阿里本地生活全域日志平台 Xlog 的思考与实践
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里本地生活全域日志平台 Xlog 的思考与实践相关的知识,希望对你有一定的参考价值。
1. 背景
程序员学习每一门语言都是从打印“hello world”开始的。这个启蒙式的探索,在向我们传递着一个信息:“当你踏进了编程的领域,代码和日志将是你最重要的伙伴”。在代码部分,伴随着越来越强大的idea插件、快捷键,开发同学的编码效率都得到了较大的提升。在日志部分,各个团队也在排查方向进行创新和尝试。这也是研发效能领域重要的组成部分。
阿里集团本地生活,在支撑多生态公司,多技术栈的背景下,逐渐沉淀了一款跨应用、跨域的日志排查方案-Xlog。目前也支持了icbu、本地生活、新零售、盒马、蚂蚁、阿里cto、阿里云、淘特、灵犀互娱等团队。也获得了sls开发团队的点赞。
希望本文可以给正在使用或准备使用sls的同学带来一些输入,帮助团队尽快落地日志排查方案。其中第一部分重点讲了在微服务框架下,日志排查面临了怎样的挑战,以及我们是如何解决的。第二部从细节角度讲了方案设计的几个难点和攻克策略。第三部分讲的是Xlog当前具备的能力。第四部分是在围绕主要能力,如何进行生态能力建设的。
1.1 Xlog解决的问题
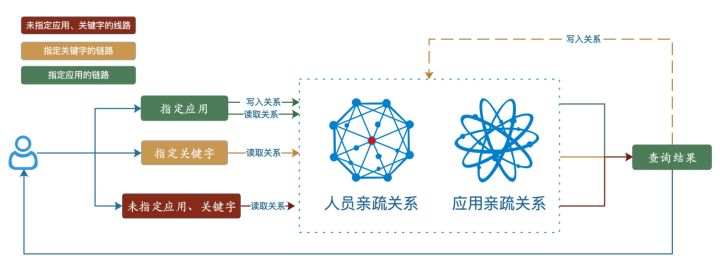
在通过日志进行问题排查的时候,相信有几个步骤大家再熟悉不过:1. 登陆跳板机。 2. 切换跳板机。3. 登陆阿里云平台sls。 4. 切换阿里云sls project logstore。循环往复。
举个例子,下面这张图显示了一个长链路系统的片段(真实链路会复杂更多) :Application1, Application2, Application3。其中Application1与Application2是同一个域(类似于:一个子团队),Application3属于另外一个域。那本次查询就涉及到跨应用查询,跨域查询两个场景。
Application1的负责人接手了该问题后,通过跳板机或者sls日志,发现需要上游同学帮忙协助排查。这个时候无论是切换跳板机还是sls,亦或联系Application2的负责人协助查询,都需要1min->3min的响应时间。如果是从Application2的负责人寻找Application3的负责人将会更难,因为可能不清楚Application3的sls信息(我们bu就有十万级别的logstore信息),又没有跳板机登陆权限,又不知道Application3的负责人。于是排查时间大幅度增加。环境准备的时间(无效排查时间)甚至远大于有效排查的时间。
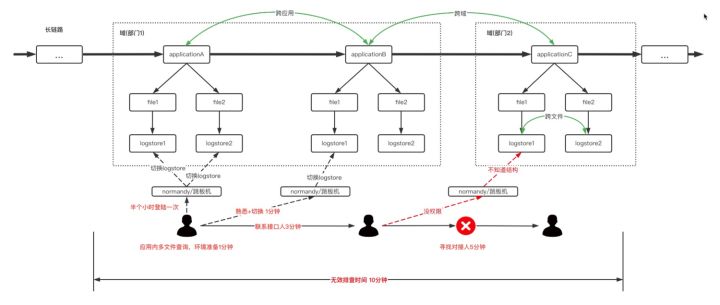
刚才的例子只展示了3个应用的查询场景,往往真实链路要比这个复杂很多很多。所以是不是有一个平台,可以一键式、一站式地查询出需要的日志呢?于是致力于解决长链路下,跨应用和跨域搜素频繁切换的Xlog就诞生了!
