目标检测YOLOv5跑xView数据集/小样本检测策略实验
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测YOLOv5跑xView数据集/小样本检测策略实验相关的知识,希望对你有一定的参考价值。
前言
在YOLOv5的6.1版本新出了xView.yaml数据配置文件,提供了遥感数据集xView的检测方法。此篇就使用YOLOv5来试跑xView数据集,并对一些小样本检测的策略进行消融实验。
xView数据集下载:https://github.com/zstar1003/Dataset
数据预处理
在YOLOv5的xView.yaml文件中,提供了xView数据集的预处理方式。
这里单独新建一个脚本文件xView.py
import json
import os
from pathlib import Path
import numpy as np
import yaml
from PIL import Image
from tqdm import tqdm
from utils.datasets import autosplit
from utils.general import download, xyxy2xywhn
def convert_labels(fname=Path('xView/xView_train.geojson')):
# Convert xView geoJSON labels to YOLO format
path = fname.parent
with open(fname) as f:
print(f'Loading fname...')
data = json.load(f)
# Make dirs
labels = Path(path / 'labels' / 'train')
os.system(f'rm -rf labels')
labels.mkdir(parents=True, exist_ok=True)
# xView classes 11-94 to 0-59
xview_class2index = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, -1, 3, -1, 4, 5, 6, 7, 8, -1, 9, 10, 11,
12, 13, 14, 15, -1, -1, 16, 17, 18, 19, 20, 21, 22, -1, 23, 24, 25, -1, 26, 27, -1, 28, -1,
29, 30, 31, 32, 33, 34, 35, 36, 37, -1, 38, 39, 40, 41, 42, 43, 44, 45, -1, -1, -1, -1, 46,
47, 48, 49, -1, 50, 51, -1, 52, -1, -1, -1, 53, 54, -1, 55, -1, -1, 56, -1, 57, -1, 58, 59]
shapes =
for feature in tqdm(data['features'], desc=f'Converting fname'):
p = feature['properties']
if p['bounds_imcoords']:
id = p['image_id']
file = path / 'train_images' / id
if file.exists(): # 1395.tif missing
try:
box = np.array([int(num) for num in p['bounds_imcoords'].split(",")])
assert box.shape[0] == 4, f'incorrect box shape box.shape[0]'
cls = p['type_id']
cls = xview_class2index[int(cls)] # xView class to 0-60
assert 59 >= cls >= 0, f'incorrect class index cls'
# Write YOLO label
if id not in shapes:
shapes[id] = Image.open(file).size
box = xyxy2xywhn(box[None].astype(np.float), w=shapes[id][0], h=shapes[id][1], clip=True)
with open((labels / id).with_suffix('.txt'), 'a') as f:
f.write(f"cls ' '.join(f'x:.6f' for x in box[0])\\n") # write label.txt
except Exception as e:
print(f'WARNING: skipping one label for file: e')
# Download manually from https://challenge.xviewdataset.org
dir = Path('D:/Dataset/Xview') # dataset root dir
