?》
作者 | 史培培(安辰)
本文为阿里云原创内容,未经允许不得转载
以上是关于测试环境不稳定&复杂的必然性及其对策的主要内容,如果未能解决你的问题,请参考以下文章