1.2 Xlog支持的场景
微服务框架下的跨应用查询,跨域融合背景下的跨域查询。
- 如果你们的团队使用了sls,或者准备将日志采集到sls;
- 如果你们的希望可以拥有更好的日志检索、展示能力;
- 如果你们希望可以跨应用,跨域搜索日志;
本文为大家介绍 xlog,帮助集团内业务构建更大生态的,简便易用无侵入,并且随着越来越多的域接入之后,可以连点成线、并线为面,共同打造一个经济体,或者更大生态的日志全链路方案。
1.3 Xlog当前体系建设
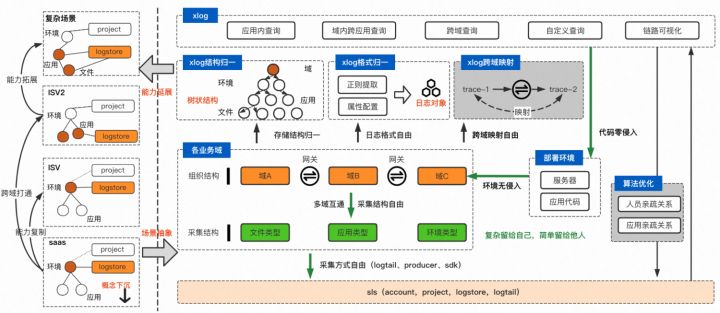
针对已经采集到sls的应用,我们可以做到对代码零改造、对部署环境无侵入,并且采集的结构、采集的渠道都是自由的。基本上,只要已经接入了sls的,就可以接入Xlog了。通过对结构的归一、格式归一、和跨域能力打通,Xlog支持了排查问题最常使用的几个场景:应用内跨文件搜索,域内跨应用搜索,跨域搜索。
《持续交付2.0》的作者乔梁提到:一致性,是研发效能提升必经之路。整个经济体发展20多年,一致性的全量覆盖难如登天,但Xlog创新地提出了一种方案,将不一致转化成一致,无论对查询还是对其他基于日志的技术体系建设,都有里程碑的意义。
2. 方案设计
这个段落将会详细讲述Xlog的设计思想和发展过程,如果是已经接入sls的可以直接跳到2.2;如果当前还未接入sls,可以读2.1 会有一些创新的思路。
2.1 最初的方案:创新与独善其身
2019年saas刚成立,很多基础建设都有待完善,与很多团队一样当时我们查询日志主要通过两种方式:
1. 登陆跳板机查询:使用Traceid->鹰眼->机器ip->登陆跳板机->grep 关键字 的查询链路。缺点:每次查询4-6分钟,日志检索和可视化差,无法跨应用查询,历史日志无法查看。
2. 登陆阿里云sls web控制台查询:登陆sls->关键字查询。缺点:每次查询1-2分钟,日志可视化差,无法跨应用查询,无法跨域查询。
基于这样的背景,我们做了3件事来提升查询效率:
- 日志格式统一: 针对logback中的pattern使用了一套标准。
%dyyyy-MM-dd HH:mm:ss.SSS LOG_LEVEL_PATTERN:-%5pLOG_LEVEL_PATTERN:-%5pPID:- --- [%t] [%XEAGLEEYE_TRACE_ID] %logger-%L : %m%n
其中:
%dyyyy-MM-dd HH:mm:ss.SSS:时间精确到毫秒
$LOG_LEVEL_PATTERN:-%5p:日志级别,DEBUG,INFO,WARN,ERROR等
$PID:- :进程id
---:分隔符无特别意义
[%t]:线程名
[%XEAGLEEYE_TRACE_ID]:鹰眼跟踪id
%logger:日志名称
%m%n:消息体和换行符
一个域内使用相同的日志格式,事实证明这带来的收益远超出预期。对全链路的分析,监控,问题排查,甚至对将来的智能排查都带来极大便利。