# urls = ['https://d307kc0mrhucc3.cloudfront.net/train_labels.zip', # train labels
# 'https://d307kc0mrhucc3.cloudfront.net/train_images.zip', # 15G, 847 train images
# 'https://d307kc0mrhucc3.cloudfront.net/val_images.zip'] # 5G, 282 val images (no labels)
# download(urls, dir=dir, delete=False)
# Convert labels
convert_labels(Path('D:/Dataset/Xview/xView_train.geojson'))
# Move images
images = Path(dir / 'images')
images.mkdir(parents=True, exist_ok=True)
Path(dir / 'train_images').rename(dir / 'images' / 'train')
Path(dir / 'val_images').rename(dir / 'images' / 'val')
# Split
autosplit(dir / 'images' / 'train')
运行之后,在train文件夹里会新增训练集和验证集的划分文件。
注:xView数据集没有提供测试集,并且其验证集没有标签,因此这里在train中划分出训练集和验证集。
训练配置
训练和之前跑VOC的流程类似,首先需要修改配置文件路径myxView.yaml
train: D:/Dataset/Xview/images/train/autosplit_train.txt # train images (relative to 'path') 90% of 847 train images
val: D:/Dataset/Xview/images/train/autosplit_val.txt # train images (relative to 'path') 10% of 847 train images
# Classes
nc: 60 # number of classes
names: ['Fixed-wing Aircraft', 'Small Aircraft', 'Cargo Plane', 'Helicopter', 'Passenger Vehicle', 'Small Car', 'Bus',
'Pickup Truck', 'Utility Truck', 'Truck', 'Cargo Truck', 'Truck w/Box', 'Truck Tractor', 'Trailer',
'Truck w/Flatbed', 'Truck w/Liquid', 'Crane Truck', 'Railway Vehicle', 'Passenger Car', 'Cargo Car',
'Flat Car', 'Tank car', 'Locomotive', 'Maritime Vessel', 'Motorboat', 'Sailboat', 'Tugboat', 'Barge',
'Fishing Vessel', 'Ferry', 'Yacht', 'Container Ship', 'Oil Tanker', 'Engineering Vehicle', 'Tower crane',
'Container Crane', 'Reach Stacker', 'Straddle Carrier', 'Mobile Crane', 'Dump Truck', 'Haul Truck',
'Scraper/Tractor', 'Front loader/Bulldozer', 'Excavator', 'Cement Mixer', 'Ground Grader', 'Hut/Tent', 'Shed',
'Building', 'Aircraft Hangar', 'Damaged Building', 'Facility', 'Construction Site', 'Vehicle Lot', 'Helipad',
'Storage Tank', 'Shipping container lot', 'Shipping Container', 'Pylon', 'Tower'] # class names
之后在train.py中修改对应的weights、cfg、data等参数。
小样本检测策略实验
起初我使用默认的640x640的img-size,但是在这种小样本的检测中,效果很糟。
于是我将img-size的尺寸改成1280x1280,使用官方提供的yolov5l6.pt这个预训练模型训练100个epoch。
测试得到的AP50为0.847%。
下面我输入验证集中的2618.tif这张图片来进行检测。
我想到了之前学习过的【目标检测】YOLOv5针对小目标检测的改进模型中的小样本检测策略,正好在此次也加入测试。
detect.py中的改进代码如下所示:
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0] # Size:[1, 15120, 11] [1, num_boxes, xywh+obj_conf+classes]
'''
此处进行分块预测改进
'''
