决策树算法之分类回归树 CART(Classification and Regression Trees)
Posted 程序员在深圳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树算法之分类回归树 CART(Classification and Regression Trees)相关的知识,希望对你有一定的参考价值。
分类回归树 CART 是决策树家族中的基础算法,它非常直觉(intuitive),但看网上的文章,很少能把它讲的通俗易懂(也许是我理解能力不够),幸运的是,我在 Youtube 上看到了这个视频(http://1t.click/aMGq),可以让你在没有任何机器学习基础的情况下掌握 CART 的原理,下面我尝试着把它写出来,以加深印象.
决策树的结构
下图是一个简单的决策树示例:
假设上面这个决策树是一个用来判断病人是否患有心脏病的系统,当病人前来就医时,系统首先会问他:血液循环是否正常?此时如果病人回答是,系统会走左边的分支,并继续问:血管是否不堵塞?如果此时病人回答是,系统便会判断该病人没有患心脏病,反之则会判断他患有心脏病。同理,如果病人的第一个问题的回答是否,则决策树会走到右边的分支,接下来会继续后面的提问,直到来到树的根部,以输出结果。
可见,决策树是一个二叉树结构的模型,它可以被用来解决分类问题或回归问题,该树的非叶子节点本质上是一些条件表达式,用来决定树根到叶子的路径,而叶子节点便是该模型的预测结果。
本文主要介绍如何构建一棵分类树:
如何构建一棵分类树
在构造这棵“判断心脏病的决策树”之前,我们有一堆病人的诊断数据,如下
| 胸口疼痛 | 血液循环正常 | 血管堵塞 | 患有心脏病 |
|---|---|---|---|
| 否 | 否 | 否 | 否 |
| 是 | 是 | 是 | 是 |
| 是 | 是 | 否 | 否 |
| ... | ... | ... | ... |
刚开始,我们可以使用「胸口疼痛」或者「血液循环正常」或者「血管堵塞」这三个特征中的一个来作为树根,但这样做会存在一个问题:任何上述特征都无法将是否患有心脏病分类得完全正确,如下:
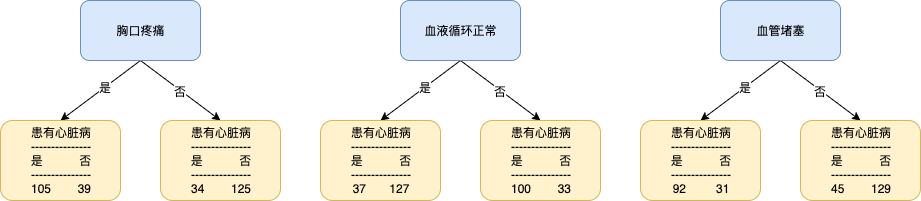
既然没有绝对最优的答案,我们一般会选择一个相对最优的答案,即在这 3 个特征中选择一个相对最好的特征作为树根,如何衡量它们的分类好坏呢?我们可以使用不纯度(impurity)这个指标来度量,例如下图中,P1(蓝色概率分布)相对于 P2(橙色概率分布) 来说就是不纯的。对于一个节点的分类结果来说(上图黄色节点),当然希望它的分布越纯越好。
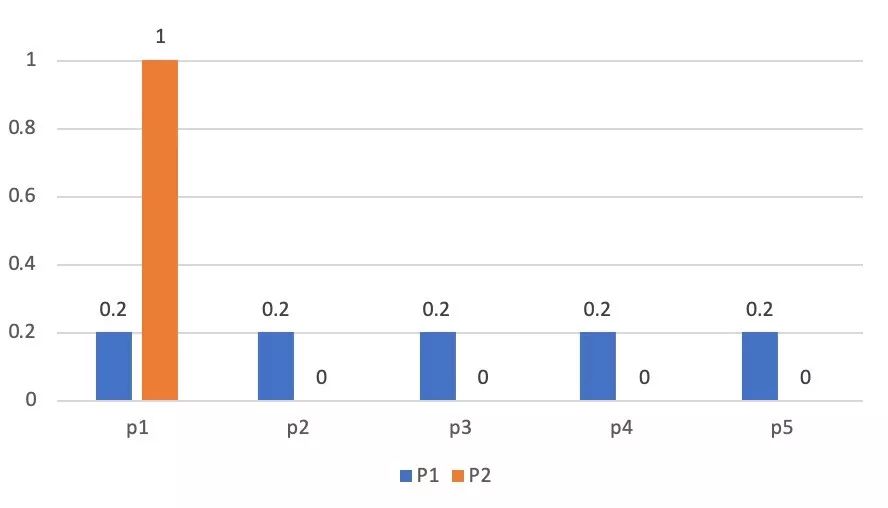
计算一个分布的不纯度有很多方法,这里使用的是基尼系数(Gini coefficient)——基尼系数越高,越不纯,反之越纯。计算基尼系数的公式很简单:
这里 表示离散概率分布中的概率值,我们来算一下上图中 P1 和 P2 的基尼系数
可见 P1 的基尼系数更高,其更不纯。
有了以上基础,接下来我们就可以依次计算不同特征分类的基尼不纯度,从中选一个值最低的特征来作为树根,以「胸口疼痛」特征为例,其左边和右边的分类结果的基尼不纯度为:
那么,「胸口疼痛」这个节点整体的不纯度则为左右两个不纯度的加权平均,如下:
同理,我们也可以计算出「血液循环正常」和「血管堵塞」的基尼不纯度分别为 0.360 和 0.381。相比之下,「血液循环正常」的值最小,该特征便是我们的树根。
在选出了树根后,原来的一份数据被树根分成了两份,后续要做的事情相信很多同学已经猜到了:对于新产生的两份数据,每份数据再使用同样的方法,使用剩下的特征来产生非叶子节点,如此递归下去,直到满足下面两个条件中的任意一条:
-
每条路径上所有特征都使用过 -
使用新特征没有使分类结果更好(此时不产生新的节点)
上述第 1 个条件很容易理解,我们一起来看下第 2 个条件,假设在建树的过程中,其中一条路径如下:
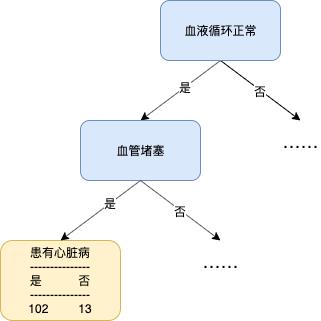
现在我们需要决定黄色的这部分数据是否还需要被「胸口疼痛」这个特征分类,假设用「胸口疼痛」来分类该数据的结果如下:
接下来我们就要对分类前后做效果对比,依然计算它们的基尼不纯度,在分类前,基尼不纯度为:
而使用「胸口疼痛」分类之后,基尼不纯度为(省去计算细节):
显然继续分类只会使结果更糟,所以该分支的建立提前结束了,且分支上只有「血液循环正常」和「血管堵塞」这两个特征来进行分类。
值得一提的是,在建树过程中,即便候选节点的基尼不纯度更低,但如果该指标的降低不能超过一定的阈值,也不建议继续加节点,这种做法可以在一定程度上缓解过拟合的问题。例如:假设该阈值设定为0.05,即便 G(胸口疼痛) 为 0.16,也不继续将「胸口疼痛」作为该分支上的一个节点用来分类,因为此时基尼不纯度只降低了 0.04,低于阈值 0.05。
如何处理离散型数据
上面例子中的数据是只有 0 或者 1 的布尔类型的数据,如果遇到其他类型的数据该怎么处理呢?先来看一下离散型数据,这种类型的数据需要考虑 2 种情况:
-
有顺序的离散型数据,例如电商网站把商品的评论分为:好评、中评和差评 -
顺序无关的离散型数据,例如商品可能的颜色有:红色、黄色和蓝色
有顺序的离散型数据
假如我们有以下数据,它根据用户对商品的评价来判断用户是否喜欢该商品,其中,对商品的评价被编码为 1(差评)、2(中评) 和 3(好评):
| 商品评价 | 是否喜欢 |
|---|---|
| 1 | 0 |
| 3 | 1 |
| 2 | 1 |
| 2 | 0 |
| 3 | 1 |
| 1 | 1 |
| 3 | 0 |
以上问题实际上等价于选择一个评价值,它能够更好的把人们的喜好分开,这个值可以是 1 或者 2,即当商品评价“小于等于1”或者“小于等于2”时,判断用户不喜欢它,否则为喜欢它,这里没有“小于等于3”这个选项,因为该选项会包含所有的数据,没有分类价值;于是,根据上述两个选项,我们可以对数据做如下 2 种分类:
接下来分别计算它们的基尼不纯度,其中左边的结果 G(1) = 0.486,而右边 G(2) = 0.476;于是,当使用「商品评价」这个特征来做分类时,该特征的切分点(cutoff)为“小于等于2”。
顺序无关的离散型数据
我们再来看一个根据商品的颜色来判断用户是否喜欢该商品的例子,有如下数据:
| 商品颜色 | 是否喜欢 |
|---|---|
| RED | 1 |
| YELLOW | 1 |
| BLUE | 0 |
| YELLOW | 1 |
| BLUE | 1 |
| RED | 0 |
对于以上数据,其作为节点的判断条件有以下 6 种可能:
-
红色表示喜欢 -
黄色表示喜欢 -
蓝色表示喜欢 -
红色或黄色表示喜欢 -
红色或蓝色表示喜欢 -
黄色或蓝色表示喜欢
类似的,我们对每一种可能的分类结果计算其基尼不纯度,然后再选择最低的那个值对应的条件。
如何处理连续型数据
最后我们再来看看特征是连续型数据的情况,例如我们通过人的身高来判断是否患有心脏病,数据如下:
| 身高 | 患有心脏病 |
|---|---|
| 220 | 1 |
| 180 | 1 |
| 225 | 1 |
| 155 | 0 |
| 190 | 0 |
处理这类数据的思路和上面几种做法一致,也就是寻找一个使基尼不纯度最低的 cutoff。具体步骤是,先对身高进行排序,然后求相邻两个数据之间的平均值,以每个平均值作为分界点,对目标数据进行分类,并计算它们的基尼不纯度,如下:
| 身高 | 相邻平均值 | 基尼不纯度 |
|---|---|---|
| 225 | ||
| 222.5 | 0.4 | |
| 220 | ||
| 205 | 0.27 | |
| 190 | ||
| 185 | 0.47 | |
| 180 | ||
| 167.5 | 0.3 | |
| 155 |
所以,在使用「身高」来建树时,其切分点为 205,即”小于205”被判断为未患心脏病,而”不小于205“的会被诊断为患病。
总结
本文主要介绍了 CART 中的分类树的构建算法原理,及遇到了不同类型的数据时,该算法会如何处理,当然这并不是分类树的全部,因为决策树容易导致过拟合的原因,在建树之后,往往会伴随着”剪枝“的操作,这些内容以及回归树部分会放在后面再做介绍。
参考:StatQuest: Decision Trees(http://1t.click/aMGq)
以上是关于决策树算法之分类回归树 CART(Classification and Regression Trees)的主要内容,如果未能解决你的问题,请参考以下文章