- sls结构设计与统一:将域内所有应用的采集格式统一成一套结构,和正则方式提字段,方便采集和配置。在docker的基础镜像里面生命logtail的配置,这样域内所有应用可以继承同样的日志采集信息。
- sls采集结构下沉:这里我们创新的提出了一个概念下沉的理念。并通过这样的方式可以非常便捷的实现跨应用查询。如下图所示,sls结构可以理解为4层:account, project, logstore, logtail。 其中logstore这一层很关键,关系着关系查询的维度。常见的方案是使用一个应用对应一个losgtore,这就导致在多个应用查询的时候,需要频繁切换logstore。因此我们创新的提出了概念下沉的理念。让每一个环境对应一个logstore,这样只需要确定了查询的环境,就能清楚的知道在哪个logstore中查询,从而实现跨应用查询的效果。
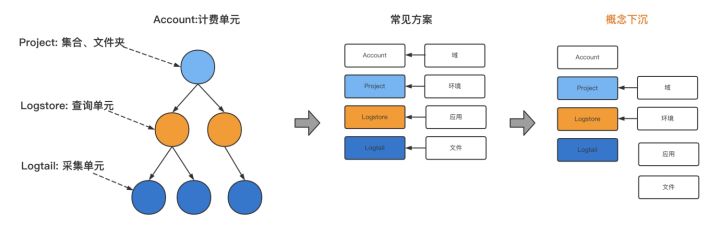
这套方案在解决单应用、域内跨应用有着非常好的性能表现,只需要完成一次api的调用。如果你所在的团队正在准备使用sls,如果sls的数据只用于做排查(监控类的sunfire可以直接读服务器本地日志)我们依然建议采用这样的方案。可以很好的完成排查的需要。同样基于这样几个条件的解决方案已经沉淀到Xlog中,可以直接接入Xlog,从而享有Xlog全套的能力。
2.2 现在的方案:创新与兼济天下
刚才的方案在解决自己域的排查问题的时候有着很好的表现。但2020年,saas开始支撑多个生态公司,面临的场景不再是自己域内的,还需要多个域共同串联。这时我们面临着两大考验:
- 接入成本:我们规定了一套sls采集方式和日志格式,按照这样的形式可以方便的进行数据的采集和高效的查询、展示。但是在其他部门进行接入的时候发现,由于已有系统已经配置了监控、报表等模块,导致日志格式不能修改。由于有些系统之前已经采集到sls导致采集结构也不能修改。这两个信息不一致导致接入成本很大。
- 跨域场景:在系统日趋复杂的情况下,跨域场景也越来越多。拿本地生活的业务场景举例。在入淘的大背景下,部分系统完成淘系迁移,仍有部分系统在蚂蚁域;两个域的打通需要经过网关。在口碑和饿了么深度融合的情况下,互相调用也需要经过网关。目前也在和收购的isv打通,同样需要经过网关。由于各个公司采用的链路追踪方案不通,导致traceid等信息不一致,无法全链路排查。所以如何解决跨域场景日志搜索成为第二大问题。
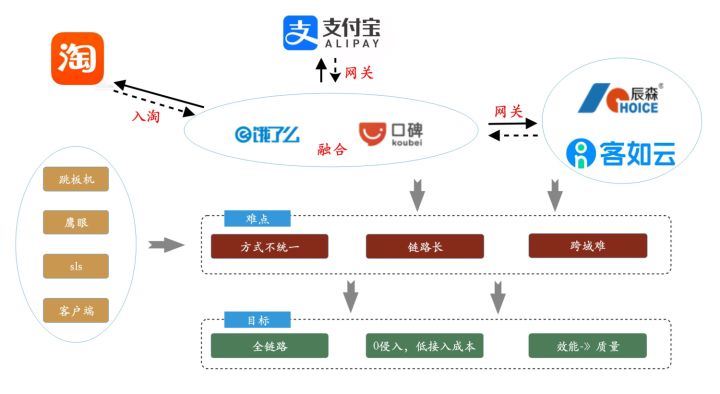
因此,在之前的方案上,我们把Xlog进行了升级,重新定义了目标:
- 核心能力:应用->跨应用->跨域->全域多场景日志排查。从只能查一个应用的日志,到可以在域内查一条链路的日志开启真正全链路日志排查的大门。
- 接入成本方面: 十分钟接入。通过代码逻辑降低对现有日志格式和采集方式的改动。支持logtail、produce、sdk等多种采集方式。
- 侵入性方面:零侵入,对应用代码无侵入,直接与sls交互,实现解耦。
- 自定义方面:支持查询界面自定义,展示结果界面自定义。
2.2.1 模型设计