mulpicplus = "3" # 1 for normal,2 for 4pic plus,3 for 9pic plus and so on
assert (int(mulpicplus) >= 1)
if mulpicplus == "1":
pred = model(img, augment=opt.augment)[0]
else:
# print(img.shape) # [1, 3, 3072, 5440]
xsz = img.shape[2]
ysz = img.shape[3]
"""
输入图片:1400x788
1400/640 = 2.1875
788/2.1875 = 360.2285..
384(32的整数倍)最接近360.2285..
因此输出:640x384
"""
# print(xsz) # img_size(640):384 img_size(5440):3072
# print(ysz) # img_size(640):640 img_size(5440):5440
mulpicplus = int(mulpicplus)
x_smalloccur = int(xsz / mulpicplus * 1.2) # 2倍:x_smalloccur:1843 3倍:1228 4倍:921
y_smalloccur = int(ysz / mulpicplus * 1.2) # 2倍:y_smalloccur:3264 3倍:2176 4倍:1632
# print(x_smalloccur)
# print(y_smalloccur)
for i in range(mulpicplus):
x_startpoint = int(i * (xsz / mulpicplus))
for j in range(mulpicplus):
y_startpoint = int(j * (ysz / mulpicplus))
x_real = min(x_startpoint + x_smalloccur, xsz)
y_real = min(y_startpoint + y_smalloccur, ysz)
if (x_real - x_startpoint) % 64 != 0:
x_real = x_real - (x_real - x_startpoint) % 64
if (y_real - y_startpoint) % 64 != 0:
y_real = y_real - (y_real - y_startpoint) % 64
dicsrc = img[:, :, x_startpoint:x_real, y_startpoint:y_real]
# print(dicsrc.shape) # 2倍:[1, 3, 1792, 3264] 3倍:[1, 3, 1216, 2176] 4倍: [1, 3, 896, 1600] 4倍(5760):[1, 3, 768, 1728]
# 可选,查看切片图片内容
# img2 = dicsrc.squeeze(0).cpu().numpy()
# img2 = img2.transpose((1, 2, 0))
# cv2.imshow('123', img2)
# cv2.waitKey(0)
pred_temp = model(dicsrc, augment=opt.augment)[0]
# print(pred_temp.shape)
"""
pred_temp[..., 0] 取最后一维度的第一个,也就是x
pred_temp[..., 1] 取最后一维度的第二个,也就是y
注意这里的y_startpoint和x_startpoint和从原图上看是相反的
"""
pred_temp[..., 0] = pred_temp[..., 0] + y_startpoint
pred_temp[..., 1] = pred_temp[..., 1] + x_startpoint
if i == 0 and j == 0:
pred = pred_temp
else:
pred = torch.cat([pred, pred_temp], dim=1) # 在维度1上进行叠加,也就是叠加
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
简单来说,这个优化策略就是对图像进行切块分别预测,为了防止切块时会把目标给切开,每块之间有20%的重合度。最后将所得到的预测框全部进行叠加,统一输入到NMS之中进行过滤。
下面是我的实验结果:
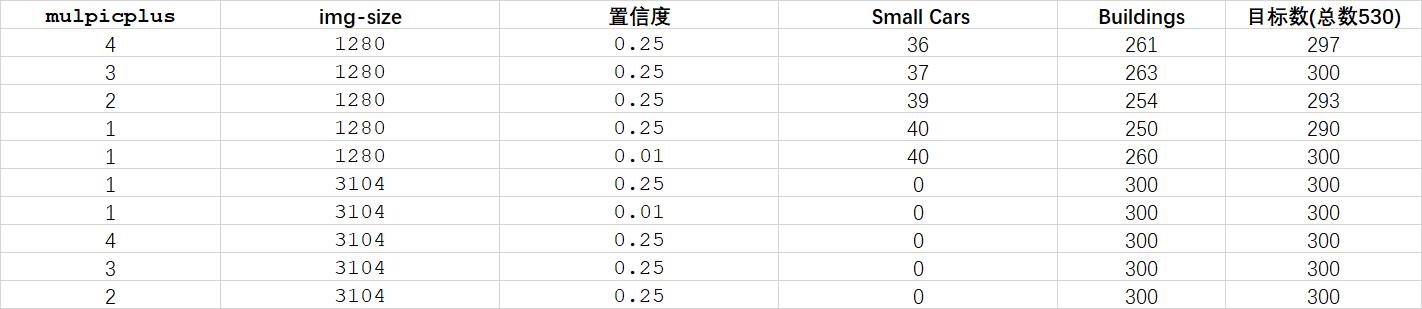
可以看到,这个切片检测策略一定程度上确实能够缓解漏检情况,不过对于这幅图来说提升并不显著。同时,我也使用了更大尺寸的输入图片尺寸,结果却使小样本丢失,而大样本检测效果更好。
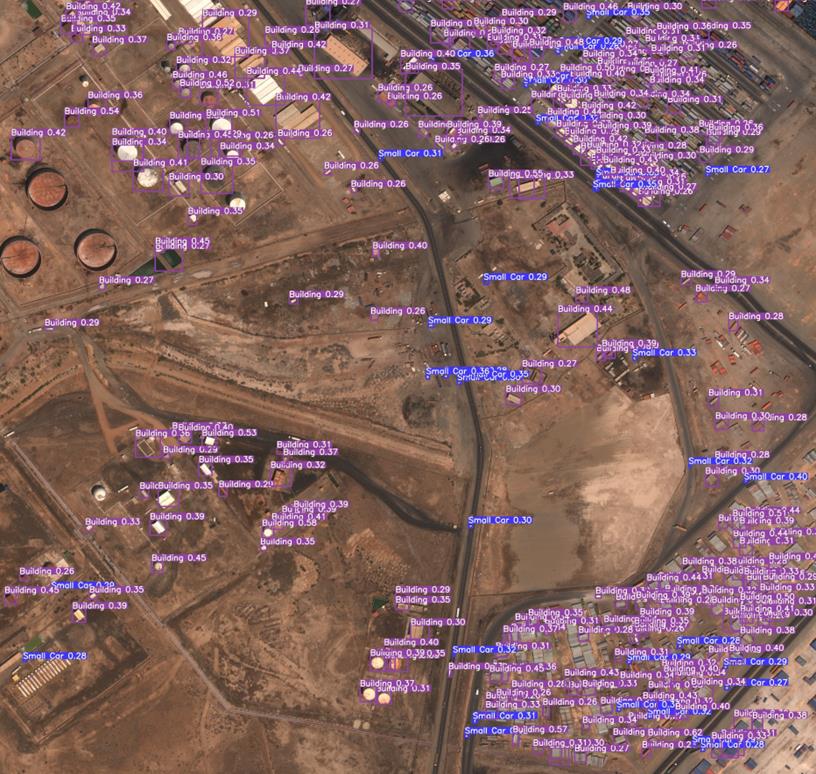
下面是可视化的展示结果:图一是原图标签可视化;图二是表中第二行结果;图三是表中最后一行结果。


以上是关于目标检测YOLOv5跑xView数据集/小样本检测策略实验的主要内容,如果未能解决你的问题,请参考以下文章
深度学习100例 | 第51天-目标检测算法(YOLOv5)
深度学习目标检测:YOLOv5实现车辆检测(含车辆检测数据集+训练代码)