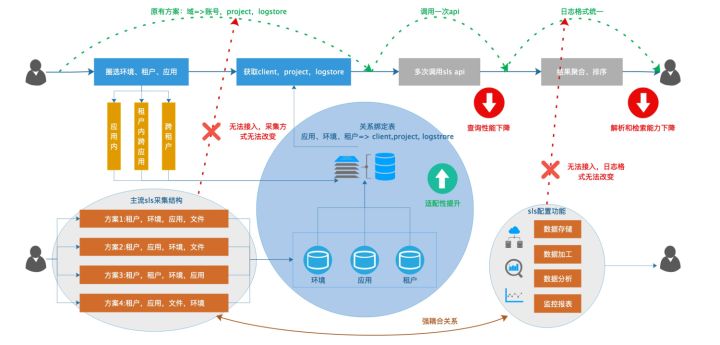
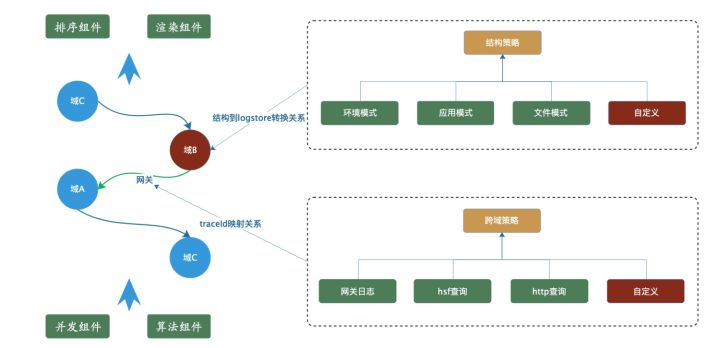
由于调用sls api查询日志的单元是logstore,我们可以将多种多样的采集结构拆结为一下3种单元的组合(当然绝大多数域可能就是其中一种结构)。
1. 一个环境对应一个logstore,(比如:在这个域内,所有应用在日常环境的日志都在一个logstore中)。如下图所展示的域A。
2. 一个应用对应一个logstore,(比如A应用日常环境对应logstore1, A应用预发环境对应logstore2, B应用日常环境对应logstore3)。如下图所展示的域B。
3. 一个文件对应一个logstore,(比如A应用的a文件在日常环境对应logstore1,A应用的b文件在日常环境对应logstore2)。如下图所展示的域C。
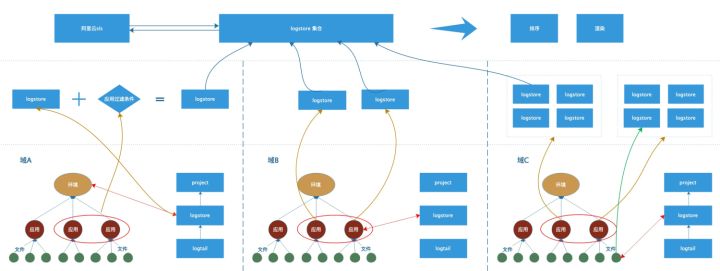
有了这样的原子结构,只需要在xlog上配置的时候,创建好一个域、环境、应用、文件=> logstore的映射关系即可。这样就可以在域内进行应用粒度、文件粒度的查询。
同样在不经过网关跨域场景可以通过组合两个域的logstore 完成跨域的查询。如上图所示:在域A中指定两个应用,可以转换成logstore加过滤条件。在域B中指定两个应用,可以转换成两个logstore。在域C中指定两个应用可以先寻找应用下的文件,然后找到文件对应的logstore 集合。至此就有了需要在阿里云sls查询日志的所有logstore。将查询结果进行组合和排序就可得到最终的结果。同理,如果想进行跨域的搜索,只需要将多个域的logstore进行拼接。然后进行查询即可。
2.2.2 性能优化
通过2.2.1模型设计的讲述,无论是环境类型的、应用类型的还是文件类型的sls结构,以及单应用、多应用、多个域的查询都可以转换成一组logstore,然后遍历执行logstore。但是这样就会引入新的问题,如果logstore很多,如何才能提效。举个例子,在对接某团队日志的时候发现,他们的logstore有3000个,每个环境有1000个应用。假设每次查询需要150ms,1000个应用需要执行150s(2.5分钟)。试想如果不指定应用在全域搜索一次日志都需要2.5分钟,那将是多大的成本。针对这样的问题,我们进行了性能方面的优化。主要采用了以下几个方式,如下图所示:
- Logstore链接池预加载:将logstore进行去重和链接,减少每次查询创建链接的时间。针对活跃度不高的logstore进行降级,惰性加载。
- 多线程并发:针对多个logstore的场景进行并发查询,减少查询时间。
- 算法优先队列:针对查询人员进行亲疏算法优化,精简logstore查询数量,从而减少开销。
- 前端组合排序:后端只做查询操作,排序和查找等操作均在前端完成,减少后端并发压力。
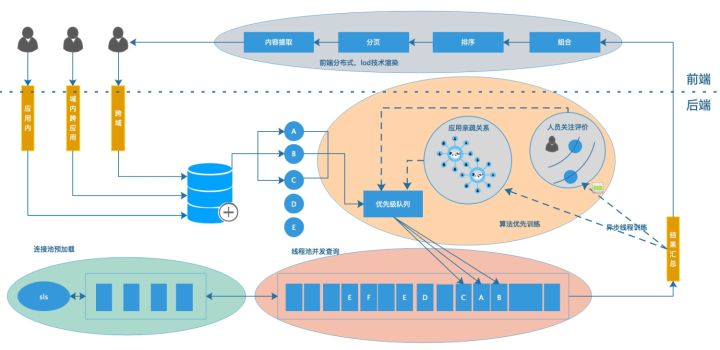
如上图所示,当用户通过前端选择对应的操作域,以及查询条件之后。后端分析获取需要查询的logstore列表(图中A,B,C,D,E所示)。再通过分析用户的亲密应用来进行排序和筛选,从而得到优先级队列(图中B,A,C)。针对优先级队列使用已经创建好的链接池进行并发查询,从而得到一组日志结果。最后由前端完成排序和组装,并渲染出来,完成一个周期。本文主要讲解其中线程池并发和算法优化模块。
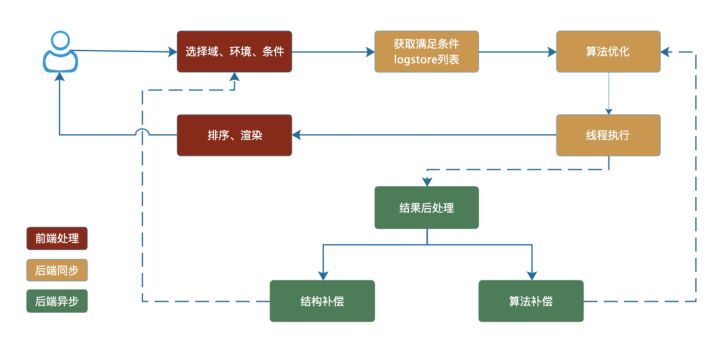
2.2.3 线程池并发
相较于传统的线程池并发执行没有太大差异。将需要查询的logstore,按照顺序插入到线程池队列。通过该手段可以在单次查询logstore数量较小(小于核心线程数)的时候,有效的降低查询时间。针对数量较大的场景,由算法优化进行支持。
针对查询后的补偿操作,也使用异步的处理方式,减少查询耗时。
- 结构后处理:在环境结构的域中,配置过程无需配置应用和文件。这些数据来源于每次查询之后,不断将缺失的数据自动填充进结构的处理操作。针对这些不影响当次查询结果的操作,作为后处理添加到异步线程池中。
- 算法后处理,在处理人员亲疏关系和应用亲疏关系的评分逻辑中,使用的是不断训练的方式。该部分也不影响当次查询的结果,也放到异步线程池中。
2.2.4 算法优化
针对满足条件的logstore较多(超过核心线程数)的场景,通过线程池并发进行查询也不能较快的拿到结果。经过日志快排一年数据的积累和分析,我们发现即便是没有指定应用和搜索条件,也可以通过查询人员的操作习惯或者关注应用习惯,定位到最有可能的logstore序列。
举个例子,在商家saas中心,应用数量有500个左右。同学A负责的系统是 Application1, 查询次数较多的应用还有Application11,Application12。除此之外,与Application1处于紧密上下游关系的应用是Application2,Application3。如果是这样,我们可以认为同学A,对应用Application1,Application11,Application12,Application2,Application3的关注度会高于其他应用。针对这几个应用,可以进行优先查询。从而将的500个查询任务降低成5个。
结合日常生活中的状况,每个开发同学关注的应用数量大概率会控制在30个以内。
通过以上的分析,我们建立了两套亲疏关系网络用于定位查询批次和梯队。
- 人员亲疏关系
当用户每次调用的时候,都可以将查询条件,查询结果和用户进行分析和关系创建。由于查询条件中可以指定应用,也可以不指定应用。
如果是指定应用的,说明用户明确查询该应用内容。将该用户和该应用的亲密度加5分。
如果没有指定应用,根据关键字查询,可以分析查询出的结果。将查询结果的各条日志对应的应用提取出来,然后加1分(由于不是明确指定的,而是根据关键字辐射到的)。
至此,经过多次的用户操作,就可以获取到用户与各个应用的亲密度。当遇到多logstore查询的场景,可以根据用户筛选出与之亲密度最高的15个应用。作为第一批查询对象。
- 应用亲疏关系
应用之间也存在着亲密度关系。亲密度越高的应用,被关联搜索出来的概率就越大。举个例子,center与prod 两个应用在系统设计上就有这紧密的关联关系。如果用户A的亲属关系中包含应用center,那么在其查询日志的时候就有较大概率辐射到应用prod。基于这样的思路,就可以通过分析每次查询日志的结果进行关系矩阵的创建。
在每次获取通过关键字查询的日志结果之后,将涉及到的应用进行两两亲密度加1。相当于在一个链路上的应用亲密度都加1。方便以后查询时不会因为人员亲密度丧失应用亲密度的信息,导致链路失真。
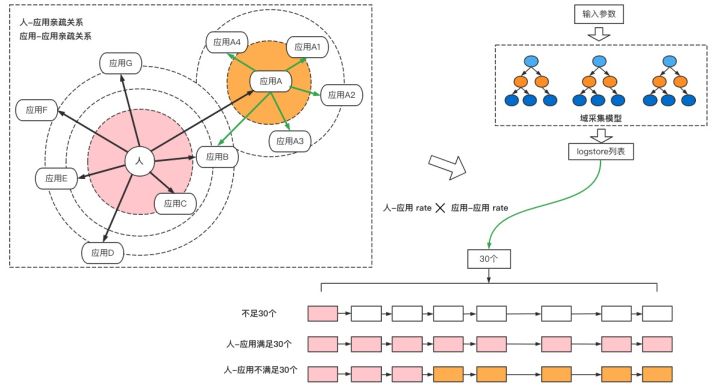
上面大致概括了一下,我们是如何训练亲疏关系矩阵的,下面讲一下如何通过这个矩阵进行查询算法优化的。如下图,左上角是我们记录的人-应用,应用-应用的亲疏关系矩阵。具体来讲,用户和应用A、应用B、应用C等关系,我们会用一个分数度量他们的亲疏关系,主要可以描述人对应用的关注度。在应用-应用之间,我们记录了彼此的耦合度。右上角是查询条件,根据查询条件以及各个域的采集结构,可以快速的计算出需要查询的logstore的列表。但并不是所有的logstore都需要查询,这里会将亲疏关系矩阵和logstore的列表取交集,然后排序进行搜索。
如下图所示,针对交集命中的应用,会先按照人-应用的亲疏关系进行计算,选出分值比较高的。然后不足30个阈值的使用应用-应用的亲疏关系进行补充。这里就涉及到一个比较逻辑,会按照人和应用的比例分值*应用与应用比例的分值,类似于哈夫曼编码中的路径权重的意思。最后得到需要查询的30个logstore的列表。
2.2.5 跨域映射
进行全链路的排查,跨域是必须面对的挑战。在实现原理上讲,跨域有两种场景:经过网关、没有经过网关。
- 不经过网关的场景,如:淘系不同域的互相调用。这个场景其实本质上与域内搜索没有太大区别,这里不多介绍。
- 经过网关的场景,如:淘系与蚂蚁系互相调用,由于每个域使用的链路追踪方案不同,无法使用一个traceId将整个链路串联起来。这里主要讲一下这种场景的处理方式。
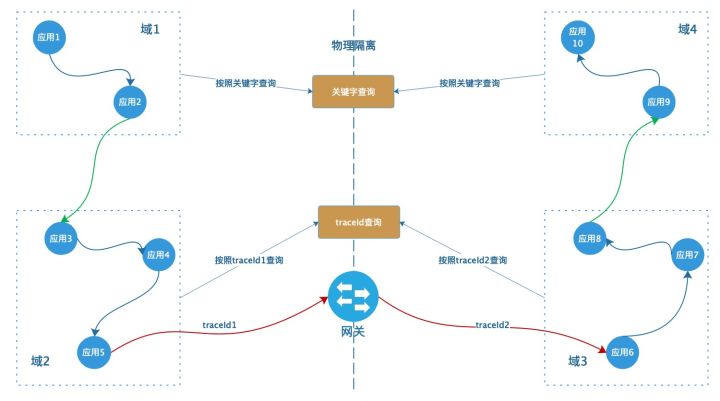
如上图所示,展示了域1,域2,域3,域4的调用链路。其中域1调用域2,域3调用域4不经过网关,traceId不发生改变。在域2调用域3的时候需要经过网关,并且traceId发生改变。
我们可以将查询方式分为两种。1. 关键字查询,比如输入订单号。这种其实并不受链路追踪方案影响,也不受网关影响。所以还是在各个域根据关键字查询即可。2. 通过traceId查询。这种首先需要通过网关信息获取到映射关系。也就是traceId1->traceId2。 然后分别用这两个traceId到各自的域中进行搜索即可。
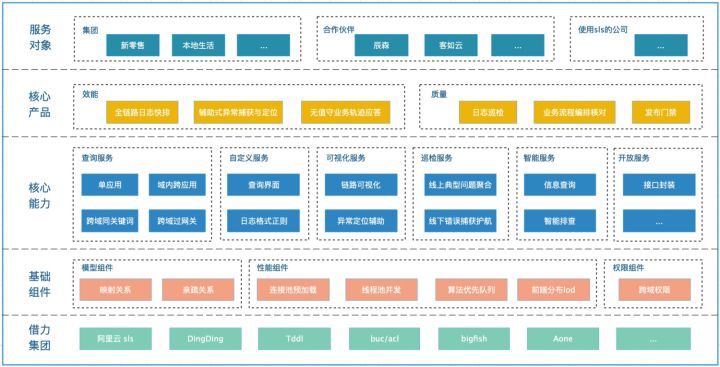
3. 现有能力
通过对原有飞云日志快排功能的完善,以及接入成本的改良。Xlog 已经完成主要功能的开发和实现。链接:Xlog.
跨域查询操作:
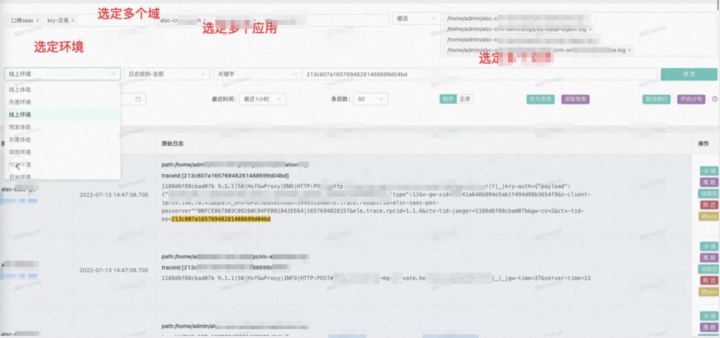
- 多场景覆盖:
通过对用户使用习惯的分析,目前支持了单个应用、域内跨应用、跨域。按照文件,日志等级,关键字,时间等搜索。同时支持用户操作习惯保存。 - 多模式支持:
对阿里云sls采集结构进行支持,只要可以拆解为以上三种模式的采集方式都可以支持,如果极特殊情况可联系 御田进行定制化。 - 零成本接入:
对于已经接入sls的系统,无需改动sls配置,只需在Xlog上进行配置即可。对于sls采集日志保存时间,采集方式,预算等分发到各个业务团队,可根据自己实际情况进行调整。 - 自定义界面:
针对不同的域,可能对一些关键字段的敏感度不同。比如有些需要使用traceid,有些需要使用requestid,游戏需要使用messageid,针对这种场景,支持自定义搜索框,和展示日志的时候对关键字段高亮。 - 性能保障:
通过以上多种手段的性能优化,目前性能指标如下:单个应用查询150ms。32个应用400ms。超过50个应用,进行算法优化,时间在500ms。
4. 生态建设
本章节记录了,在此体系上进行的日志层面的优化和建设。大部分思想和策略是可以复用的,希望可以给相同诉求的同学带来帮助。
4.1 成本优化
Xlog体系搭建完成之后,如何降低成本成为了新的挑战。经过以下方式的落地,成本降低80%。这里也把主要的几个操作列举出来,希望可以给相同在使用sls的用户一些帮助。
- 域外日志直接上传到域内:
阿里云对内部账号相对于外部账号是有额外的优惠的。所以如果有弹外部署的部门,可以考虑把日志直接上传到域内的账号,或者把账号申请成为域内账号。
- 单应用优化:
其实打印日志的时候,往往没有考虑到成本原因,很多都是随手就打了。因此我们给每个应用按照交易量进行了域值设计,超过指标的需要进行优化。
- 存储时间优化:
优化存储时间是最简单,最直接的一个方式。我们将线下(日常和预发)的日志存储降低到了1天,线上的降低到了3天->7天。然后再配合使用归档能力,进行成本的优化。
- 索引优化 :
索引优化相对来说比较复杂,但是也是效果最明显的。经过分析,我们大部分成本开销分布在索引、存储、投递。其中索引占了70%左右。优化索引的操作,其实就是将索引所占的日志比例降低。比如说只支持前多少字节的一个查询能力,后面的详情部分是附属的详细信息。由于我们域内有统一的日志格式,所以在域内的日志中只留了traceid的索引,同时对摘要日志保持了全索引。所以后续的查询方式变成先通过摘要日志查询traceid,再通过traceid查详情。
4.2 归档能力
在搭建整个架构的同时,我们也考虑了成本的因素。在降低成本的时候,我们把存储时间进行了缩短。但是缩短存储时间,必然会导致历史问题的排查能力缺失。所以我们也提出归档能力的建设。
在sls的logstore中,可以配置数据投递:https://help.aliyun.com/document_detail/371924.html。 这一步操作其实是讲sls中的信息,存储到oss。通俗的讲,就是把数据库的表格,用文件的形式保存下来,删掉索引的能力。在投递过程中会进行加密,目前Xlog支持了在界面上进行下载归档的日志,然后在本地进行搜索。
后续可以按需将oss数据重新导入到sls,参考:https://help.aliyun.com/document_detail/147923.html。
4.3 异常日志扫描
借助于之前的架构,其实可以很清晰的知道每条日志的内容部分是哪里,也可以精准的查询出记录了error日志的文件内容。所以每10分钟巡检一次,将每个应用中的异常日志聚合起来,就可以获取到这段时间异常信息的数量。然后在于之前的比较就可以知道,是不是有新增的错误,暴增的错误等等。
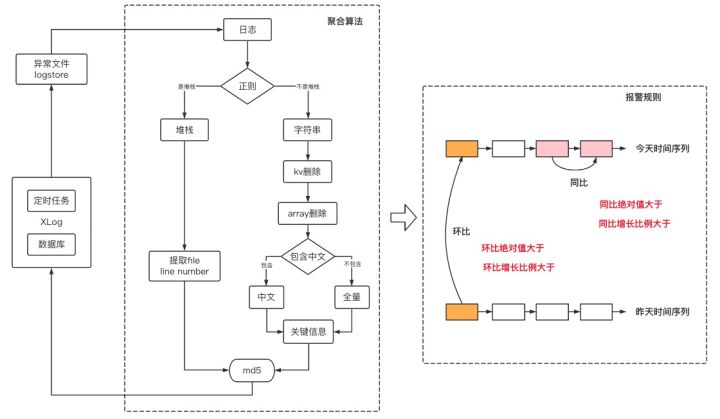
如上图所示,拿到所有异常日志后,会按照一个规则进行md5的计算。堆栈类的和异常日志类的,针对两类的算法不同,但是本质目标是一样的就是取其中最有可能重读的段落计算md5,然后进行聚类。聚类完成之后,就可以获取差异,进行比较,从而判断是不是新增或者暴增。
5. 规划
目前Xlog的基础组件和功能已经实现完毕。在各个应用和域的接入中,整个链路将会越来越全。接下来将向全链路,可视化排查、智能排查和问题发现方面进行补充。
- 异常定位辅助:在可视化链路上,将含有异常的应用标红,方便快速查到错误日志。
- 线上典型问题聚合:日志巡检。
- 线下错误捕获护航:在业务测试的时候经常不会实时的查看日志中的错误信息,开启护航模式,将舰艇应用错误,一旦线下执行过程中出现,将会推送。
- 信息查询:与钉钉打通,用于快捷查询。钉钉@机器人,发送关键字,钉钉将最近执行结果返回。
- 智能排查:@钉钉输入traceid,订单号等,返回检测到的异常应用和异常栈。
业务流程编排核对:允许应用日志流程编排,根据关键字串联的链路流程日志需要满足一定规则。用此规则进- 核对。=>针对实时性要求不高,仅对流程进行验证。 - 发布门禁:线下用例回放无业务异常,线上安全生产无业务异常=> 允许发布
6. 使用与共建
参考很多其他团队的采集结构、日志形式、查询方式、展示样式的要求,在接入成本上降低和自定义方面进行了提升。针对已经满足条件的团队,可以方便的接入。
针对还有一些特殊,或者定制化的需求,Xlog进行了拓展模块的预留,方便共建。
如上图,图中绿色组件均可复用,只需要针对自己的域进行结构自定义和跨域映射自定义即可。只需要根据定义好的策略模式的接口进行实现即可。
作者:王宇(御田)
本文为阿里云原创内容,未经允许不得转载。
以上是关于阿里本地生活全域日志平台 Xlog 的思考与实践的主要内容,如果未能解决你的问题,请参考以下文章